Collecting stable-baselines
Downloading stable_baselines-2.10.2-py3-none-any.whl (240 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━240.9/240.9 kB2.2 MB/s eta 0:00:00a 0:00:01
Collecting gym[atari,classic_control]>=0.11 (from stable-baselines)
Downloading gym-0.26.2.tar.gz (721 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━721.7/721.7 kB1.5 MB/s eta 0:00:0000:0100:01
Installing build dependencies ... done
Getting requirements to build wheel ... done
Preparing metadata (pyproject.toml) ... done
Requirement already satisfied: scipy in /Users/nipun/mambaforge/lib/python3.10/site-packages (from stable-baselines) (1.10.1)
Requirement already satisfied: joblib in /Users/nipun/mambaforge/lib/python3.10/site-packages (from stable-baselines) (1.3.2)
Requirement already satisfied: cloudpickle>=0.5.5 in /Users/nipun/mambaforge/lib/python3.10/site-packages (from stable-baselines) (3.0.0)
Collecting opencv-python (from stable-baselines)
Downloading opencv_python-4.9.0.80-cp37-abi3-macosx_11_0_arm64.whl (35.4 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━35.4/35.4 MB5.7 MB/s eta 0:00:0000:0100:01
Requirement already satisfied: numpy in /Users/nipun/mambaforge/lib/python3.10/site-packages (from stable-baselines) (1.24.3)
Requirement already satisfied: pandas in /Users/nipun/mambaforge/lib/python3.10/site-packages (from stable-baselines) (2.0.1)
Requirement already satisfied: matplotlib in /Users/nipun/mambaforge/lib/python3.10/site-packages (from stable-baselines) (3.7.1)
Collecting gym-notices>=0.0.4 (from gym[atari,classic_control]>=0.11->stable-baselines)
Downloading gym_notices-0.0.8-py3-none-any.whl (3.0 kB)
Collecting ale-py~=0.8.0 (from gym[atari,classic_control]>=0.11->stable-baselines)
Downloading ale_py-0.8.1-cp310-cp310-macosx_11_0_arm64.whl (1.0 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━1.0/1.0 MB5.5 MB/s eta 0:00:0000:0100:01
Collecting pygame==2.1.0 (from gym[atari,classic_control]>=0.11->stable-baselines)
Downloading pygame-2.1.0-cp310-cp310-macosx_11_0_arm64.whl (4.8 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━4.8/4.8 MB4.4 MB/s eta 0:00:0000:0100:01
Requirement already satisfied: contourpy>=1.0.1 in /Users/nipun/mambaforge/lib/python3.10/site-packages (from matplotlib->stable-baselines) (1.0.7)
Requirement already satisfied: cycler>=0.10 in /Users/nipun/mambaforge/lib/python3.10/site-packages (from matplotlib->stable-baselines) (0.11.0)
Requirement already satisfied: fonttools>=4.22.0 in /Users/nipun/mambaforge/lib/python3.10/site-packages (from matplotlib->stable-baselines) (4.39.4)
Requirement already satisfied: kiwisolver>=1.0.1 in /Users/nipun/mambaforge/lib/python3.10/site-packages (from matplotlib->stable-baselines) (1.4.4)
Requirement already satisfied: packaging>=20.0 in /Users/nipun/mambaforge/lib/python3.10/site-packages (from matplotlib->stable-baselines) (23.1)
Requirement already satisfied: pillow>=6.2.0 in /Users/nipun/mambaforge/lib/python3.10/site-packages (from matplotlib->stable-baselines) (9.5.0)
Requirement already satisfied: pyparsing>=2.3.1 in /Users/nipun/mambaforge/lib/python3.10/site-packages (from matplotlib->stable-baselines) (3.0.9)
Requirement already satisfied: python-dateutil>=2.7 in /Users/nipun/mambaforge/lib/python3.10/site-packages (from matplotlib->stable-baselines) (2.8.2)
Requirement already satisfied: pytz>=2020.1 in /Users/nipun/mambaforge/lib/python3.10/site-packages (from pandas->stable-baselines) (2023.3)
Requirement already satisfied: tzdata>=2022.1 in /Users/nipun/mambaforge/lib/python3.10/site-packages (from pandas->stable-baselines) (2023.3)
Requirement already satisfied: importlib-resources in /Users/nipun/mambaforge/lib/python3.10/site-packages (from ale-py~=0.8.0->gym[atari,classic_control]>=0.11->stable-baselines) (5.12.0)
Requirement already satisfied: typing-extensions in /Users/nipun/mambaforge/lib/python3.10/site-packages (from ale-py~=0.8.0->gym[atari,classic_control]>=0.11->stable-baselines) (4.5.0)
Requirement already satisfied: six>=1.5 in /Users/nipun/mambaforge/lib/python3.10/site-packages (from python-dateutil>=2.7->matplotlib->stable-baselines) (1.16.0)
Building wheels for collected packages: gym
Building wheel for gym (pyproject.toml) ... done
Created wheel for gym: filename=gym-0.26.2-py3-none-any.whl size=827621 sha256=42d82791c287db865f66ed914f24b5b3d62e1a142c3b83c9c21d877545b9385b
Stored in directory: /Users/nipun/Library/Caches/pip/wheels/b9/22/6d/3e7b32d98451b4cd9d12417052affbeeeea012955d437da1da
Successfully built gym
Installing collected packages: gym-notices, pygame, opencv-python, gym, ale-py, stable-baselines
Attempting uninstall: pygame
Found existing installation: pygame 2.5.2
Uninstalling pygame-2.5.2:
Successfully uninstalled pygame-2.5.2
Successfully installed ale-py-0.8.1 gym-0.26.2 gym-notices-0.0.8 opencv-python-4.9.0.80 pygame-2.1.0 stable-baselines-2.10.2
Note: you may need to restart the kernel to use updated packages.
import gymnasium as gymimport mathimport randomenv = gym.make("CartPole-v1")# set up matplotlibis_ipython ='inline'in matplotlib.get_backend()if is_ipython:from IPython import displayplt.ion()# if GPU is to be useddevice = torch.device("cuda"if torch.cuda.is_available() else"cpu")
class DQN(nn.Module):def__init__(self, n_observations, n_actions):super(DQN, self).__init__()self.layer1 = nn.Linear(n_observations, 128)self.layer2 = nn.Linear(128, 128)self.layer3 = nn.Linear(128, n_actions)# Called with either one element to determine next action, or a batch# during optimization. Returns tensor([[left0exp,right0exp]...]).def forward(self, x): x = F.relu(self.layer1(x)) x = F.relu(self.layer2(x))returnself.layer3(x)
env = gym.make('MountainCar-v0')
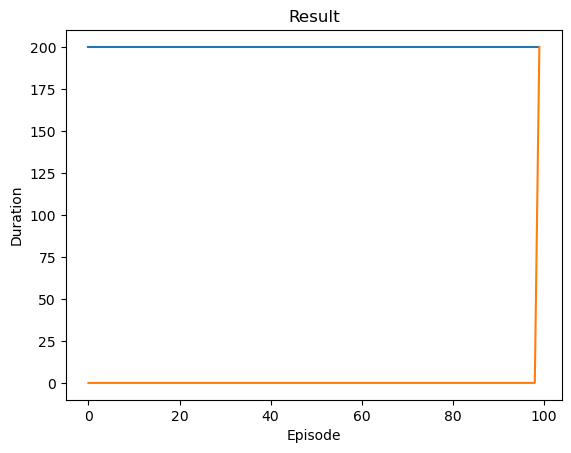
# BATCH_SIZE is the number of transitions sampled from the replay buffer# GAMMA is the discount factor as mentioned in the previous section# EPS_START is the starting value of epsilon# EPS_END is the final value of epsilon# EPS_DECAY controls the rate of exponential decay of epsilon, higher means a slower decay# TAU is the update rate of the target network# LR is the learning rate of the ``AdamW`` optimizerBATCH_SIZE =128GAMMA =0.99EPS_START =0.9EPS_END =0.05EPS_DECAY =1000TAU =0.005LR =1e-4# Get number of actions from gym action spacen_actions = env.action_space.n# Get the number of state observationsstate, info = env.reset()n_observations =len(state)policy_net = DQN(n_observations, n_actions).to(device)target_net = DQN(n_observations, n_actions).to(device)target_net.load_state_dict(policy_net.state_dict())optimizer = optim.AdamW(policy_net.parameters(), lr=LR, amsgrad=True)memory = ReplayMemory(20000)steps_done =0def select_action(state):global steps_done sample = random.random() eps_threshold = EPS_END + (EPS_START - EPS_END) *\ math.exp(-1.* steps_done / EPS_DECAY) steps_done +=1if sample > eps_threshold:with torch.no_grad():# t.max(1) will return the largest column value of each row.# second column on max result is index of where max element was# found, so we pick action with the larger expected reward.return policy_net(state).max(1).indices.view(1, 1)else:return torch.tensor([[env.action_space.sample()]], device=device, dtype=torch.long)episode_durations = []def plot_durations(show_result=False): plt.figure(1) durations_t = torch.tensor(episode_durations, dtype=torch.float)if show_result: plt.title('Result')else: plt.clf() plt.title('Training...') plt.xlabel('Episode') plt.ylabel('Duration') plt.plot(durations_t.numpy())# Take 100 episode averages and plot them tooiflen(durations_t) >=100: means = durations_t.unfold(0, 100, 1).mean(1).view(-1) means = torch.cat((torch.zeros(99), means)) plt.plot(means.numpy()) plt.pause(0.001) # pause a bit so that plots are updatedif is_ipython:ifnot show_result: display.display(plt.gcf()) display.clear_output(wait=True)else: display.display(plt.gcf())
def optimize_model():iflen(memory) < BATCH_SIZE:return transitions = memory.sample(BATCH_SIZE)# Transpose the batch (see https://stackoverflow.com/a/19343/3343043 for# detailed explanation). This converts batch-array of Transitions# to Transition of batch-arrays. batch = Transition(*zip(*transitions))# Compute a mask of non-final states and concatenate the batch elements# (a final state would've been the one after which simulation ended) non_final_mask = torch.tensor(tuple(map(lambda s: s isnotNone, batch.next_state)), device=device, dtype=torch.bool) non_final_next_states = torch.cat([s for s in batch.next_stateif s isnotNone]) state_batch = torch.cat(batch.state) action_batch = torch.cat(batch.action) reward_batch = torch.cat(batch.reward)# Compute Q(s_t, a) - the model computes Q(s_t), then we select the# columns of actions taken. These are the actions which would've been taken# for each batch state according to policy_net state_action_values = policy_net(state_batch).gather(1, action_batch)# Compute V(s_{t+1}) for all next states.# Expected values of actions for non_final_next_states are computed based# on the "older" target_net; selecting their best reward with max(1).values# This is merged based on the mask, such that we'll have either the expected# state value or 0 in case the state was final. next_state_values = torch.zeros(BATCH_SIZE, device=device)with torch.no_grad(): next_state_values[non_final_mask] = target_net(non_final_next_states).max(1).values# Compute the expected Q values expected_state_action_values = (next_state_values * GAMMA) + reward_batch# Compute Huber loss criterion = nn.SmoothL1Loss() loss = criterion(state_action_values, expected_state_action_values.unsqueeze(1))# Optimize the model optimizer.zero_grad() loss.backward()# In-place gradient clipping torch.nn.utils.clip_grad_value_(policy_net.parameters(), 100) optimizer.step()
if torch.cuda.is_available(): num_episodes =600else: num_episodes =100for i_episode inrange(num_episodes):# Initialize the environment and get its state state, info = env.reset() state = torch.tensor(state, dtype=torch.float32, device=device).unsqueeze(0)for t in count(): action = select_action(state) observation, reward, terminated, truncated, _ = env.step(action.item()) reward = torch.tensor([reward], device=device) done = terminated or truncatedif terminated: next_state =Noneelse: next_state = torch.tensor(observation, dtype=torch.float32, device=device).unsqueeze(0)# Store the transition in memory memory.push(state, action, next_state, reward)# Move to the next state state = next_state# Perform one step of the optimization (on the policy network) optimize_model()# Soft update of the target network's weights# θ′ ← τ θ + (1 −τ )θ′ target_net_state_dict = target_net.state_dict() policy_net_state_dict = policy_net.state_dict()for key in policy_net_state_dict: target_net_state_dict[key] = policy_net_state_dict[key]*TAU + target_net_state_dict[key]*(1-TAU) target_net.load_state_dict(target_net_state_dict)if done: episode_durations.append(t +1) plot_durations()breakprint('Complete')plot_durations(show_result=True)plt.ioff()plt.show()