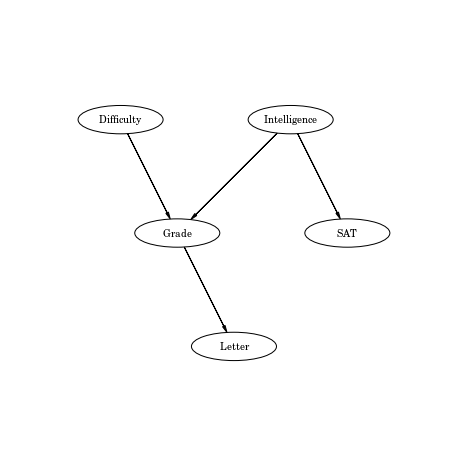
network={
"V": ["Letter", "Grade", "Intelligence", "SAT", "Difficulty"],
"E": [["Intelligence", "Grade"],
["Difficulty", "Grade"],
["Intelligence", "SAT"],
["Grade", "Letter"]],
"Vdata": {
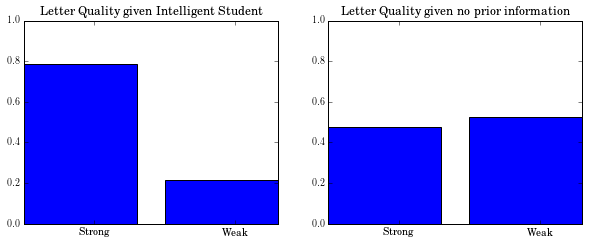
"Letter": {
"ord": 4,
"numoutcomes": 2,
"vals": ["weak", "strong"],
"parents": ["Grade"],
"children": None,
"cprob": {
"['A']": [.1, .9],
"['B']": [.4, .6],
"['C']": [.99, .01]
}
},
"SAT": {
"ord": 3,
"numoutcomes": 2,
"vals": ["lowscore", "highscore"],
"parents": ["Intelligence"],
"children": None,
"cprob": {
"['low']": [.95, .05],
"['high']": [.2, .8]
}
},
"Grade": {
"ord": 2,
"numoutcomes": 3,
"vals": ["A", "B", "C"],
"parents": ["Difficulty", "Intelligence"],
"children": ["Letter"],
"cprob": {
"['easy', 'low']": [.3, .4, .3],
"['easy', 'high']": [.9, .08, .02],
"['hard', 'low']": [.05, .25, .7],
"['hard', 'high']": [.5, .3, .2]
}
},
"Intelligence": {
"ord": 1,
"numoutcomes": 2,
"vals": ["low", "high"],
"parents": None,
"children": ["SAT", "Grade"],
"cprob": [.7, .3]
},
"Difficulty": {
"ord": 0,
"numoutcomes": 2,
"vals": ["easy", "hard"],
"parents": None,
"children": ["Grade"],
"cprob": [.6, .4]
}
}
}