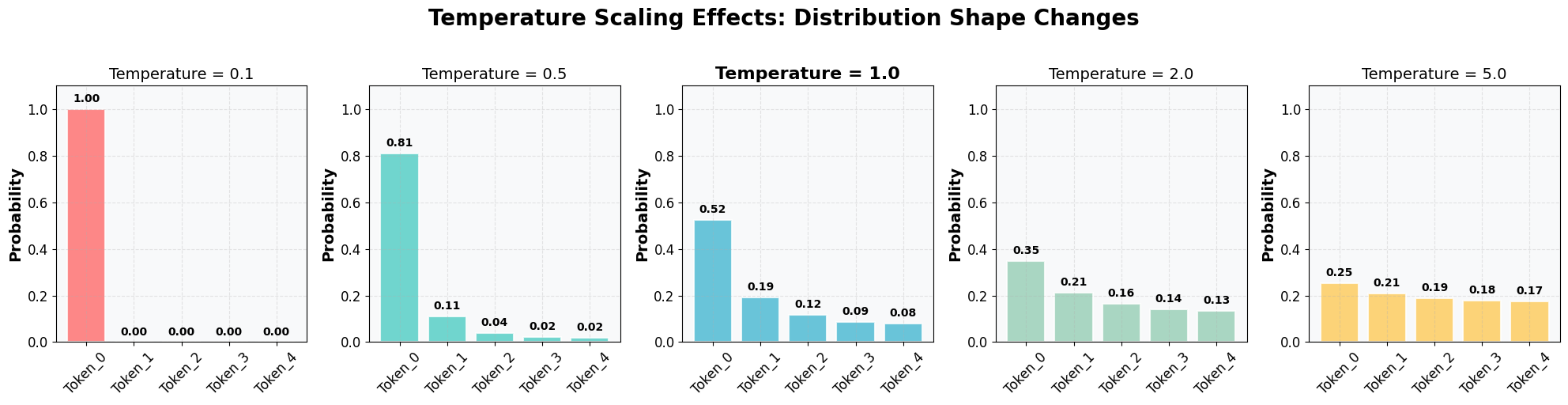
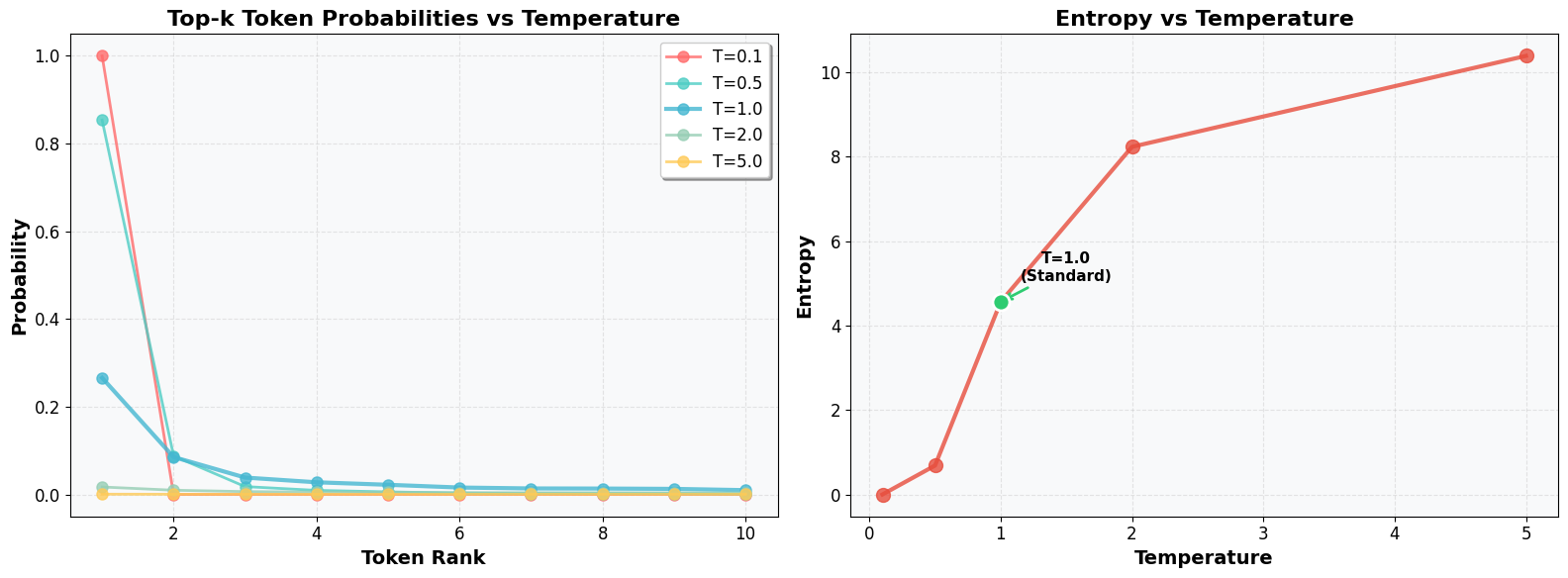
# Function to analyze temperature effects
def analyze_temperature_effects(logits, temperatures, top_k=10):
results = []
for temp in temperatures:
scaled_logits = logits / temp
probs = torch.softmax(scaled_logits, dim=-1)
# Get top-k tokens
top_probs, top_indices = torch.topk(probs[0, -1], k=top_k)
top_tokens = [tokenizer.decode([idx]) for idx in top_indices]
# Calculate entropy
prob_dist = probs[0, -1].cpu().numpy()
entropy_value = entropy(prob_dist)
for i, (token, prob) in enumerate(zip(top_tokens, top_probs)):
results.append({
'temperature': temp,
'token': token,
'probability': prob.item(),
'rank': i + 1,
'entropy': entropy_value
})
return results
# Test with different temperature values
temperatures = [0.1, 0.5, 1.0, 2.0, 5.0]
results = analyze_temperature_effects(logits, temperatures)
# Create prettier visualizations
plt.rcParams.update({
'font.size': 12,
'axes.labelsize': 14,
'axes.titlesize': 16,
'xtick.labelsize': 12,
'ytick.labelsize': 12,
'legend.fontsize': 12,
'figure.titlesize': 18
})
fig, axes = plt.subplots(1, 2, figsize=(16, 6))
# Plot 1: Top-k probabilities with better styling
colors = ['#FF6B6B', '#4ECDC4', '#45B7D1', '#96CEB4', '#FECA57']
for i, temp in enumerate(temperatures):
temp_data = [r for r in results if r['temperature'] == temp]
ranks = [r['rank'] for r in temp_data]
probs = [r['probability'] for r in temp_data]
linewidth = 3 if temp == 1.0 else 2
axes[0].plot(ranks, probs, 'o-', label=f'T={temp}',
color=colors[i], linewidth=linewidth, markersize=8, alpha=0.8)
axes[0].set_xlabel('Token Rank', fontweight='bold')
axes[0].set_ylabel('Probability', fontweight='bold')
axes[0].set_title('Top-k Token Probabilities vs Temperature', fontweight='bold')
axes[0].legend(frameon=True, fancybox=True, shadow=True)
axes[0].grid(True, alpha=0.3, linestyle='--')
axes[0].set_facecolor('#F8F9FA')
# Plot 2: Entropy vs Temperature with better styling
entropies = []
for temp in temperatures:
temp_entropy = [r['entropy'] for r in results if r['temperature'] == temp][0]
entropies.append(temp_entropy)
axes[1].plot(temperatures, entropies, 'o-', color='#E74C3C',
linewidth=3, markersize=10, alpha=0.8)
axes[1].set_xlabel('Temperature', fontweight='bold')
axes[1].set_ylabel('Entropy', fontweight='bold')
axes[1].set_title('Entropy vs Temperature', fontweight='bold')
axes[1].grid(True, alpha=0.3, linestyle='--')
axes[1].set_facecolor('#F8F9FA')
# Highlight T=1.0 on entropy plot
idx_1 = temperatures.index(1.0)
axes[1].scatter(1.0, entropies[idx_1], color='#2ECC71', s=150,
zorder=5, edgecolors='white', linewidth=2)
axes[1].annotate('T=1.0\n(Standard)', xy=(1.0, entropies[idx_1]),
xytext=(1.5, entropies[idx_1] + 0.5),
arrowprops=dict(arrowstyle='->', color='#2ECC71', lw=2),
fontsize=11, ha='center', fontweight='bold')
plt.tight_layout()
plt.show()