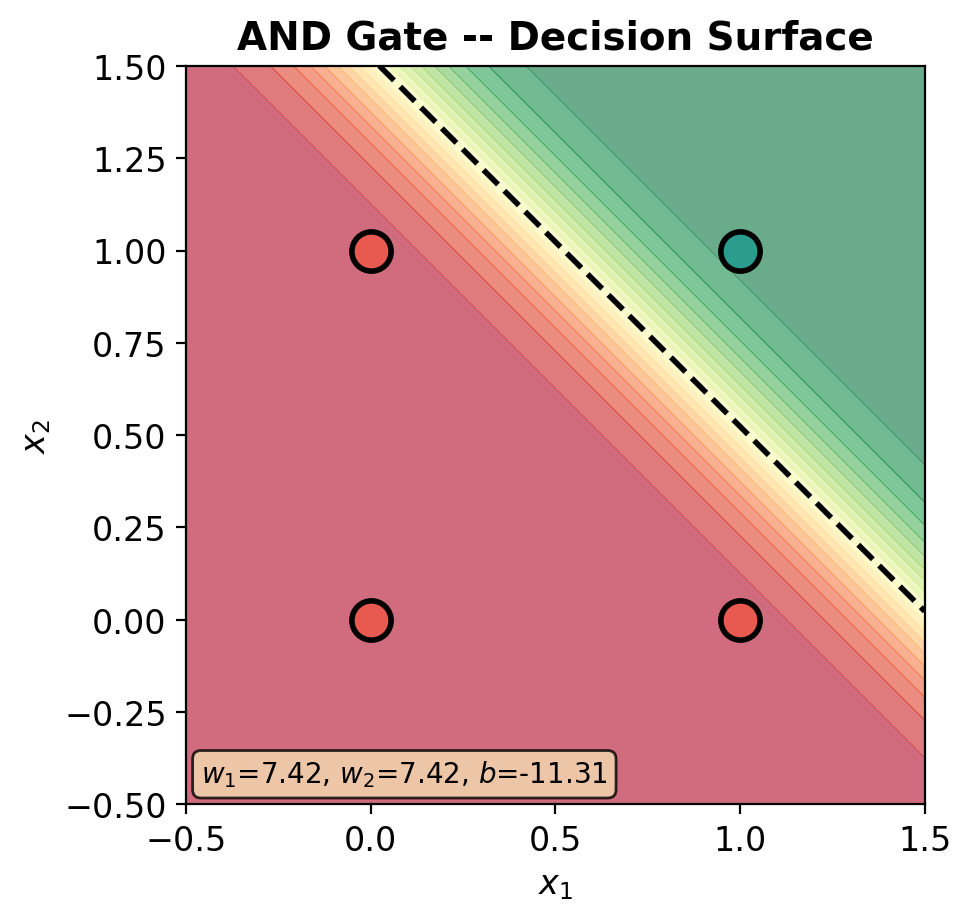
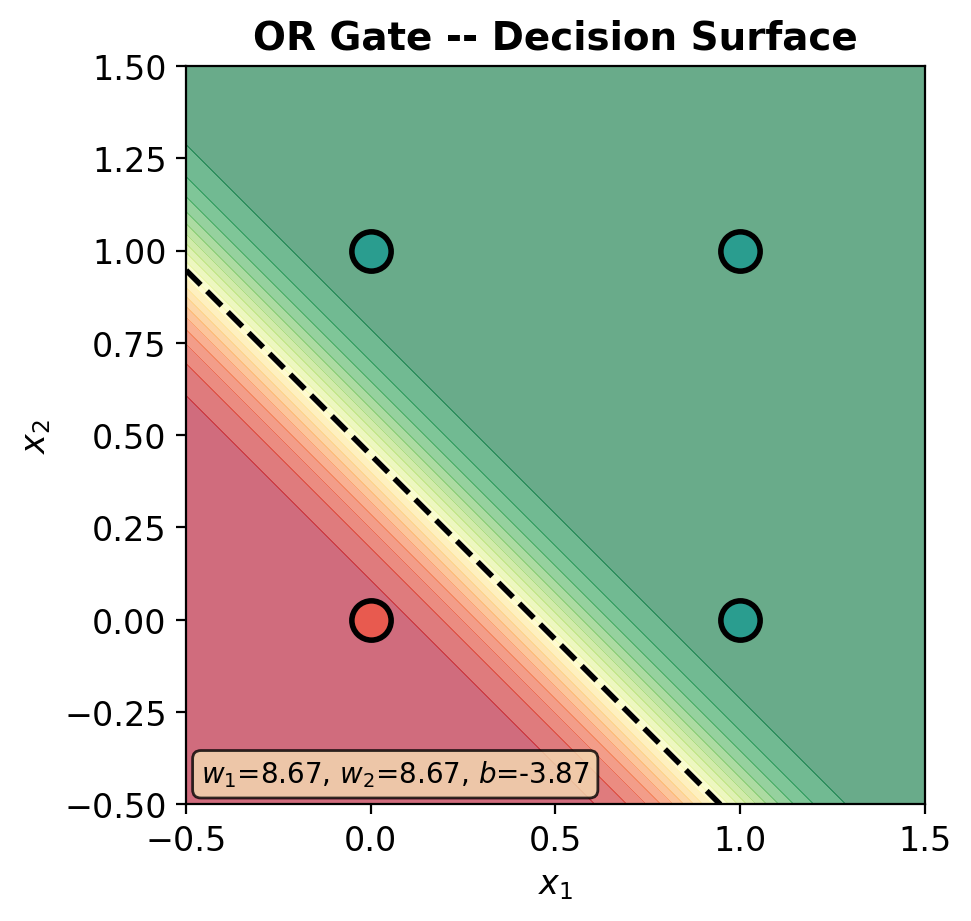
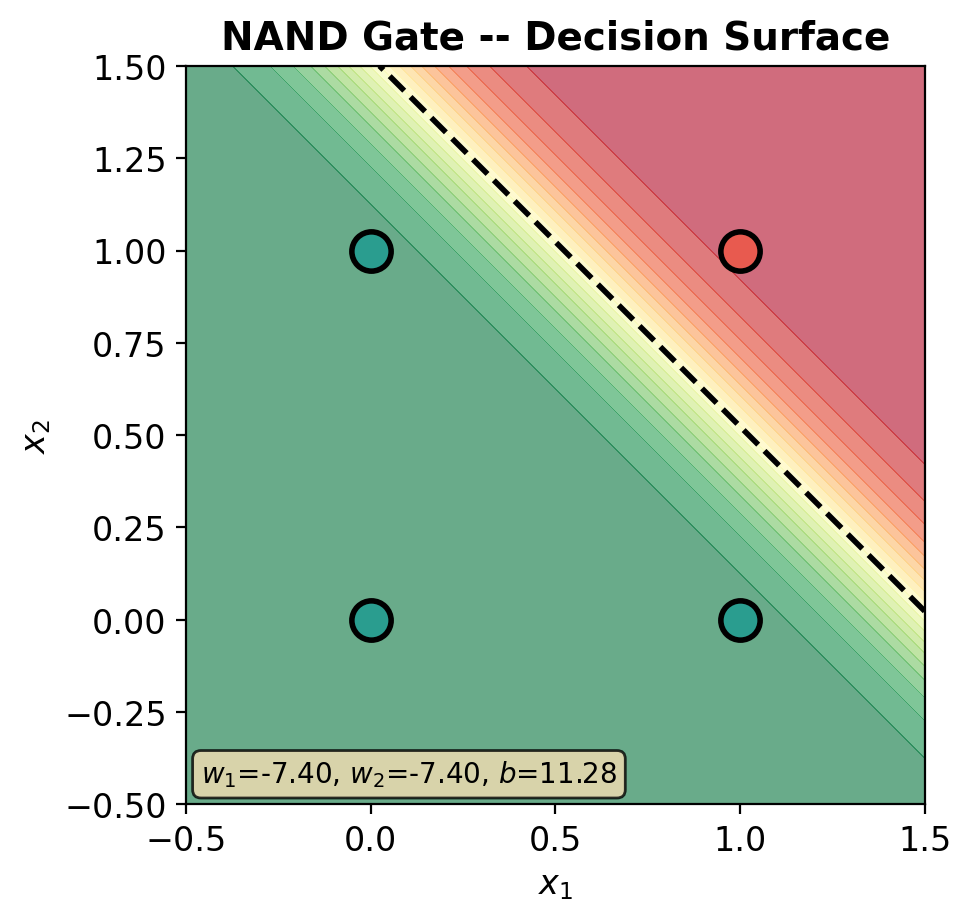
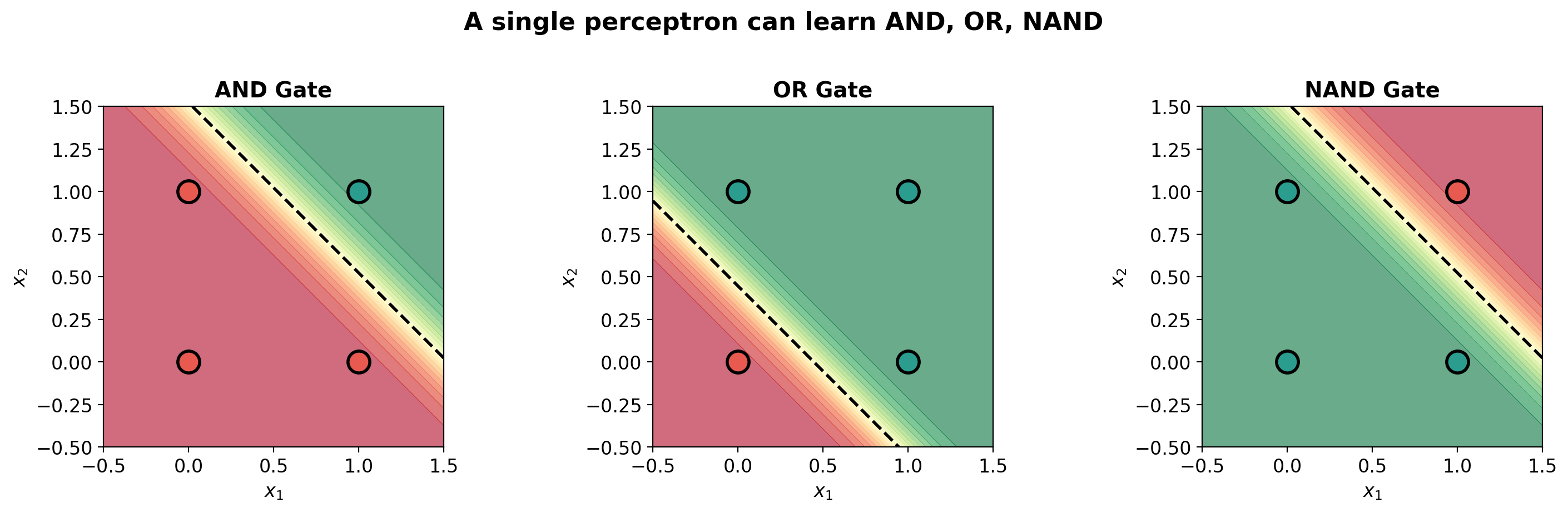
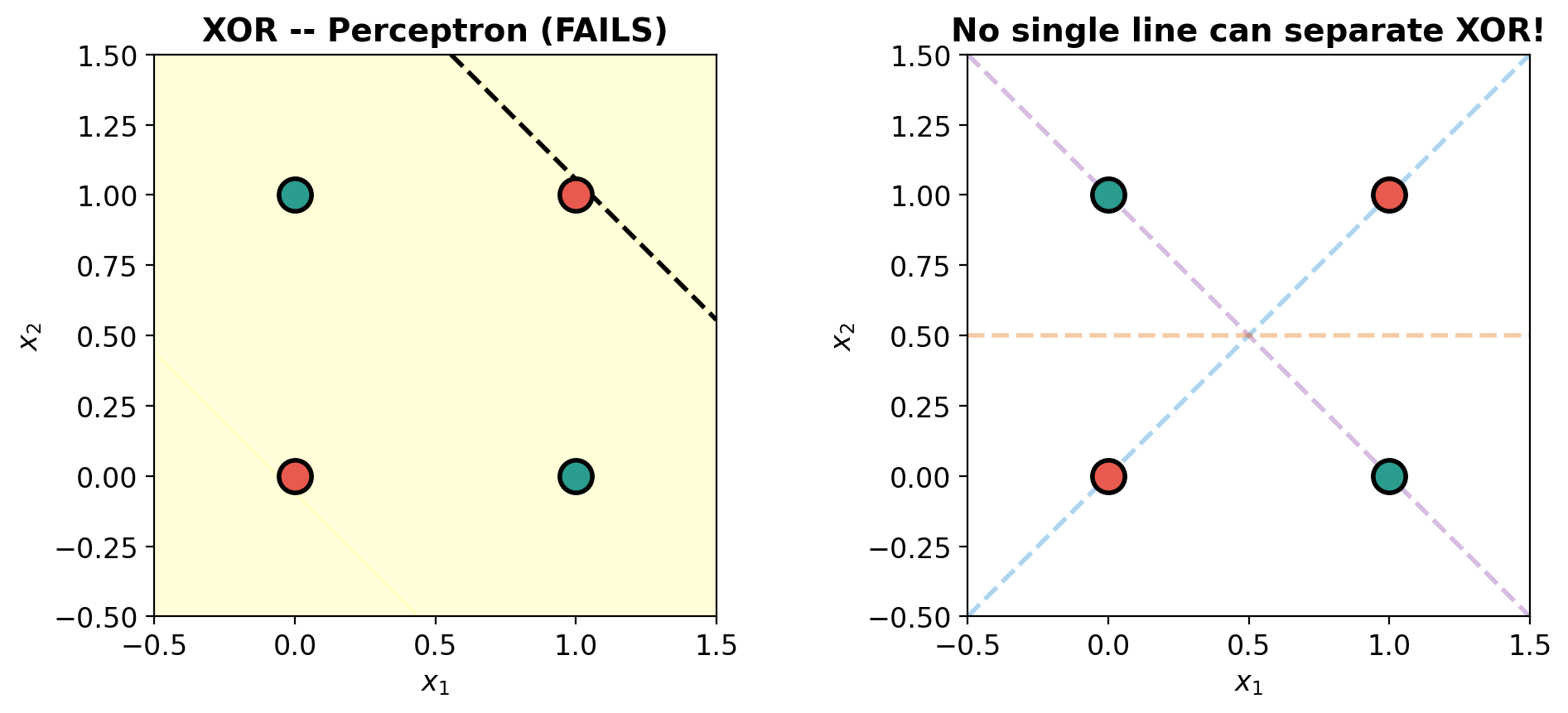
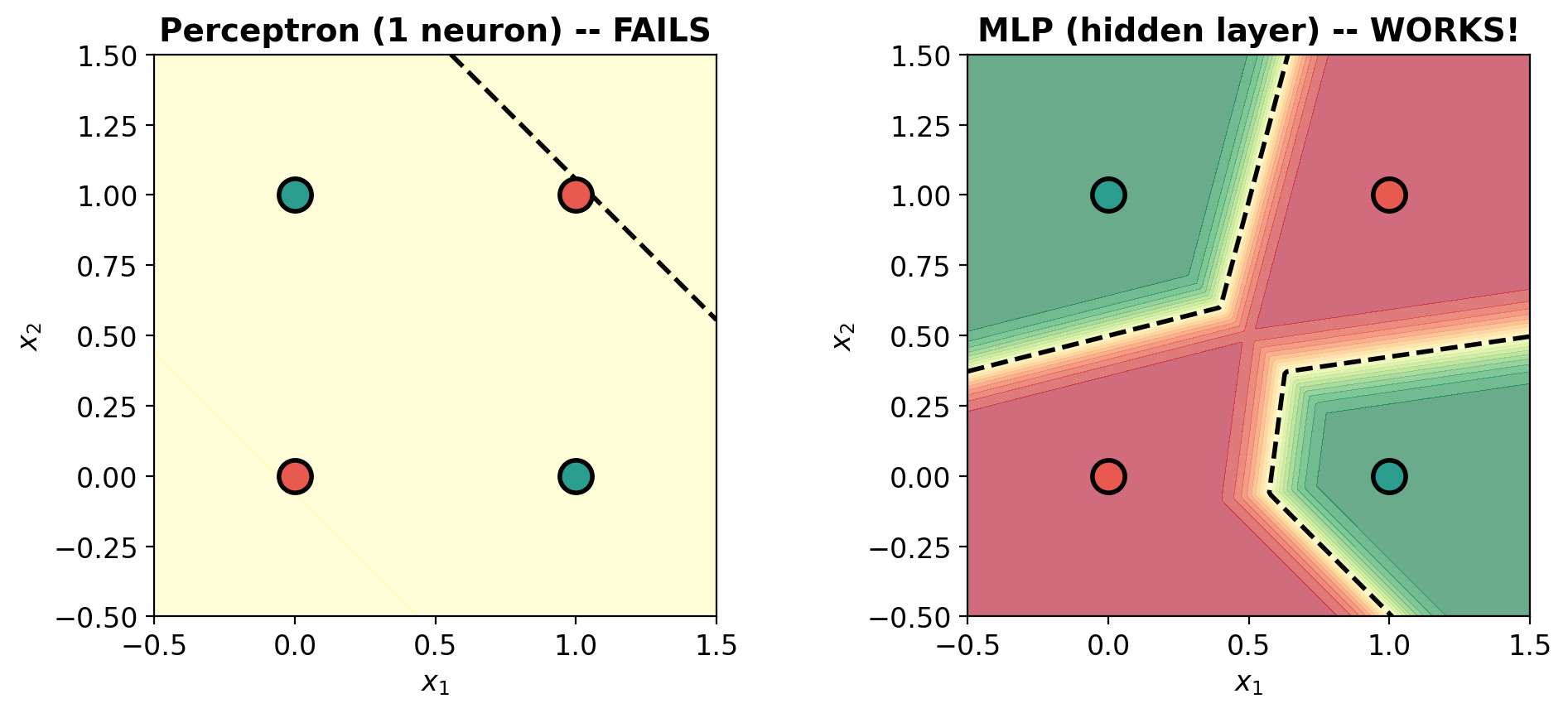
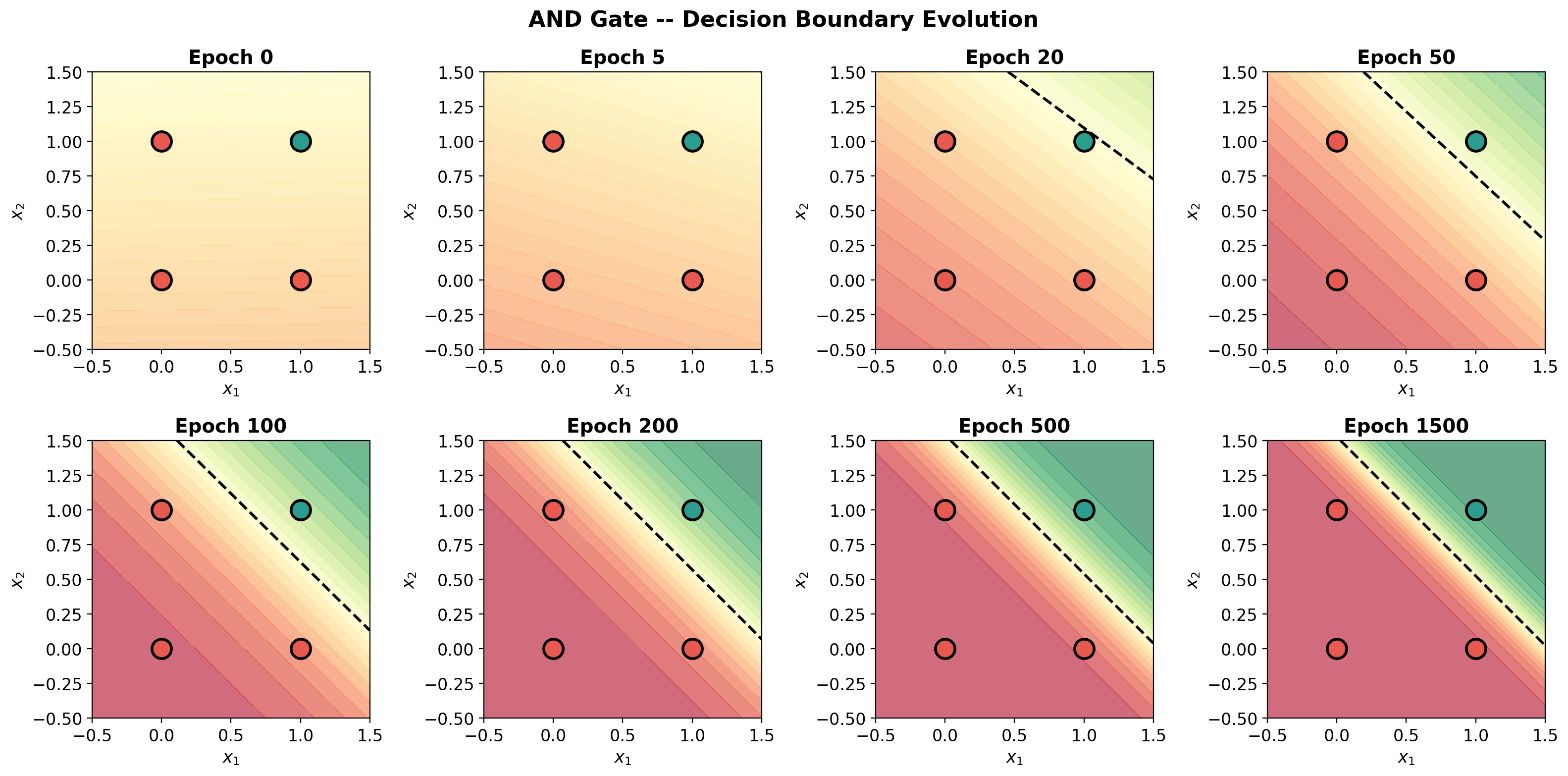
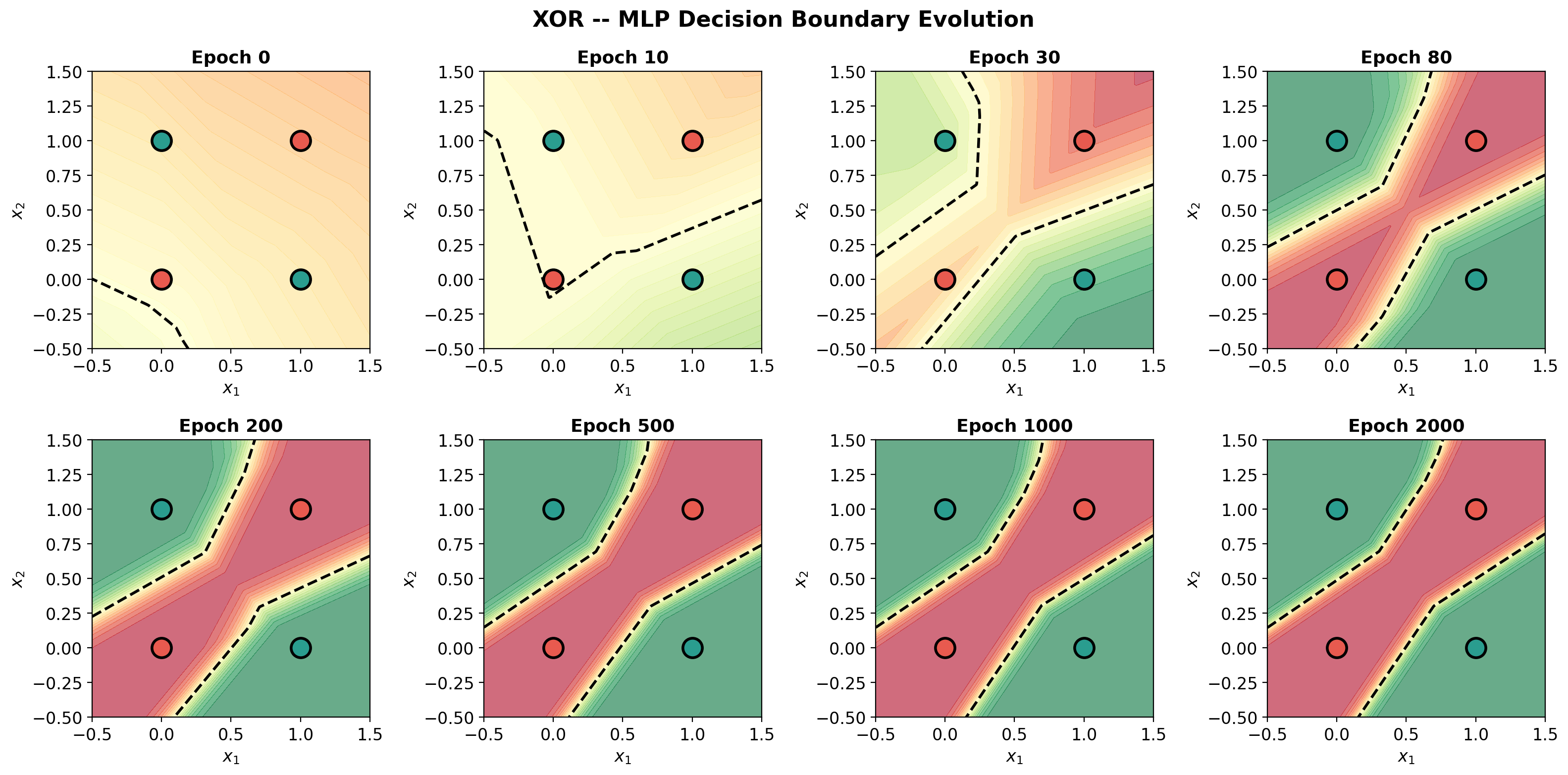
def plot_decision_surface(model, X, y, title='', ax=None):
"""Plot the decision surface of a perceptron."""
if ax is None:
fig, ax = plt.subplots(figsize=(5, 5))
# Create mesh
xx, yy = np.meshgrid(np.linspace(-0.5, 1.5, 200),
np.linspace(-0.5, 1.5, 200))
grid = torch.tensor(np.c_[xx.ravel(), yy.ravel()], dtype=torch.float32)
with torch.no_grad():
Z = model(grid).numpy().reshape(xx.shape)
# Probability heatmap
im = ax.contourf(xx, yy, Z, levels=20, cmap='RdYlGn', alpha=0.6, vmin=0, vmax=1)
ax.contour(xx, yy, Z, levels=[0.5], colors='black', linewidths=2, linestyles='--')
# Data points
y_np = y.numpy().ravel()
ax.scatter(X[y_np == 0, 0], X[y_np == 0, 1], c=C0, s=200, edgecolors='black',
linewidth=2, zorder=5, label='0')
ax.scatter(X[y_np == 1, 0], X[y_np == 1, 1], c=C1, s=200, edgecolors='black',
linewidth=2, zorder=5, label='1')
# Labels on points
for i in range(len(X)):
ax.annotate(f'{int(y_np[i])}', (X[i, 0].item(), X[i, 1].item()),
ha='center', va='center', fontsize=14, fontweight='bold',
color='white' if y_np[i] == 0 else 'white')
ax.set_xlim(-0.5, 1.5); ax.set_ylim(-0.5, 1.5)
ax.set_xlabel('$x_1$'); ax.set_ylabel('$x_2$')
ax.set_title(title, fontweight='bold', fontsize=14)
ax.set_aspect('equal')
return ax
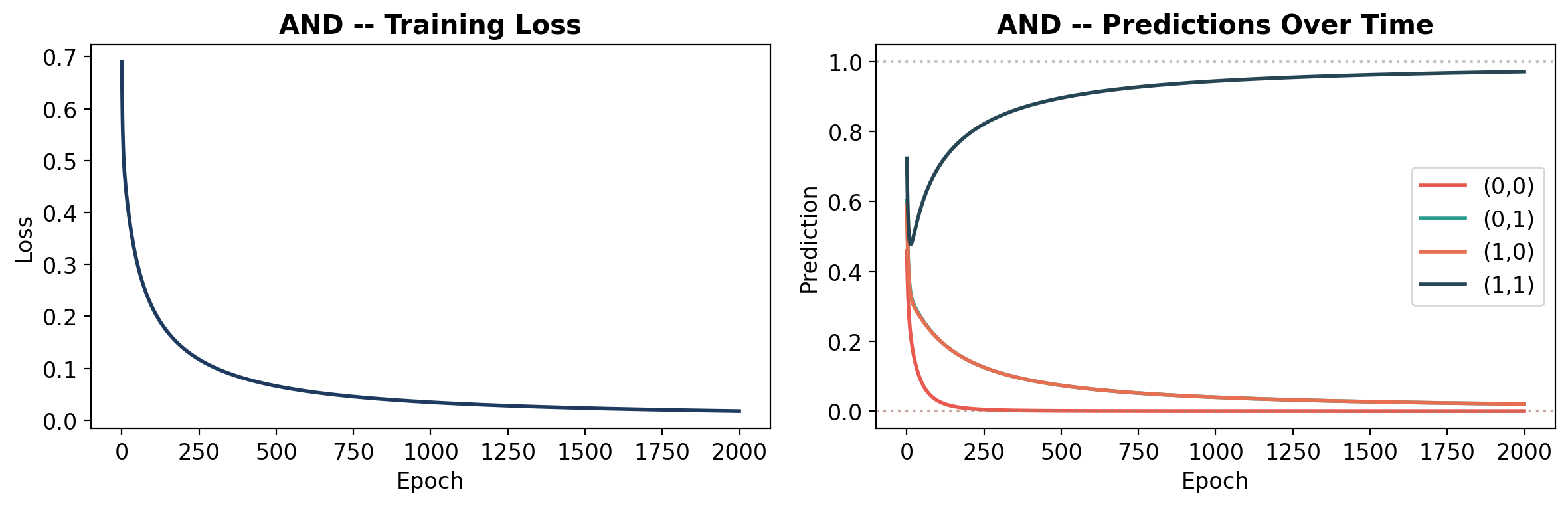
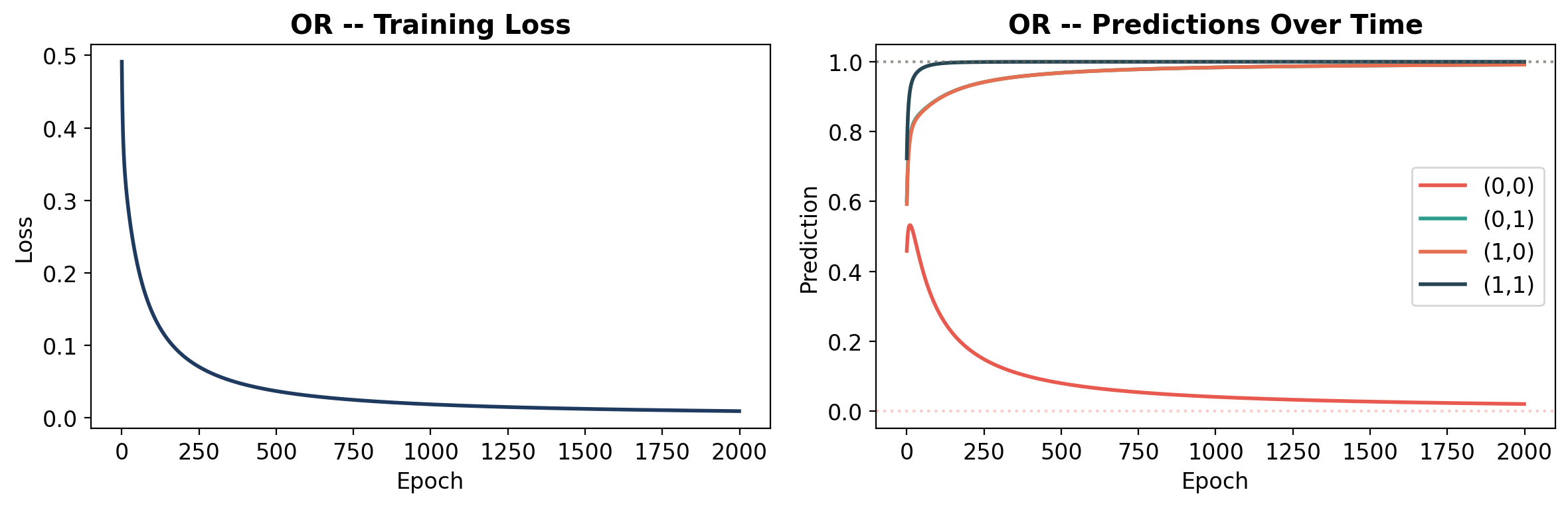
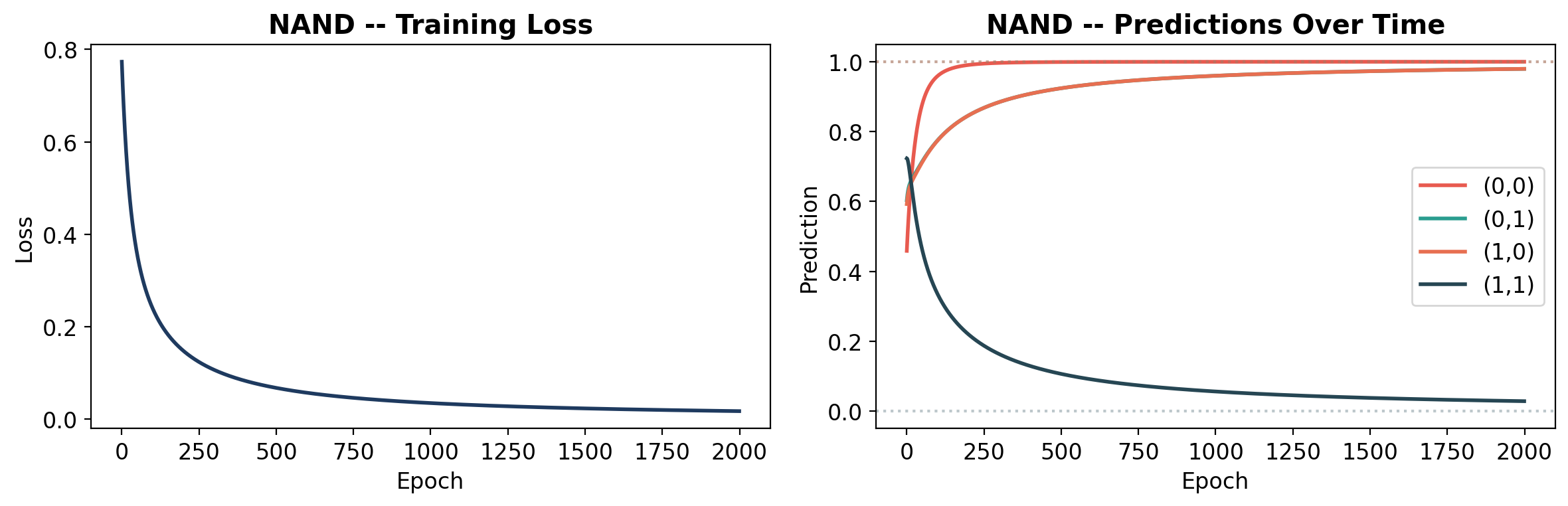
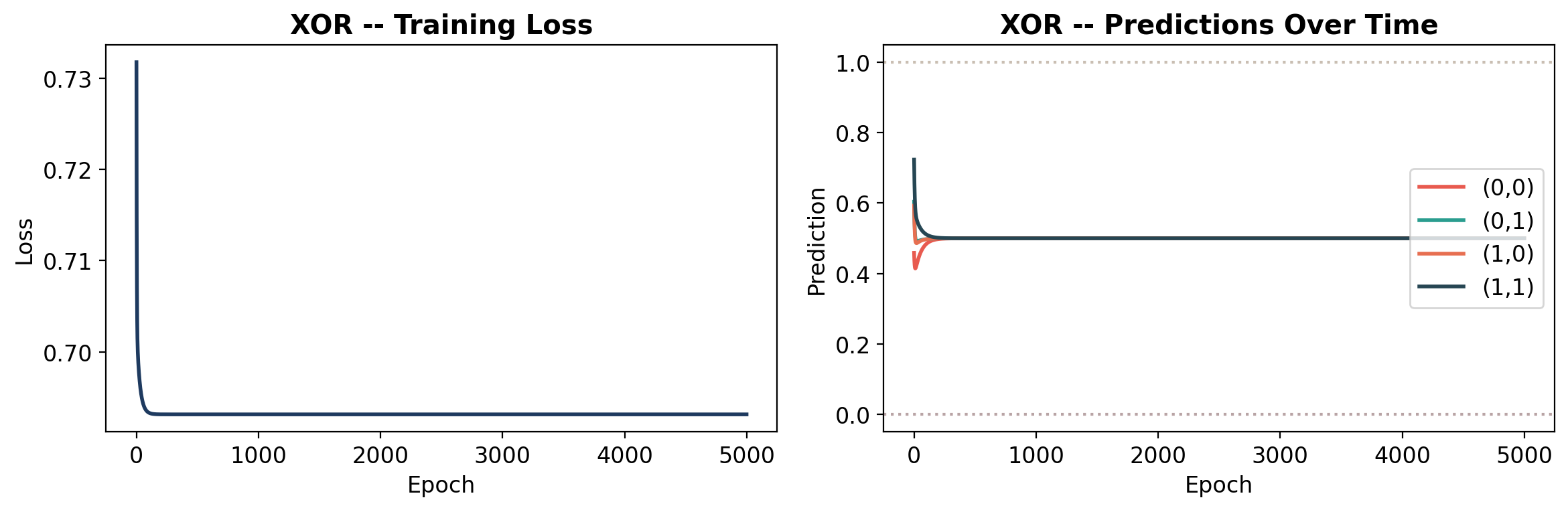
def plot_learning(history, gate_name, y):
"""Plot loss curve and prediction evolution."""
fig, axes = plt.subplots(1, 2, figsize=(12, 4))
# Loss
axes[0].plot(history['loss'], color='#1e3a5f', linewidth=2)
axes[0].set_xlabel('Epoch')
axes[0].set_ylabel('Loss')
axes[0].set_title(f'{gate_name} -- Training Loss', fontweight='bold')
# Predictions over time
preds = np.array(history['predictions'])
labels = ['(0,0)', '(0,1)', '(1,0)', '(1,1)']
colors_line = ['#e85a4f', '#2a9d8f', '#e76f51', '#264653']
for i in range(4):
axes[1].plot(preds[:, i], label=labels[i], linewidth=2, color=colors_line[i])
# Target lines
y_np = y.numpy().ravel()
for i in range(4):
axes[1].axhline(y=y_np[i], color=colors_line[i], linestyle=':', alpha=0.3)
axes[1].set_xlabel('Epoch')
axes[1].set_ylabel('Prediction')
axes[1].set_title(f'{gate_name} -- Predictions Over Time', fontweight='bold')
axes[1].legend(loc='center right')
axes[1].set_ylim(-0.05, 1.05)
plt.tight_layout()
plt.show()