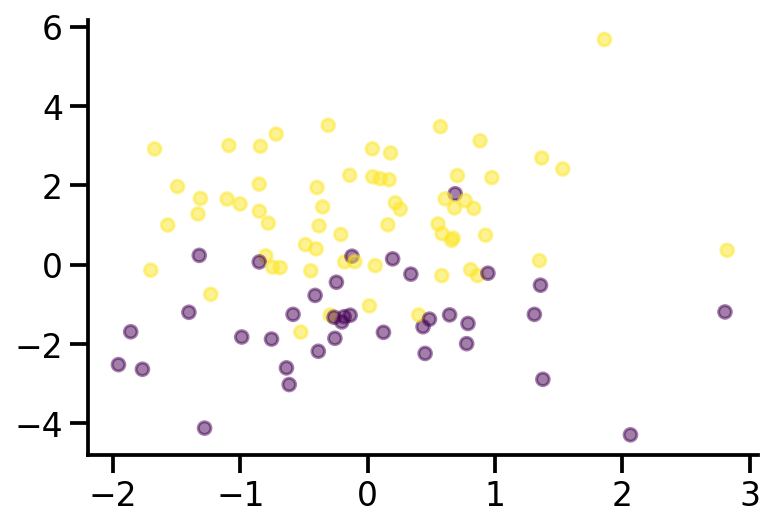
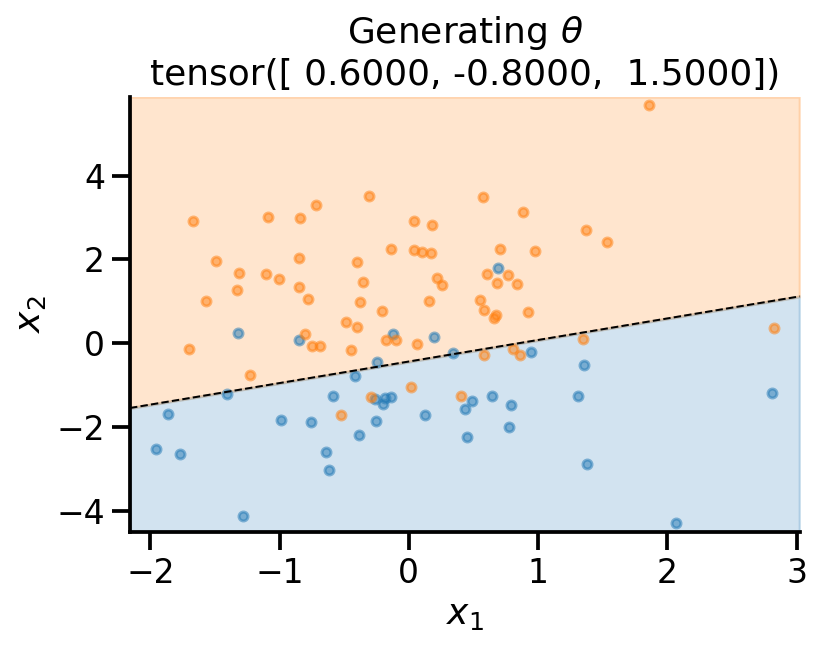
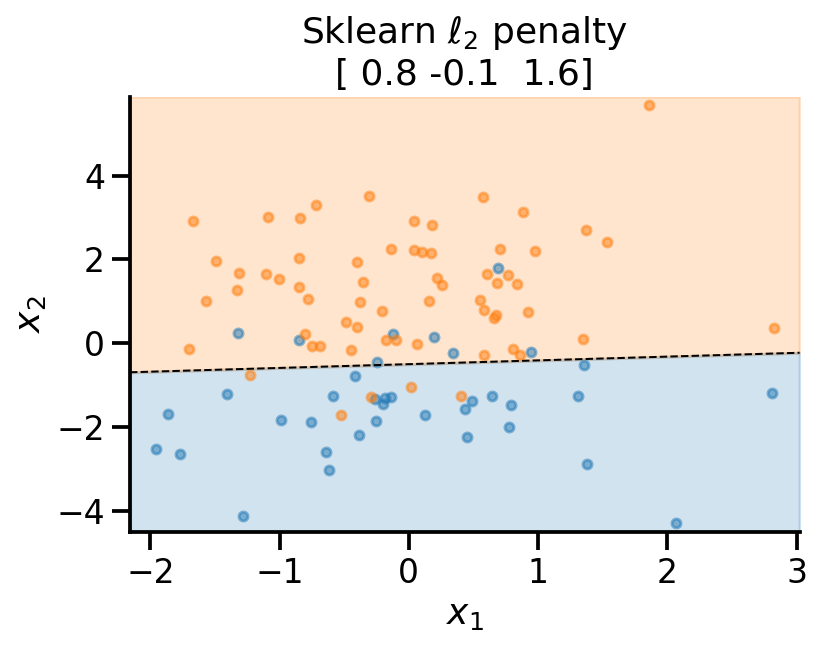
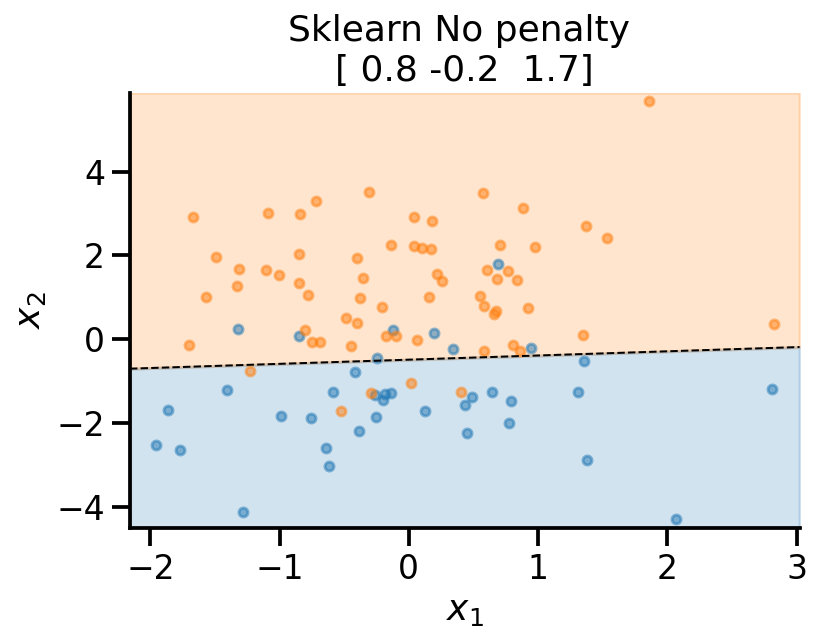
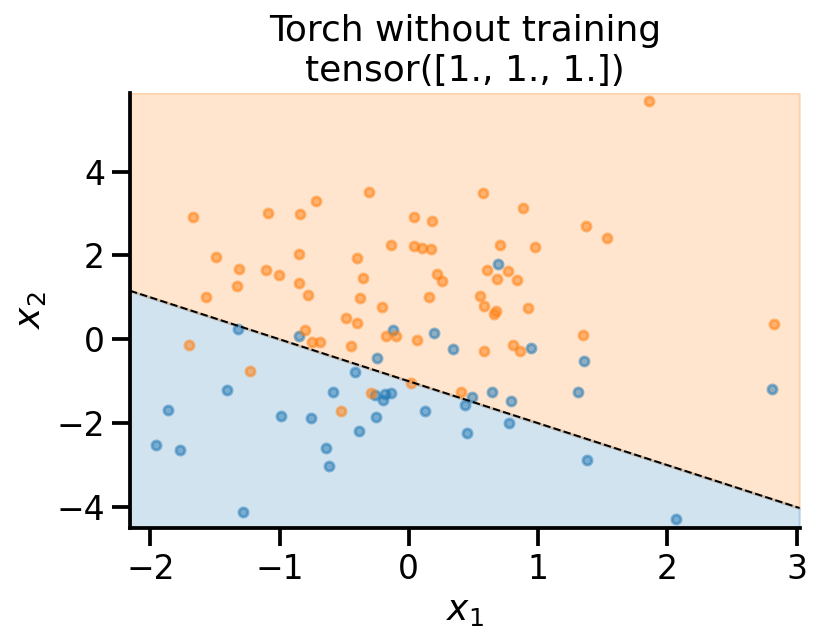
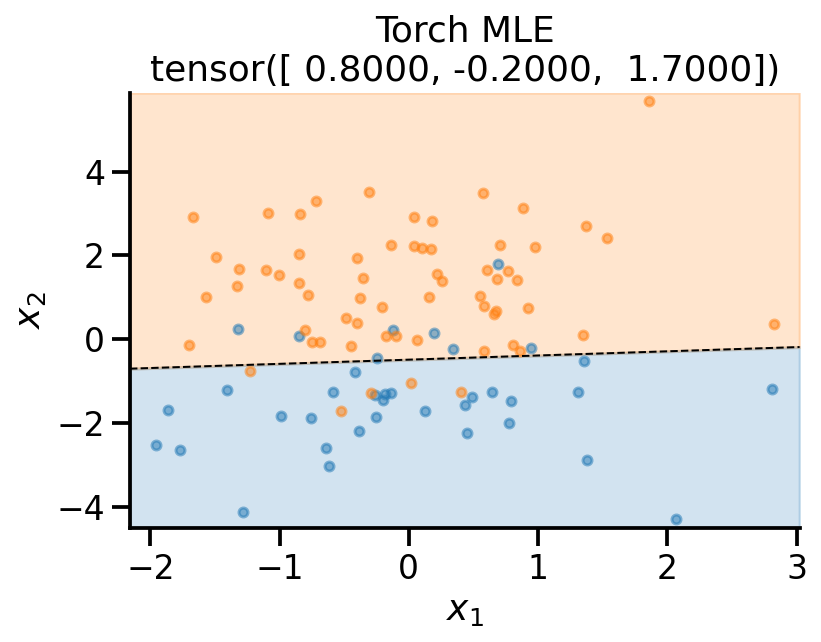
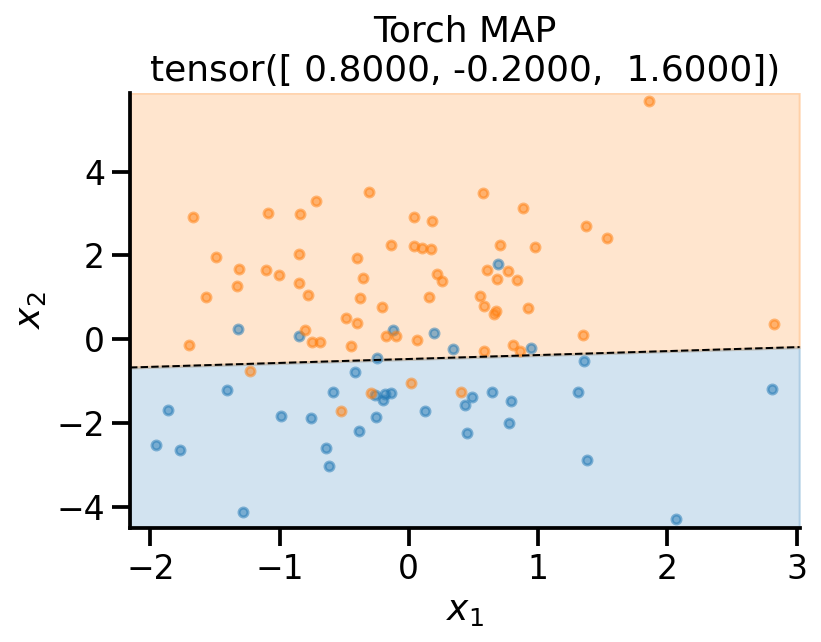
def plot_fit(x_sample, y_sample, theta, model_name):
# Retrieve the model parameters.
b = theta[0]
w1, w2 = theta[1], theta[2]
# Calculate the intercept and gradient of the decision boundary.
c = -b/w2
m = -w1/w2
# Plot the data and the classification with the decision boundary.
xmin, xmax = x_sample[:, 0].min()-0.2, x_sample[:, 0].max()+0.2
ymin, ymax = x_sample[:, 1].min()-0.2, x_sample[:, 1].max()+0.2
xd = np.array([xmin, xmax])
yd = m*xd + c
plt.plot(xd, yd, 'k', lw=1, ls='--')
plt.fill_between(xd, yd, ymin, color='tab:blue', alpha=0.2)
plt.fill_between(xd, yd, ymax, color='tab:orange', alpha=0.2)
plt.scatter(*x_sample[y_sample==0].T, s=20, alpha=0.5)
plt.scatter(*x_sample[y_sample==1].T, s=20, alpha=0.5)
plt.xlim(xmin, xmax)
plt.ylim(ymin, ymax)
plt.ylabel(r'$x_2$')
plt.xlabel(r'$x_1$')
theta_print = np.round(theta, 1)
plt.title(f"{model_name}\n{theta_print}")
sns.despine()