We will be studying the problem of coin tosses. I will not go into derivations but mostly deal with automatic gradient computation in TF Probability.
We have the following goals in this tutorial.
Goal 1: Maximum Likelihood Estimate (MLE)
Given a set of N observations, estimate the probability of H (denoted as \(\theta = p(H)\))
Goal 2: Maximum A-Posteriori (MAP)
Given a set of N observations and some prior knowledge on the distribution of \(\theta\), estimate the best point estimate of \(\theta\) once we have observed the dataset.
Goal 3: Fully Bayesian
Given a set of N observations and some prior knowledge on the distribution of \(\theta\), estimate the distribution of \(\theta\) once we have observed the dataset.
While I mention all the references below, I acknowledge Felix and his excellent repo and video playlist (Playlist 1, Playlist 2). They inspired me to create this post.
Basic Imports
Code
from silence_tensorflow import silence_tensorflowsilence_tensorflow()import numpy as npimport matplotlib.pyplot as pltimport tensorflow as tfimport functoolsimport seaborn as snsimport tensorflow_probability as tfpimport pandas as pdtfd = tfp.distributionstfl = tfp.layerstfb = tfp.bijectorssns.reset_defaults()sns.set_context(context="talk", font_scale=1)%matplotlib inline%config InlineBackend.figure_format='retina'
Creating a dataset
Let us create a dataset. We will assume the coin toss to be given as per the Bernoulli distribution. We will assume that \(\theta = p(H) = 0.75\) and generate 10 samples. We will fix the random seeds for reproducibility.
We will be encoding Heads as 1 and Tails as 0.
Code
np.random.seed(0)tf.random.set_seed(0)
Code
distribution = tfd.Bernoulli(probs=0.75)dataset_10 = distribution.sample(10)print(dataset_10.numpy())mle_estimate_10 = tf.reduce_mean(tf.cast(dataset_10, tf.float32))tf.print(mle_estimate_10)
[0 0 0 1 1 1 1 1 0 1]
0.6
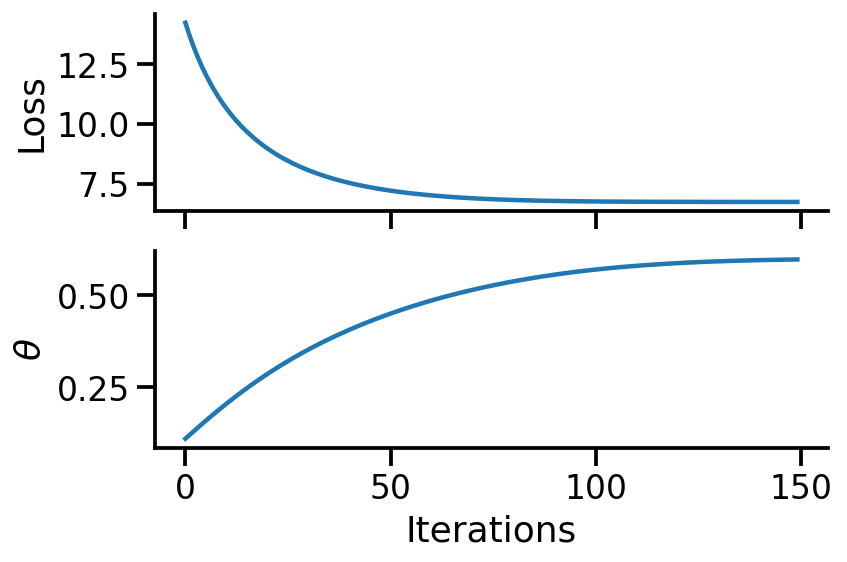
MLE
Obtaining MLE analytically
From the above 10 samples, we obtain 6 Heads (1) and 4 Tails. As per the principal of MLE, the best estimate for \(\theta = p(H) = \dfrac{n_h}{n_h+n_t} = 0.6\)
We may also notice that the value of 0.6 is far from the 0.75 value we had initially set. This is possible as our dataset is small.
We will now verify if we get the same result using TFP. But, first, we can create a graphical model for our problem.
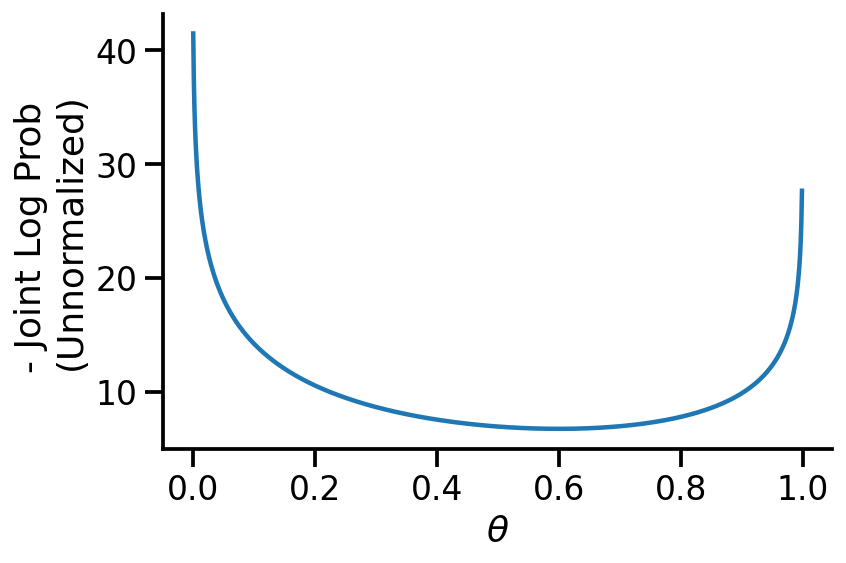
We see above that our MAP estimate is fairly close to the MLE when we used the uniform prior.
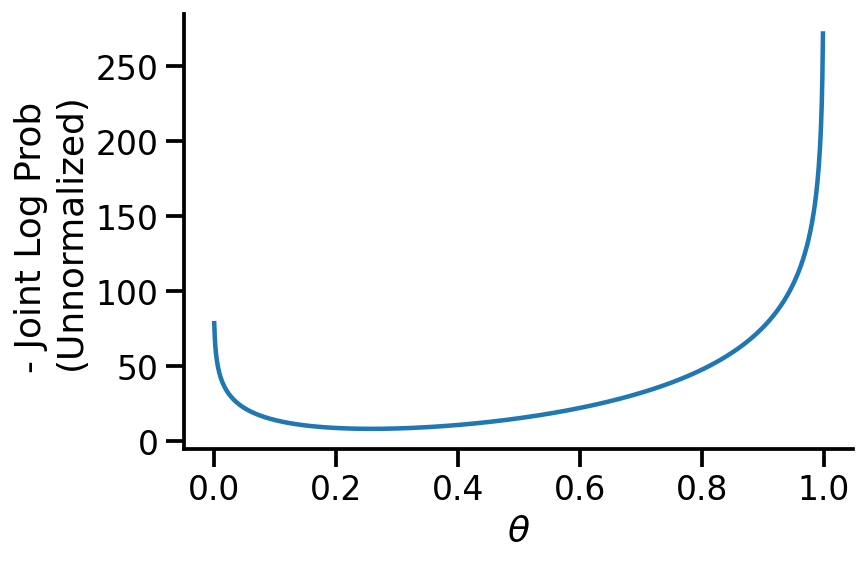
MAP with Beta prior
We will now use a much more informative prior – the Beta prior. We will be setting \(\alpha=40\) and \(\beta=10\) indicating that we have a prior belief that Tails is much more likely than Heads. This is a bad assumption and in the limited data regime will lead to poor estimates.
We now see that our MAP estimate for \(\theta\) is 0.25, which is very far from the MLE. Choosing a better prior would have led to better estimates. Or, if we had more data, the likelihood would have dominated over the prior resulting in better estimates.