G1: Given probability distributions \(p\) and \(q\), find the divergence (measure of similarity) between them
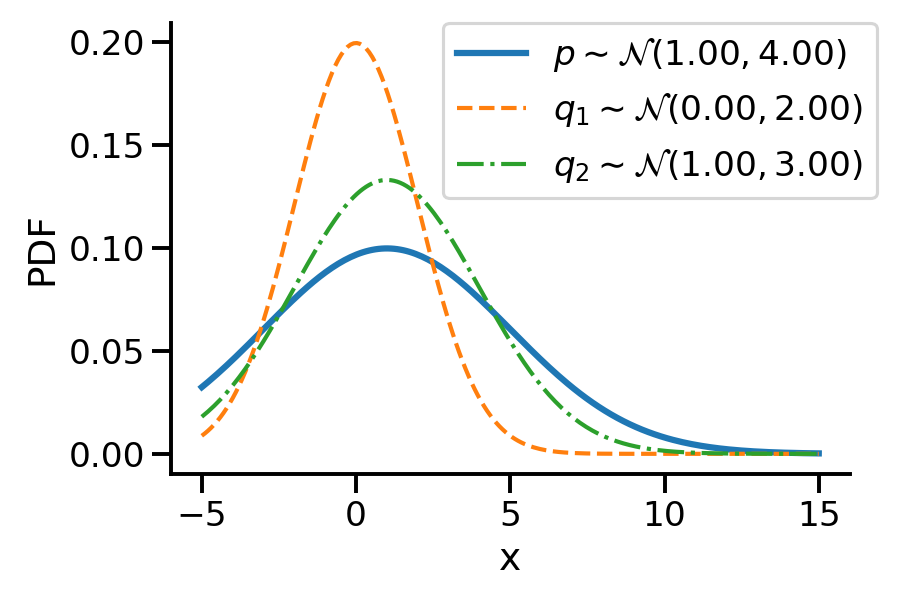
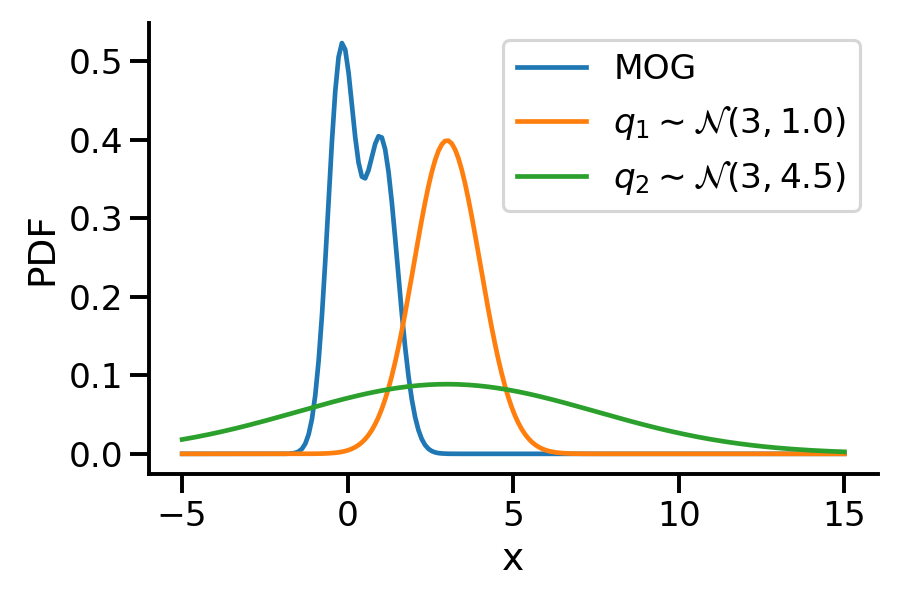
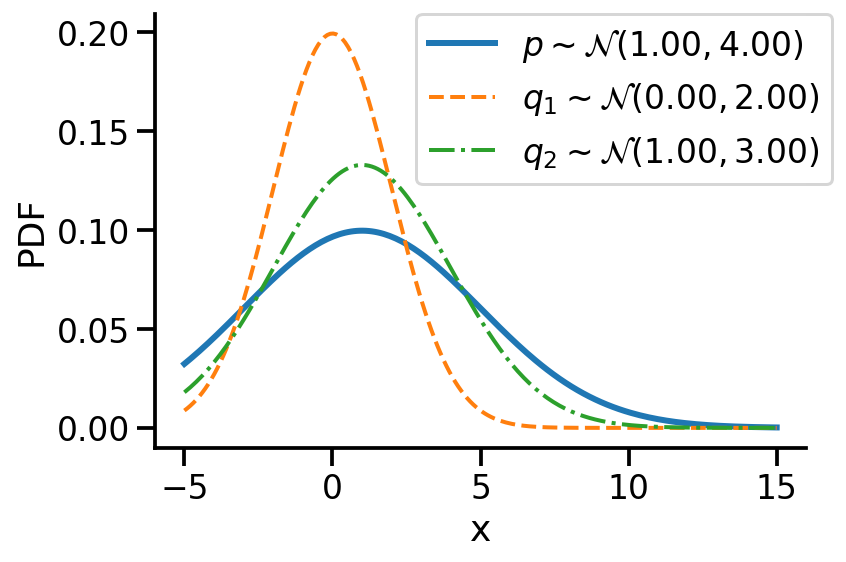
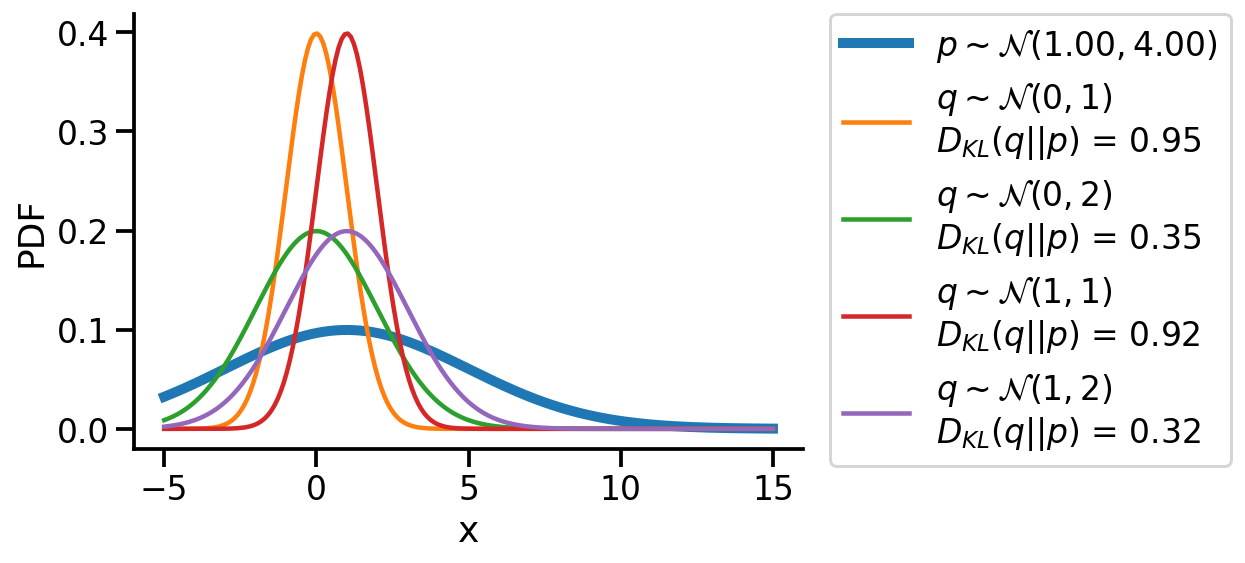
Let us first look at G1. Look at the illustration below. We have a normal distribution \(p\) and two other normal distributions \(q_1\) and \(q_2\). Which of \(q_1\) and \(q_2\), would we consider closer to \(p\)? \(q_2\), right?
To understand the notion of similarity, we use a metric called the KL-divergence given as \(D_{KL}(a || b)\) where \(a\) and \(b\) are the two distributions.
For G1, we can say \(q_2\) is closer to \(p\) compared to \(q_1\) as:
\(D_{KL}(q_2 || p) \lt D_{KL}(q_1 || p)\)
For the above example, we have the values as \(D_{KL}(q_2|| p) = 0.07\) and \(D_{KL}(q_1|| p)= 0.35\)
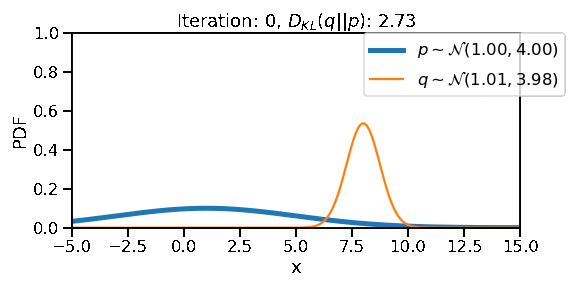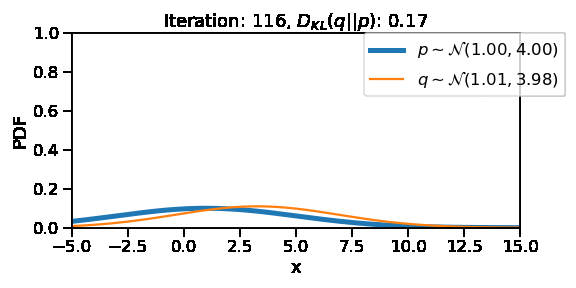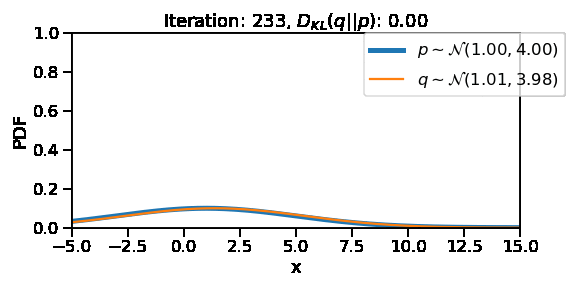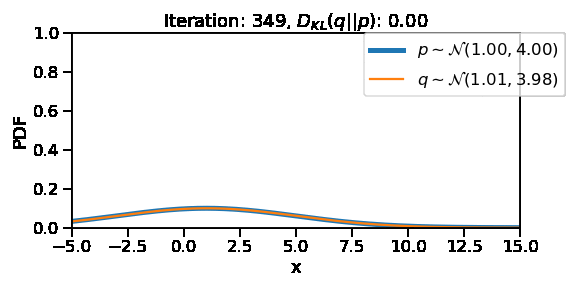
G2: assuming \(p\) to be fixed, can we find optimum parameters of \(q\) to make it as close as possible to \(p\)
The following GIF shows the process of finding the optimum set of parameters for a normal distribution \(q\) so that it becomes as close as possible to \(p\). This is equivalent of minimizing \(D_{KL}(q || p)\)
The following GIF shows the above but for a two-dimensional distribution.
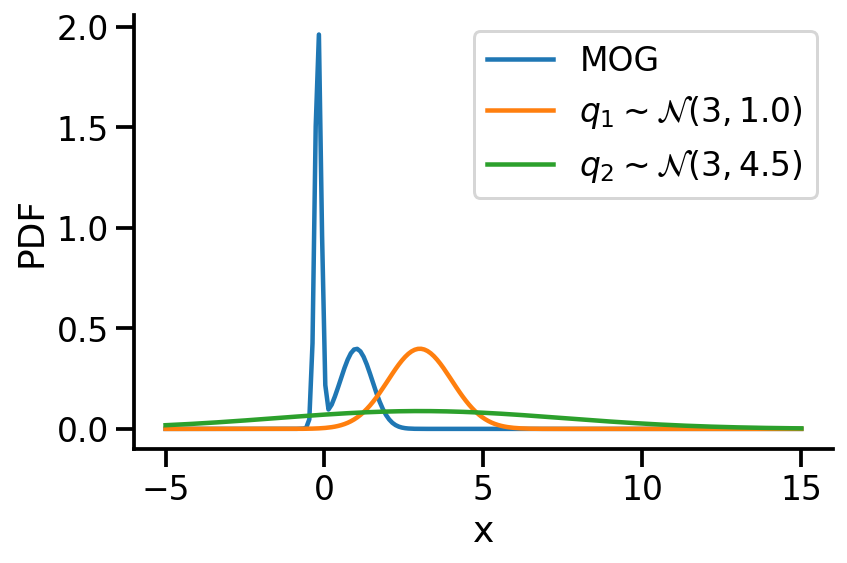
G3: finding the “distance” between two distributions of different families
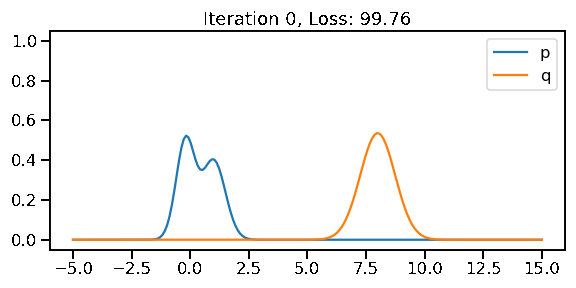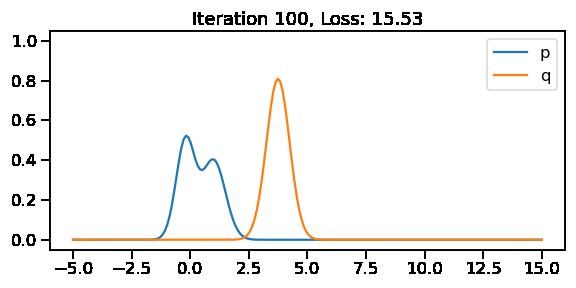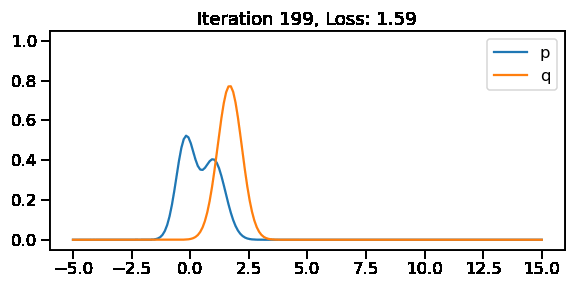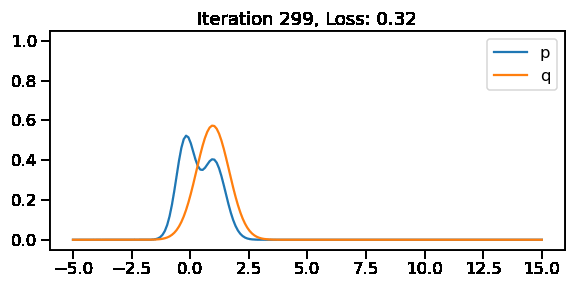
The below image shows the KL-divergence between distribution 1 (mixture of Gaussians) and distribution 2 (Gaussian)
G4: optimizing the “distance” between two distributions of different families
The below GIF shows the optimization of the KL-divergence between distribution 1 (mixture of Gaussians) and distribution 2 (Gaussian)
G5: Approximating the KL-divergence
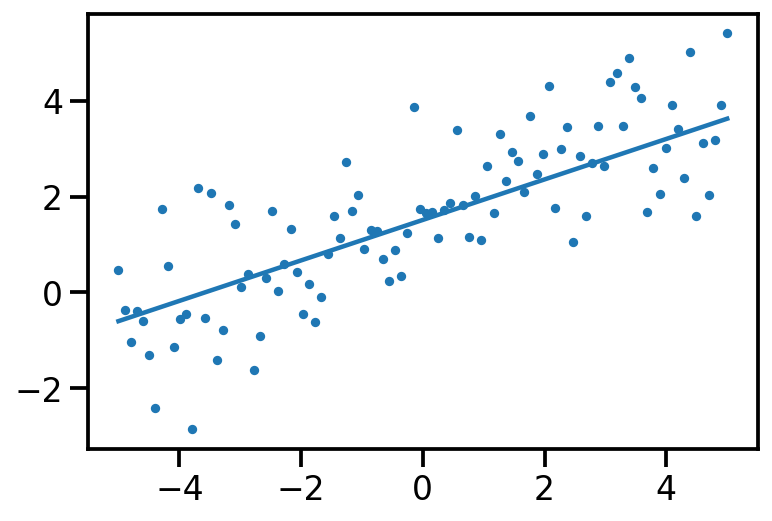
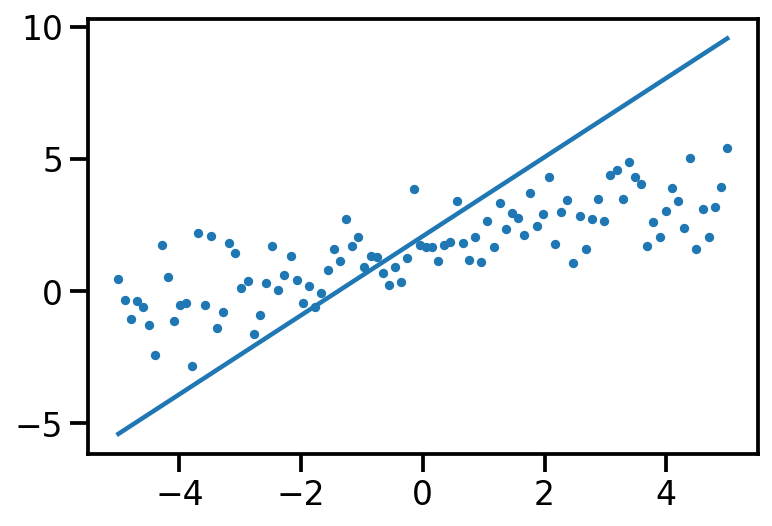
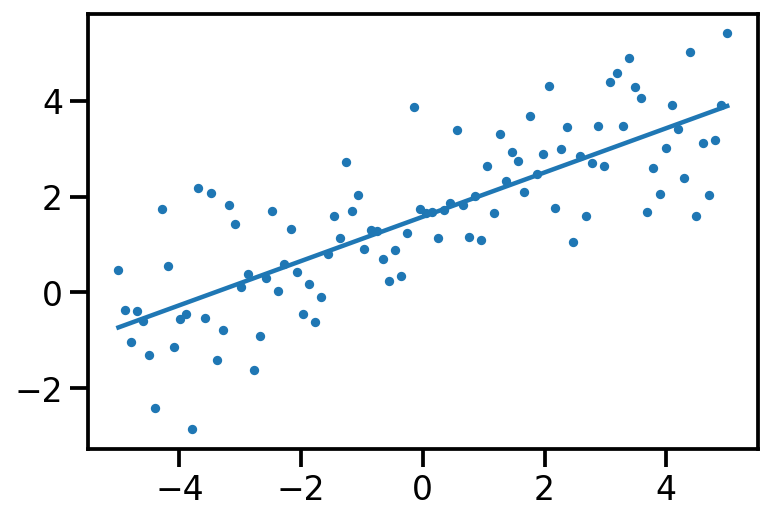
G6: Implementing variational inference for linear regression
Basic Imports
Code
import numpy as npimport matplotlib.pyplot as pltimport tensorflow as tfimport seaborn as snsimport tensorflow_probability as tfpimport pandas as pdtfd = tfp.distributionstfl = tfp.layerstfb = tfp.bijectorsfrom tensorflow.keras.models import Sequentialfrom tensorflow.keras.layers import Densefrom tensorflow.keras.optimizers import RMSpropfrom tensorflow.keras.callbacks import Callbacksns.reset_defaults()sns.set_context(context="talk", font_scale=1)%matplotlib inline%config InlineBackend.figure_format='retina'
Creating distributions
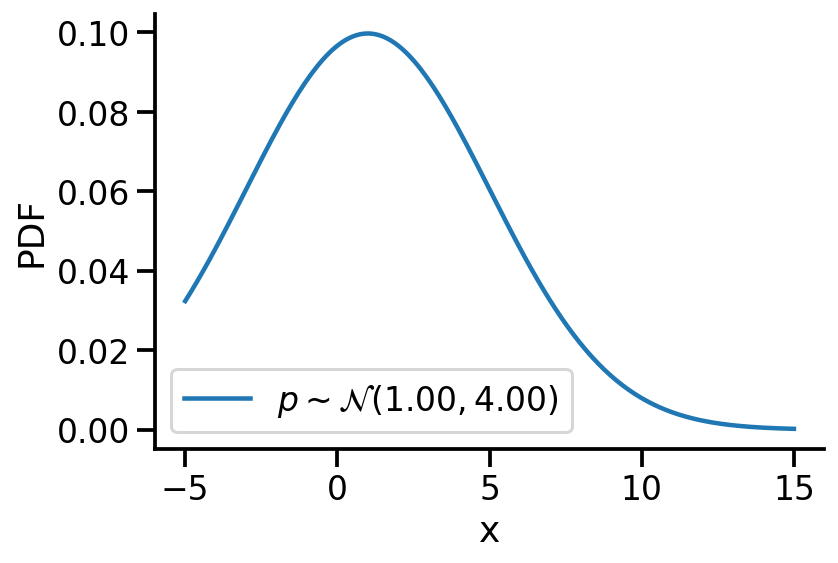
Creating \(p\sim\mathcal{N}(1.00, 4.00)\)
Code
p = tfd.Normal(1, 4)
2022-02-04 14:55:14.596076: I tensorflow/core/platform/cpu_feature_guard.cc:151] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2022-02-04 14:55:19.564807: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them.
Finding the KL divergence for two distributions from different families
Let us rework our example with p coming from a mixture of Gaussian distribution and q being Normal.
Code
p_s = tfd.MixtureSameFamily( mixture_distribution=tfd.Categorical(probs=[0.5, 0.5]), components_distribution=tfd.Normal( loc=[-0.2, 1], scale=[0.1, 0.5] # One for each component. ),) # And same here.p_s
No KL(distribution_a || distribution_b) registered for distribution_a type Normal and distribution_b type MixtureSameFamily
As we see above, we can not compute the KL divergence directly. The core idea would now be to leverage the Monte Carlo sampling and generating the expectation. The following function does that.
Code
def kl_via_sampling(q, p, n_samples=100000):# Get samples from q sample_set = q.sample(n_samples)# Use the definition of KL-divergencereturn tf.reduce_mean(q.log_prob(sample_set) - p.log_prob(sample_set))
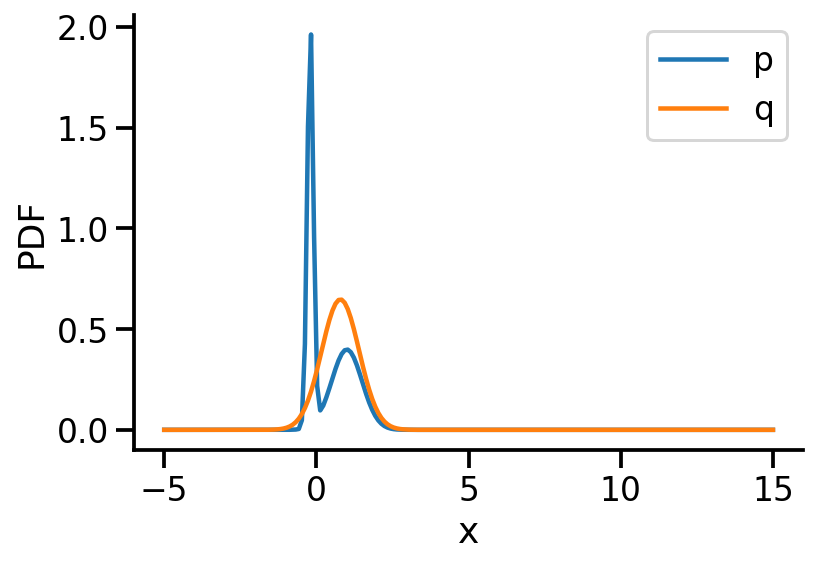
As we can see from KL divergence calculations, q_1 is closer to our Gaussian mixture distribution.
Optimizing the KL divergence for two distributions from different families
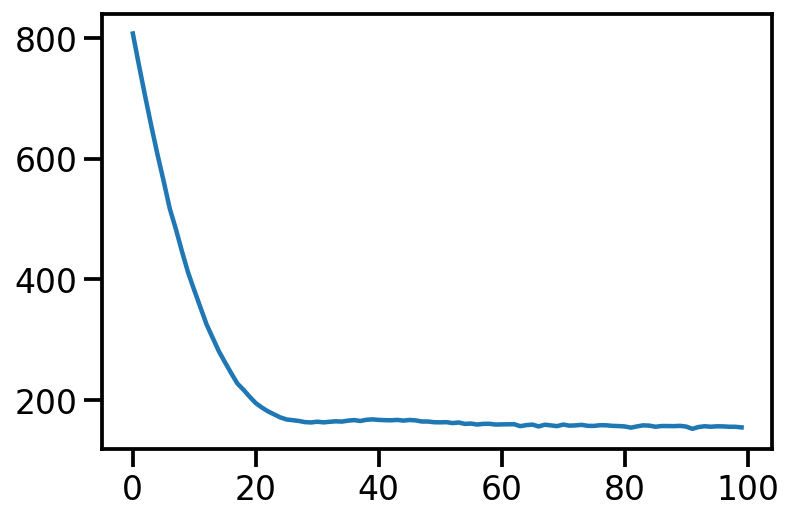
We saw that we can calculate the KL divergence between two different distribution families via sampling. But, as we did earlier, will we be able to optimize the parameters of our target surrogate distribution? The answer is No! As we have introduced sampling. However, there is still a way – by reparameterization!
Our surrogate q in this case is parameterized by loc and scale. The key idea here is to generate samples from a standard normal distribution (loc=0, scale=1) and then apply an affine transformation on the generated samples to get the samples generated from q. See my other post on sampling from normal distribution to understand this better.
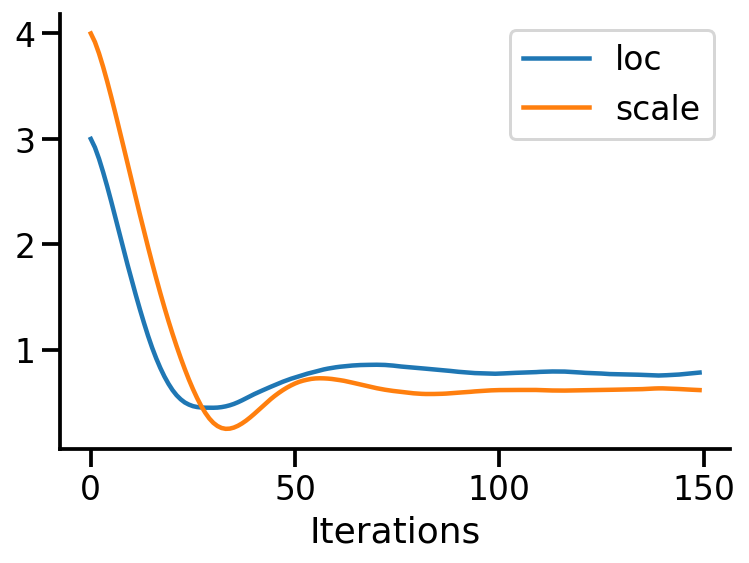
The loss can now be thought of as a function of loc and scale.
WARNING:tensorflow:From /Users/nipun/miniforge3/lib/python3.9/site-packages/tensorflow_probability/python/distributions/distribution.py:342: MultivariateNormalFullCovariance.__init__ (from tensorflow_probability.python.distributions.mvn_full_covariance) is deprecated and will be removed after 2019-12-01.
Instructions for updating:
`MultivariateNormalFullCovariance` is deprecated, use `MultivariateNormalTriL(loc=loc, scale_tril=tf.linalg.cholesky(covariance_matrix))` instead.
Code
from mpl_toolkits.mplot3d import Axes3Dfrom matplotlib import cmdef make_pdf_2d_gaussian(mu, sigma, ax, title): N =60 X = np.linspace(-3, 3, N) Y = np.linspace(-3, 4, N) X, Y = np.meshgrid(X, Y)# Pack X and Y into a single 3-dimensional array pos = np.empty(X.shape + (2,)) pos[:, :, 0] = X pos[:, :, 1] = Y F = tfd.MultivariateNormalFullCovariance(loc=mu, covariance_matrix=sigma) Z = F.prob(pos) sns.despine() ax.set_xlabel(r"$x_1$") ax.set_ylabel(r"$x_2$") ax.set_aspect("equal")if title: ax.set_title(f"$\mu$ = {mu}\n $\Sigma$ = {np.array(sigma)}") ax.contour(X, Y, Z, cmap="viridis", alpha=1, zorder=2)else: ax.contourf(X, Y, Z, cmap="plasma", alpha=0.1)
We can now see that the KL-divergence has reduced significantly from where we started, but it will unlikely improve as ou r q distribution is a multivariate diagonal normal distribution, meaning there is no correlation between the two dimensions.
To-FIX
Everything below here needs to be fixed
KL-Divergence and ELBO
Let us consider linear regression. We have parameters \(\theta \in R^D\) and we define a prior over them. Let us assume we define prior \(p(\theta)\sim \mathcal{N_D} (\mu, \Sigma)\). Now, given our dataset \(D = \{X, y\}\) and a parameter vector \(\theta\), we can deifine our likelihood as \(p(D|\theta)\) or $p(y|X, ) = {i=1}^{n} p(y_i|x_i, ) = {i=1}^{n} (y_i|x_i^T, ^2) $
As per Bayes rule, we can obtain the posterior over \(\theta\) as:
So, in variational inference, our aim is to use a surrogate distribution \(q(\theta)\) such that it is very close to \(p(\theta|D)\). We do so by minimizing the KL divergence between \(q(\theta)\) and \(p(\theta|D)\).
/Users/nipun/miniforge3/lib/python3.9/site-packages/tensorflow_probability/python/internal/vectorization_util.py:87: UserWarning: Saw Tensor seed Tensor("seed:0", shape=(2,), dtype=int32), implying stateless sampling. Autovectorized functions that use stateless sampling may be quite slow because the current implementation falls back to an explicit loop. This will be fixed in the future. For now, you will likely see better performance from stateful sampling, which you can invoke by passing a Python `int` seed.
warnings.warn(
/Users/nipun/miniforge3/lib/python3.9/site-packages/tensorflow_probability/python/internal/vectorization_util.py:87: UserWarning: Saw Tensor seed Tensor("seed:0", shape=(2,), dtype=int32), implying stateless sampling. Autovectorized functions that use stateless sampling may be quite slow because the current implementation falls back to an explicit loop. This will be fixed in the future. For now, you will likely see better performance from stateful sampling, which you can invoke by passing a Python `int` seed.
warnings.warn(