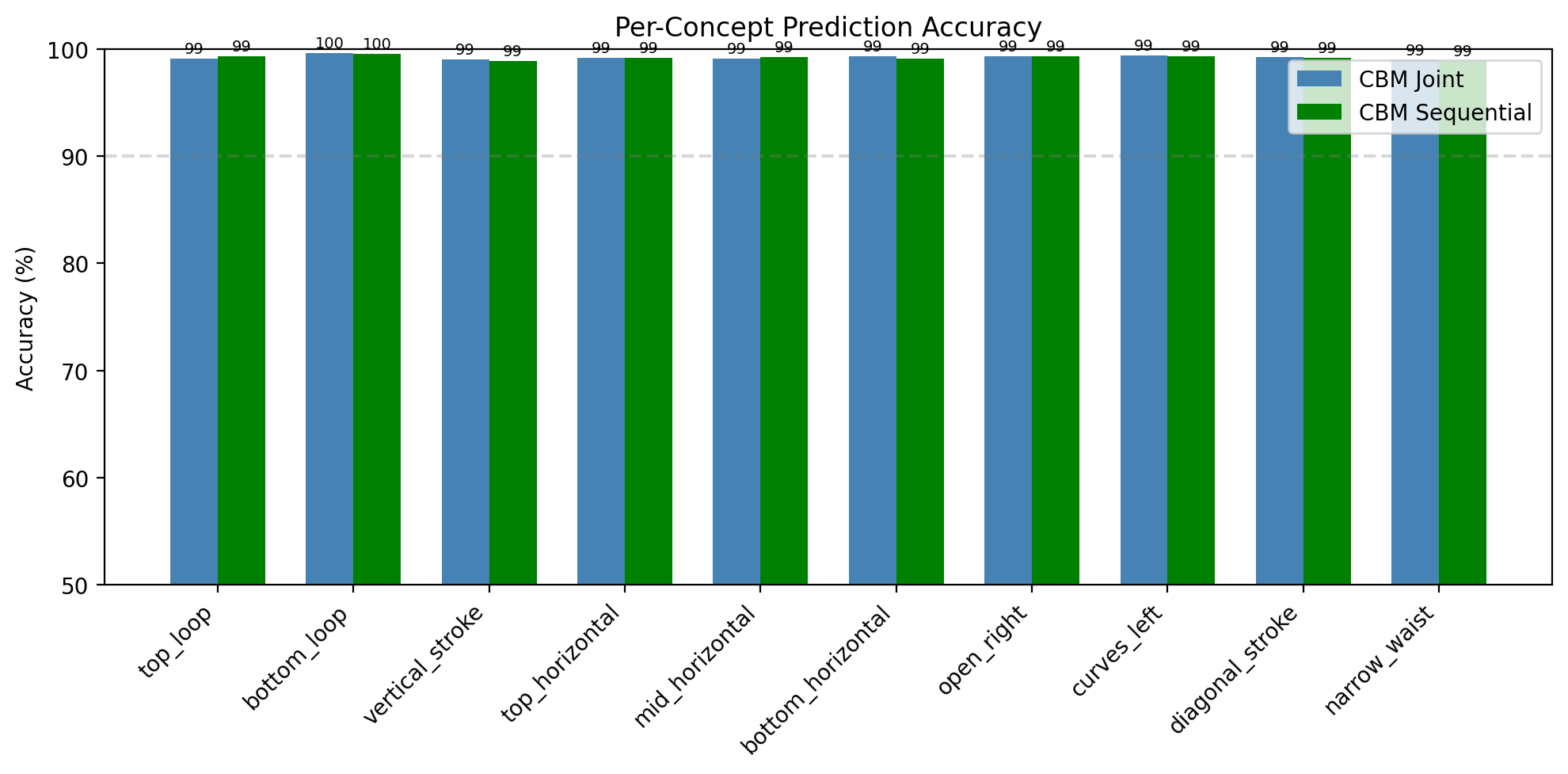
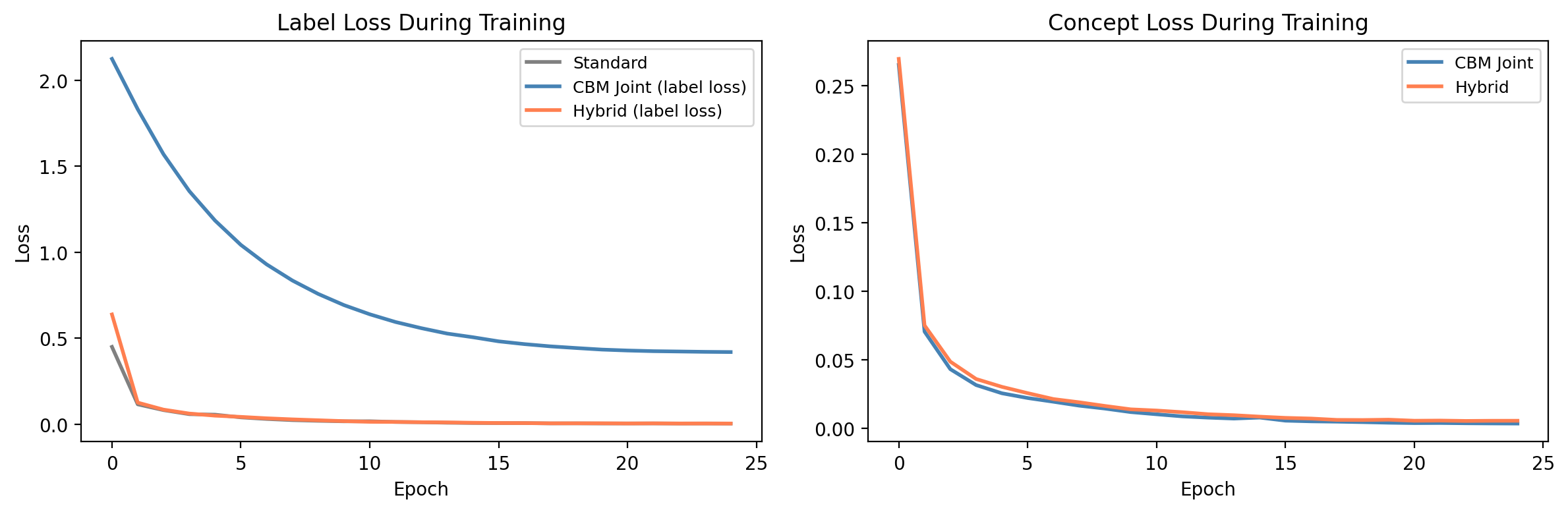
CONCEPT_NAMES = [
"top_loop", "bottom_loop", "vertical_stroke", "top_horizontal",
"mid_horizontal", "bottom_horizontal", "open_right", "curves_left",
"diagonal_stroke", "narrow_waist"
]
NUM_CONCEPTS = len(CONCEPT_NAMES)
NUM_CLASSES = 10
# Each row = digit (0-9), each column = concept
# CRITICAL: every row must be unique!
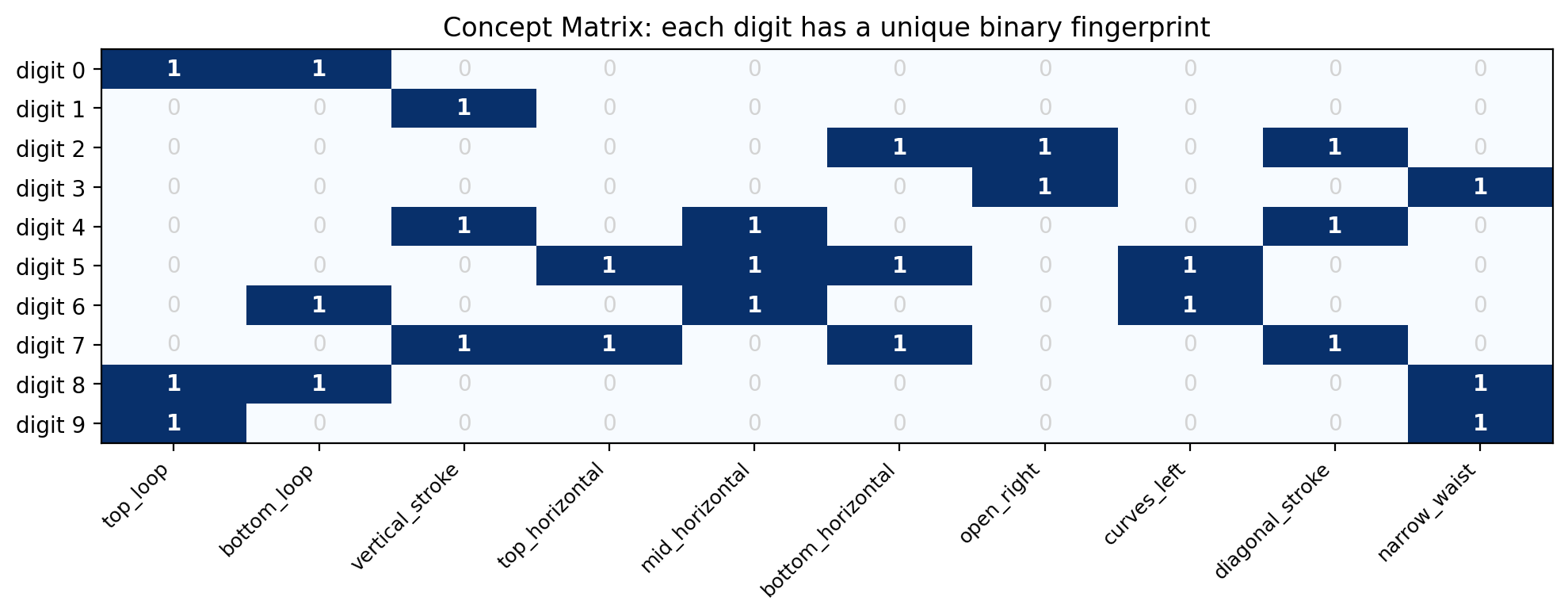
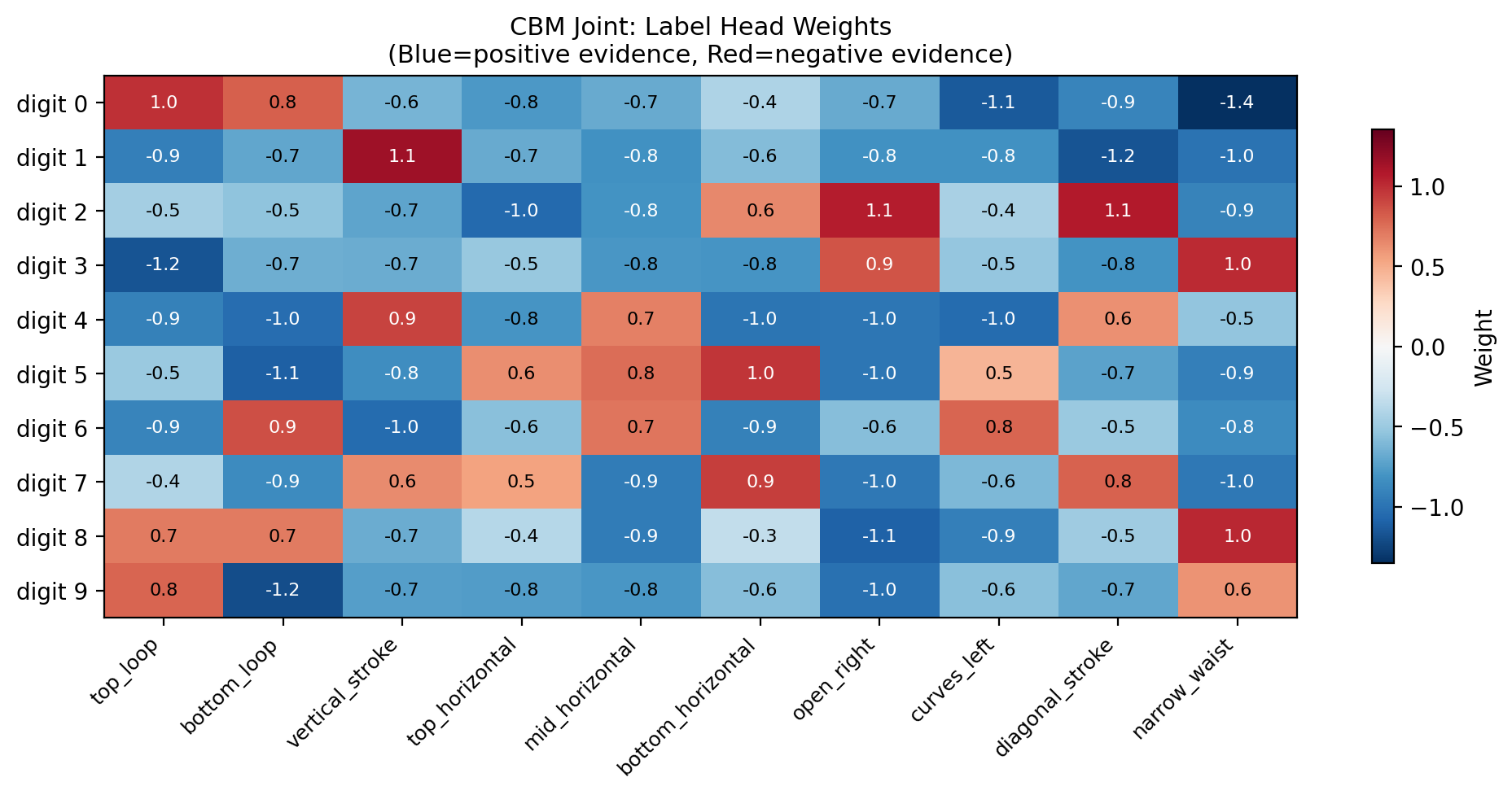
concept_matrix = torch.tensor([
# top_l bot_l vert top_h mid_h bot_h open_r crv_l diag waist
[ 1, 1, 0, 0, 0, 0, 0, 0, 0, 0 ], # 0: two loops, no strokes
[ 0, 0, 1, 0, 0, 0, 0, 0, 0, 0 ], # 1: just a vertical stroke
[ 0, 0, 0, 0, 0, 1, 1, 0, 1, 0 ], # 2: curves right, diagonal, flat bottom
[ 0, 0, 0, 0, 0, 0, 1, 0, 0, 1 ], # 3: open right, narrow waist
[ 0, 0, 1, 0, 1, 0, 0, 0, 1, 0 ], # 4: vertical, mid bar, diagonal
[ 0, 0, 0, 1, 1, 1, 0, 1, 0, 0 ], # 5: horizontal bars, curves left
[ 0, 1, 0, 0, 1, 0, 0, 1, 0, 0 ], # 6: bottom loop, mid bar, curves left
[ 0, 0, 1, 1, 0, 1, 0, 0, 1, 0 ], # 7: vertical, top & bottom horiz, diagonal
[ 1, 1, 0, 0, 0, 0, 0, 0, 0, 1 ], # 8: two loops + narrow waist
[ 1, 0, 0, 0, 0, 0, 0, 0, 0, 1 ], # 9: top loop + narrow waist
], dtype=torch.float32)
# Verify all rows are unique
for i in range(10):
for j in range(i+1, 10):
assert not torch.equal(concept_matrix[i], concept_matrix[j]), \
f"Collision! Digits {i} and {j} have identical concept vectors"
print("All 10 digits have unique concept signatures.")
def labels_to_concepts(labels):
return concept_matrix[labels]
# Show the matrix
fig, ax = plt.subplots(figsize=(10, 4))
im = ax.imshow(concept_matrix.numpy(), cmap='Blues', aspect='auto')
ax.set_xticks(range(NUM_CONCEPTS))
ax.set_xticklabels(CONCEPT_NAMES, rotation=45, ha='right', fontsize=9)
ax.set_yticks(range(10))
ax.set_yticklabels([f'digit {i}' for i in range(10)])
ax.set_title('Concept Matrix: each digit has a unique binary fingerprint')
for i in range(10):
for j in range(NUM_CONCEPTS):
ax.text(j, i, int(concept_matrix[i, j].item()), ha='center', va='center',
fontsize=10, fontweight='bold' if concept_matrix[i,j] else 'normal',
color='white' if concept_matrix[i,j] else 'lightgray')
plt.tight_layout()
plt.show()