A programming introduction to Active Learning with Bayesian Linear Regression.
ML
Author
Zeel Patel & Nipun Batra
Published
March 28, 2020
A quick wrap-up for Bayesian Linear Regression (BLR)
We have a feature matrix \(X\) and a target vector \(Y\). We want to obtain \(\theta\) vector in such a way that the error \(\epsilon\) for the following equation is minimum.
\[\begin{equation}
Y = X^T\theta + \epsilon
\end{equation}\] Prior PDF for \(\theta\) is,
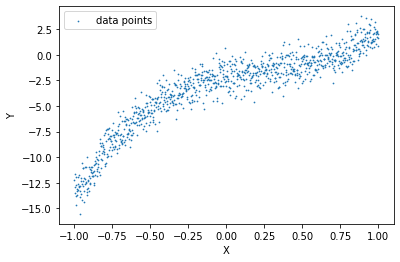
We’ll try to fit a degree 5 polynomial function to our data.
Code
X = PolynomialFeatures(degree=5, include_bias=True).fit_transform(X_init.reshape(-1,1))N_features = X.shape[1]
Code
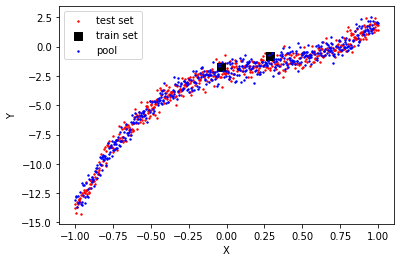
plt.scatter(X[:,1], Y, s=0.5, label ='data points')plt.xlabel("X")plt.ylabel("Y")plt.legend()plt.show()
Learning a BLR model on the entire data
We’ll take \(M_0\) (prior mean) as zero vector initially, assuming that we do not have any prior knowledge about \(M_0\). We’re taking \(S_0\) (prior covariance) as the identity matrix, assuming that all coefficients are completely independent of each other.
When the noise was high, the model tended to align with the prior. After keeping the prior closer to the original coefficients, the model was improved as expected. From the last plot, we can say that as noise reduces from the data, the impact of the prior reduces, and the model tries to fit the data more precisely. Therefore, we can say that when data is too noisy or insufficient, a wisely chosen prior can produce a precise fit.
Intuition to Active Learning (Uncertainty Sampling) with an example
Let’s take the case where we want to train a machine learning model to classify if a person is infected with COVID-19 or not, but the testing facilities for the same are not available so widely. We may have very few amounts of data for detected positive and detected negative patients. Now, we want our model to be highly confident or least uncertain about its results; otherwise, it may create havoc for wrongly classified patients, but, our bottleneck is labeled data. Thanks to active learning techniques, we can overcome this problem smartly. How?
We train our model with existing data and test it on all the suspected patients’ data. Let’s say we have an uncertainty measure or confidence level about each tested data point (distance from the decision boundary in case of SVM, variance in case of Gaussian processes, or Bayesian Linear Regression). We can choose a patient for which our model is least certain, and send him to COVID-19 testing facilities (assuming that we can send only one patient at a time). Now, we can include his data to the train set and test the model on everyone else. By following the same procedure repeatedly, we can increase the size of our train data and confidence of the model without sending everyone randomly for testing.
This method is called Uncertainty Sampling in Active Learning. Now let’s formally define Active Learning. From Wikipedia,
Active learning is a special case of machine learning in which a learning algorithm can interactively query a user (or some other information source) to label new data points with the desired outputs.
Now, we’ll go through the active learning procedure step by step.
Train set, test set, and pool. What is what?
The train set includes labeled data points. The pool includes potential data points to query for a label, and the test set includes labeled data points to check the performance of our model. Here, we cannot actually do a query to anyone, so we assume that we do not have labels for the pool while training, and after each iteration, we include a data point from the pool set to the train set for which our model has the highest uncertainty.
So, the algorithm can be represented as the following,
Train the model with the train set.
Test the performance on the test set (This should keep improving).
Test the model with the pool.
Query for the most uncertain datapoint from the pool.
Add that datapoint into the train set.
Repeat step 1 to step 5 for \(K\) iterations (\(K\) ranges from \(0\) to the pool size).
Creating initial train set, test set, and pool
Let’s take half of the dataset as the test set, and from another half, we will start with some points as the train set and remaining as the pool. Let’s start with 2 data points as the train set.
Let’s initialize a few dictionaries to keep track of each iteration.
Code
train_X_iter = {} # to store train points at each iterationtrain_Y_iter = {} # to store corresponding labels to the train set at each iterationmodels = {} # to store the models at each iterationestimations = {} # to store the estimations on the test set at each iterationtest_mae_error = {} # to store MAE(Mean Absolute Error) at each iteration
Training & testing initial learner on train set (Iteration 0)
Now we will train the model for the initial train set, which is iteration 0.
Creating a plot method to visualize train, test and pool with estimations and uncertainty.
Code
def plot(ax, model, init_title=''):# Plotting the pool ax.scatter(pool_X[:,1], pool_Y, label='pool',s=1,color='r',alpha=0.4)# Plotting the test data ax.scatter(test_X[:,1], test_Y, label='test data',s=1, color='b', alpha=0.4)# Combining the test & the pool test_pool_X, test_pool_Y = np.append(test_X,pool_X, axis=0), np.append(test_Y,pool_Y)# Sorting test_pool for plotting sorted_inds = np.argsort(test_pool_X[:,1]) test_pool_X, test_pool_Y = test_pool_X[sorted_inds], test_pool_Y[sorted_inds]# Plotting test_pool with uncertainty model.predict(test_pool_X) individual_var = model.pred_var.diagonal() ax.plot(test_pool_X[:,1], model.y_hat_map, color='black', label='model') ax.fill_between(test_pool_X[:,1], model.y_hat_map-individual_var, model.y_hat_map+individual_var , alpha=0.2, color='black', label='uncertainty')# Plotting the train data ax.scatter(model.x[:,1], model.y,s=40, color='k', marker='s', label='train data') ax.scatter(model.x[-1,1], model.y[-1],s=80, color='r', marker='o', label='last added point')# Plotting MAE on the test set model.predict(test_X) ax.set_title(init_title+' MAE is '+str(np.mean(np.abs(test_Y - model.y_hat_map)))) ax.set_xlabel('x') ax.set_ylabel('y') ax.legend()
Plotting the estimations and uncertainty.
Code
fig, ax = plt.subplots()plot(ax, models[0])
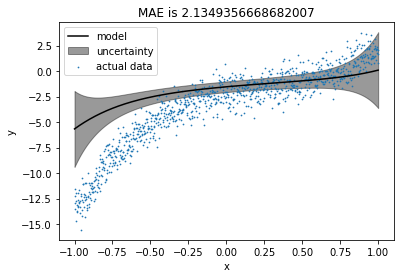
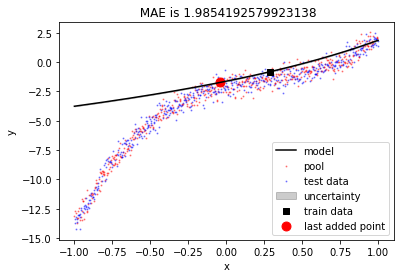
Let’s check the maximum uncertainty about any point for the model.
Code
models[0].pred_var.diagonal().max()
4.8261426545316604e-29
Oops!! There is almost no uncertainty in the model. Why? let’s try again with more train points.
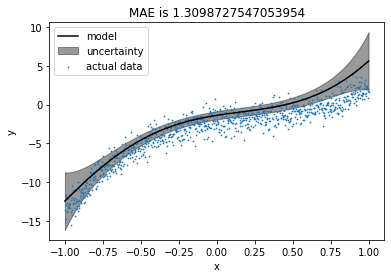
Now uncertainty is visible, and currently, it’s high at the left-most points. We are trying to fit a degree 5 polynomial here. So our linear regression coefficients are 6, including the bias. If we choose train points equal to or lesser than 6, our model perfectly fits the train points and has no uncertainty. Choosing train points more than 6 induces uncertainty in the model.
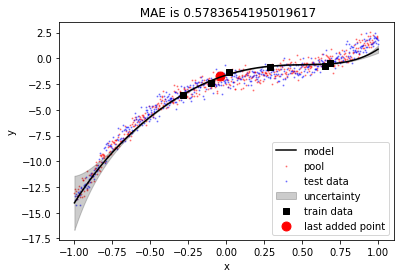
Moving the most uncertain point from the pool to the train set
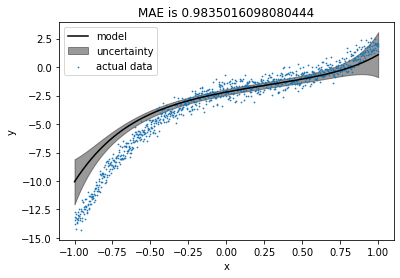
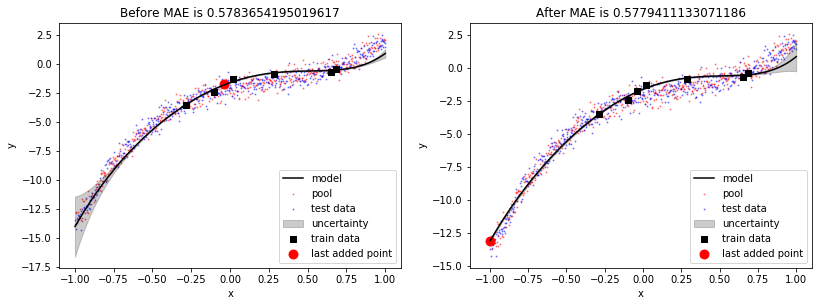
In the previous plot, we saw that the model was least certain about the left-most point. We’ll move that point from the pool to the train set and see the effect.
We can see that including most uncertain point into the train set has produced a better fit and MAE for test set has been reduced. Also, uncertainty has reduced at the left part of the data but it has increased a bit on the right part of the data.
Now let’s do this for few more iterations in a loop and visualise the results.
Active learning procedure
Code
num_iterations =20points_added_x= np.zeros((num_iterations+1, N_features))points_added_y=[]print("Iteration, Cost\n")print("-"*40)for iteration inrange(2, num_iterations+1):# Making predictions on the pool set based on model learnt in the respective train set estimations_pool, var = models[iteration-1].predict(pool_X)# Finding the point from the pool with highest uncertainty in_var = var.diagonal().argmax() to_add_x = pool_X[in_var,:] to_add_y = pool_Y[in_var] points_added_x[iteration-1,:] = to_add_x points_added_y.append(to_add_y)# Adding the point to the train set from the pool train_X_iter[iteration] = np.vstack([train_X_iter[iteration-1], to_add_x]) train_Y_iter[iteration] = np.append(train_Y_iter[iteration-1], to_add_y)# Deleting the point from the pool pool_X = np.delete(pool_X, in_var, axis=0) pool_Y = np.delete(pool_Y, in_var)# Training on the new set models[iteration] = BLR(S0, models[iteration-1].MN) models[iteration].fit(train_X_iter[iteration], train_Y_iter[iteration]) estimations[iteration], _ = models[iteration].predict(test_X) test_mae_error[iteration]= pd.Series(estimations[iteration] - test_Y.squeeze()).abs().mean()print(iteration, (test_mae_error[iteration]))
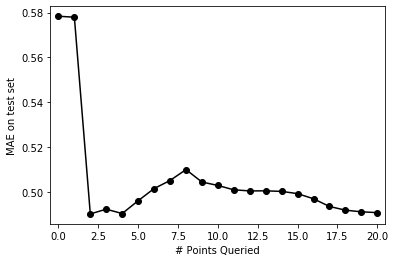
pd.Series(test_mae_error).plot(style='ko-')plt.xlim((-0.5, num_iterations+0.5))plt.ylabel("MAE on test set")plt.xlabel("# Points Queried")plt.show()
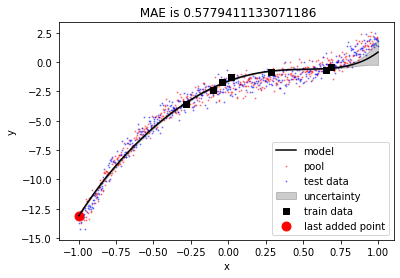
The plot above shows that MAE on the test set fluctuates a bit initially then reduces gradually as we keep including more points from the pool to the train set. Let’s visualise fits for all the iterations. We’ll discuss this behaviour after that.
We can see that the point having highest uncertainty was chosen in first iteration and it produced the near optimal fit. After that, error reduced gradually.
Now, let’s put everything together and create a class for active learning procedure
Creating a class for active learning procedure
Code
class ActiveL():def__init__(self, X, y, S0=None, M0=None, test_size=0.5, degree =5, iterations =20, seed=1):self.X_init = Xself.y = yself.S0 = S0self.M0 = M0self.train_X_iter = {} # to store train points at each iterationself.train_Y_iter = {} # to store corresponding labels to the train set at each iterationself.models = {} # to store the models at each iterationself.estimations = {} # to store the estimations on the test set at each iterationself.test_mae_error = {} # to store MAE(Mean Absolute Error) at each iterationself.test_size = test_sizeself.degree = degreeself.iterations = iterationsself.seed = seedself.train_size = degree +2def data_preperation(self):# Adding polynomial featuresself.X = PolynomialFeatures(degree=self.degree).fit_transform(self.X_init) N_features =self.X.shape[1]# Splitting into train, test and pool train_pool_X, self.test_X, train_pool_Y, self.test_Y = train_test_split(self.X, self.y, test_size=self.test_size, random_state=self.seed)self.train_X, self.pool_X, self.train_Y, self.pool_Y = train_test_split(train_pool_X, train_pool_Y, train_size=self.train_size, random_state=self.seed)# Setting BLR prior incase of not givenifself.M0 ==None:self.M0 = np.zeros((N_features, ))ifself.S0 ==None:self.S0 = np.eye(N_features)def main(self):# Training for iteration 0self.train_X_iter[0] =self.train_Xself.train_Y_iter[0] =self.train_Yself.models[0] = BLR(self.S0, self.M0)self.models[0].fit(self.train_X, self.train_Y)# Running loop for all iterationsfor iteration inrange(1, self.iterations+1):# Making predictions on the pool set based on model learnt in the respective train set estimations_pool, var =self.models[iteration-1].predict(self.pool_X)# Finding the point from the pool with highest uncertainty in_var = var.diagonal().argmax() to_add_x =self.pool_X[in_var,:] to_add_y =self.pool_Y[in_var]# Adding the point to the train set from the poolself.train_X_iter[iteration] = np.vstack([self.train_X_iter[iteration-1], to_add_x])self.train_Y_iter[iteration] = np.append(self.train_Y_iter[iteration-1], to_add_y)# Deleting the point from the poolself.pool_X = np.delete(self.pool_X, in_var, axis=0)self.pool_Y = np.delete(self.pool_Y, in_var)# Training on the new setself.models[iteration] = BLR(self.S0, self.models[iteration-1].MN)self.models[iteration].fit(self.train_X_iter[iteration], self.train_Y_iter[iteration])self.estimations[iteration], _ =self.models[iteration].predict(self.test_X)self.test_mae_error[iteration]= pd.Series(self.estimations[iteration] -self.test_Y.squeeze()).abs().mean()def _plot_iter_MAE(self, ax, iteration): ax.plot(list(self.test_mae_error.values())[:iteration+1], 'ko-') ax.set_title('MAE on test set over iterations') ax.set_xlim((-0.5, self.iterations+0.5)) ax.set_ylabel("MAE on test set") ax.set_xlabel("# Points Queried")def _plot(self, ax, model):# Plotting the pool ax.scatter(self.pool_X[:,1], self.pool_Y, label='pool',s=1,color='r',alpha=0.4)# Plotting the test data ax.scatter(self.test_X[:,1], self.test_Y, label='test data',s=1, color='b', alpha=0.4)# Combining test_pool test_pool_X, test_pool_Y = np.append(self.test_X, self.pool_X, axis=0), np.append(self.test_Y, self.pool_Y)# Sorting test_pool sorted_inds = np.argsort(test_pool_X[:,1]) test_pool_X, test_pool_Y = test_pool_X[sorted_inds], test_pool_Y[sorted_inds]# Plotting test_pool with uncertainty preds, var = model.predict(test_pool_X) individual_var = var.diagonal() ax.plot(test_pool_X[:,1], model.y_hat_map, color='black', label='model') ax.fill_between(test_pool_X[:,1], model.y_hat_map-individual_var, model.y_hat_map+individual_var , alpha=0.2, color='black', label='uncertainty')# plotting the train data ax.scatter(model.x[:,1], model.y,s=10, color='k', marker='s', label='train data') ax.scatter(model.x[-1,1], model.y[-1],s=80, color='r', marker='o', label='last added point')# plotting MAE preds, var = model.predict(self.test_X) ax.set_title('MAE is '+str(np.mean(np.abs(self.test_Y - preds)))) ax.set_xlabel('x') ax.set_ylabel('y') ax.legend()def visualise_AL(self): fig, ax = plt.subplots(1,2,figsize=(13,5))def update(iteration): ax[0].cla() ax[1].cla()self._plot(ax[0], self.models[iteration])self._plot_iter_MAE(ax[1], iteration) fig.tight_layout()print('Initial model')print('Y = '+' + '.join(['{0:0.2f}'.format(self.models[0].MN[i])+' X^'*min(i,1)+str(i)*min(i,1) for i inrange(self.degree+1)]))print('\nFinal model')print('Y = '+' + '.join(['{0:0.2f}'.format(self.models[self.iterations].MN[i])+' X^'*min(i,1)+str(i)*min(i,1) for i inrange(self.degree+1)])) anim = FuncAnimation(fig, update, frames=np.arange(0, self.iterations+1, 1), interval=250) plt.close() rc('animation', html='jshtml')return anim
Visualizing a different polynomial fit on the same dataset
Let’s try to fit a degree 7 polynomial to the same data now.
We can clearly see that model was fitting the train points well and uncertainty was high at the left-most position. After first iteration, the left-most point was added to the train set and MAE reduced significantly. Similar phenomeneon happened at iteration 2 with the right-most point. After that error kept reducing at slower rate gradually because fit was near optimal after just 2 iterations.
Active learning for diabetes dataset from the Scikit-learn module
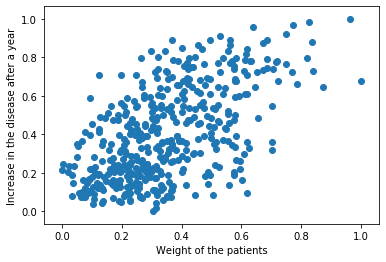
Let’s run our model for diabetes data from sklearn module. The data have various features like age, sex, weight etc. of diabetic people and target is increment in disease after one year. We’ll choose only ‘weight’ feature, which seems to have more correlation with the target.
We’ll try to fit degree 1 polynomial to this data, as our data seems to have a linear fit. First, let’s check the performance of Scikit-learn linear regression model.
Code
X, Y = datasets.load_diabetes(return_X_y=True)X = X[:, 2].reshape(-1,1) # Choosing only feature 2 which seems more relevent to linear regression# NormalizingX = (X - X.min())/(X.max() - X.min())Y = (Y - Y.min())/(Y.max() - Y.min())
Visualizing the dataset.
Code
plt.scatter(X, Y)plt.xlabel('Weight of the patients')plt.ylabel('Increase in the disease after a year')plt.show()
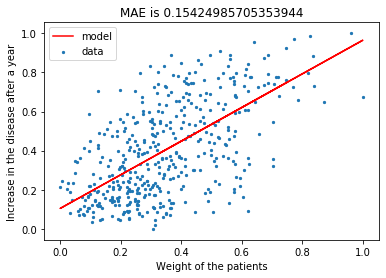
Let’s fit the Scikit-learn linear regression model with 50% train-test split.
Code
from sklearn.linear_model import LinearRegressiontrain_X, test_X, train_Y, test_Y = train_test_split(X, Y, test_size =0.5, random_state = seed)
plt.scatter(X, Y, label='data', s=5)plt.plot(test_X, pred_Y, label='model', color='r')plt.xlabel('Weight of the patients')plt.ylabel('Increase in the disease after a year')plt.title('MAE is '+str(np.mean(np.abs(pred_Y - test_Y))))plt.legend()plt.show()
Now we’ll fit the same data with our BLR model
Code
model = ActiveL(X.reshape(-1,1), Y, degree=1, iterations=20, seed=seed)
Initial model
Y = 0.41 + 0.16 X^1
Final model
Y = 0.13 + 0.86 X^1
Initially, the fit is leaning towards zero slope, which is the influence of bias due to a low number of training points. It’s interesting to see that our initial train points tend to make a vertical fit, but the model doesn’t get carried away by that and stabilizes the self with prior.
Code
print('MAE for Scikit-learn Linear Regression is',np.mean(np.abs(pred_Y - test_Y)))print('MAE for Bayesian Linear Regression is', model.test_mae_error[20])
MAE for Scikit-learn Linear Regression is 0.15424985705353944
MAE for Bayesian Linear Regression is 0.15738001811804758
At the end, results of sklearn linear regression and our active learning based BLR model are comparable even though we’ve used only 20 points to train our model over 221 points used by sklearn. This is because active learning enables us to choose those datapoints for training, which are going to contribute the most towards a precise fit.