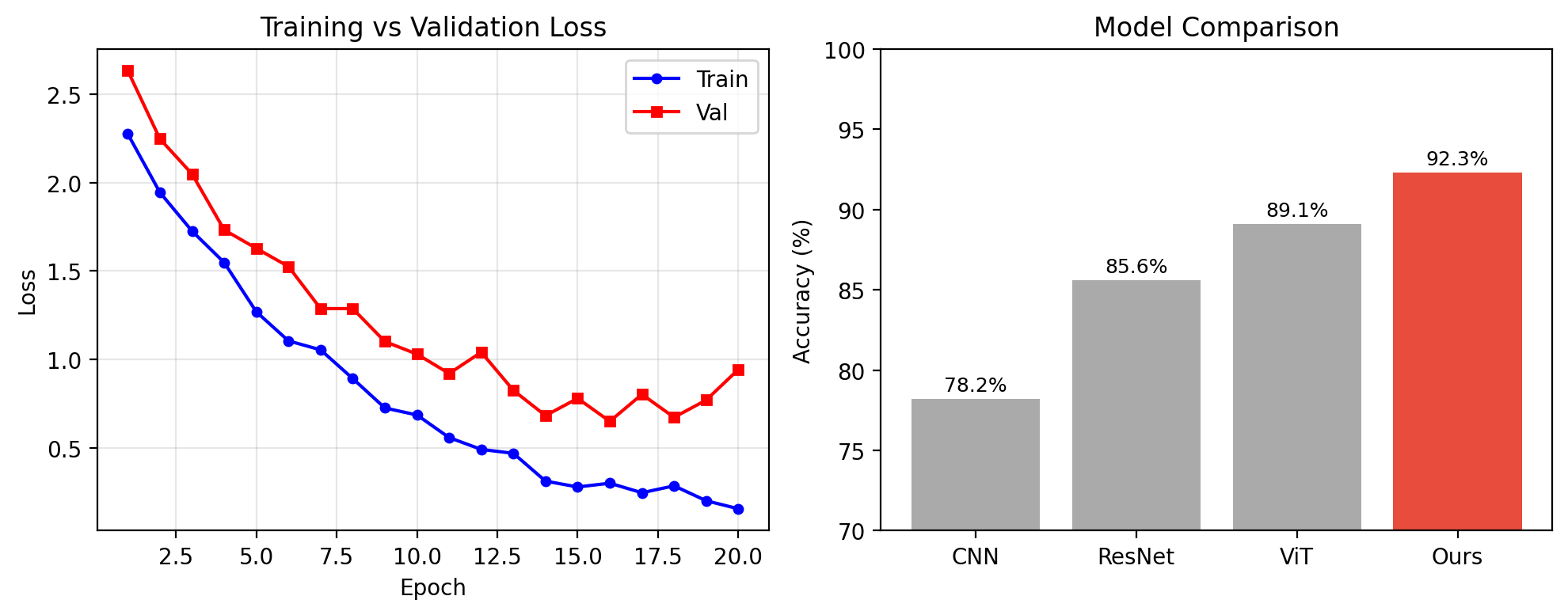
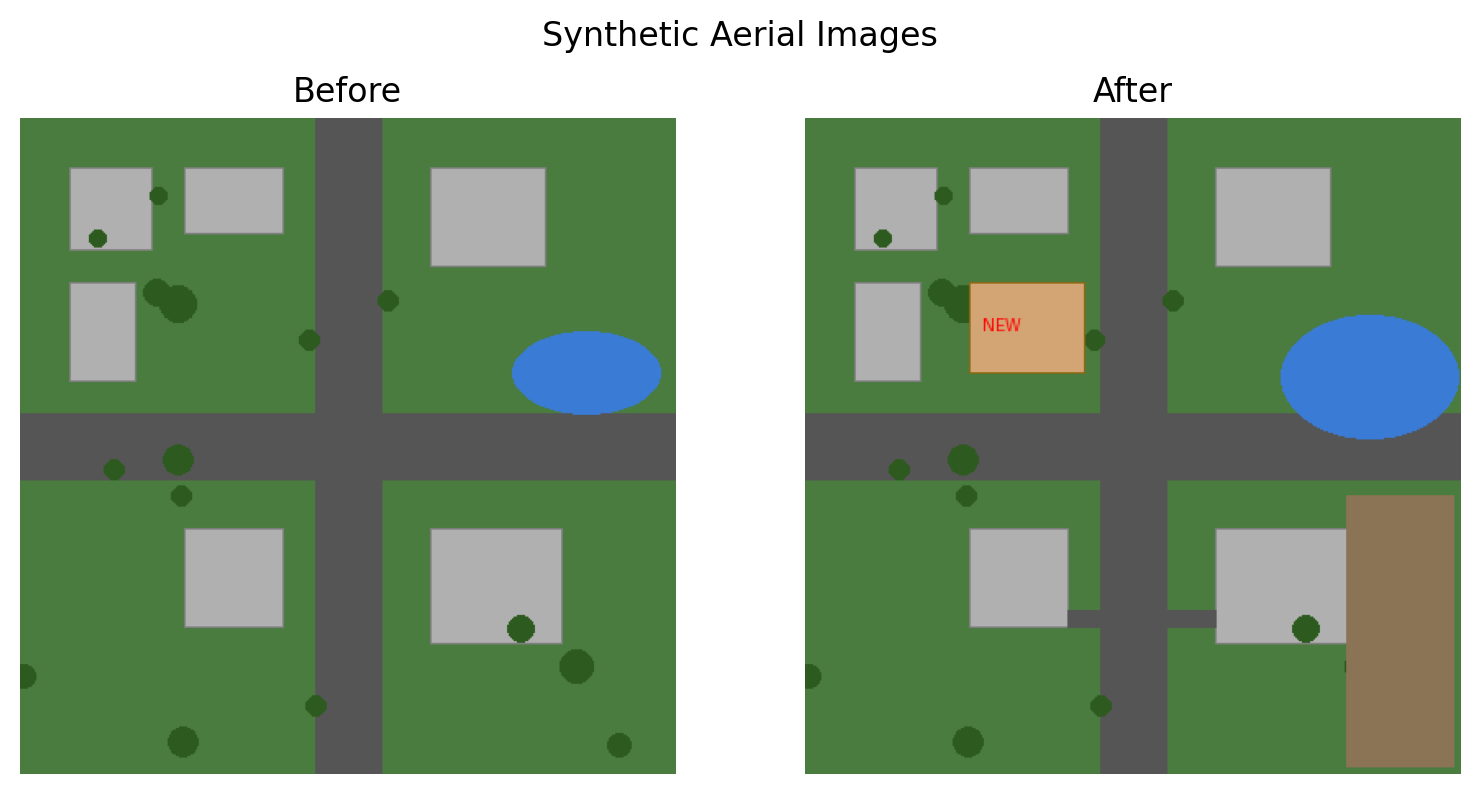
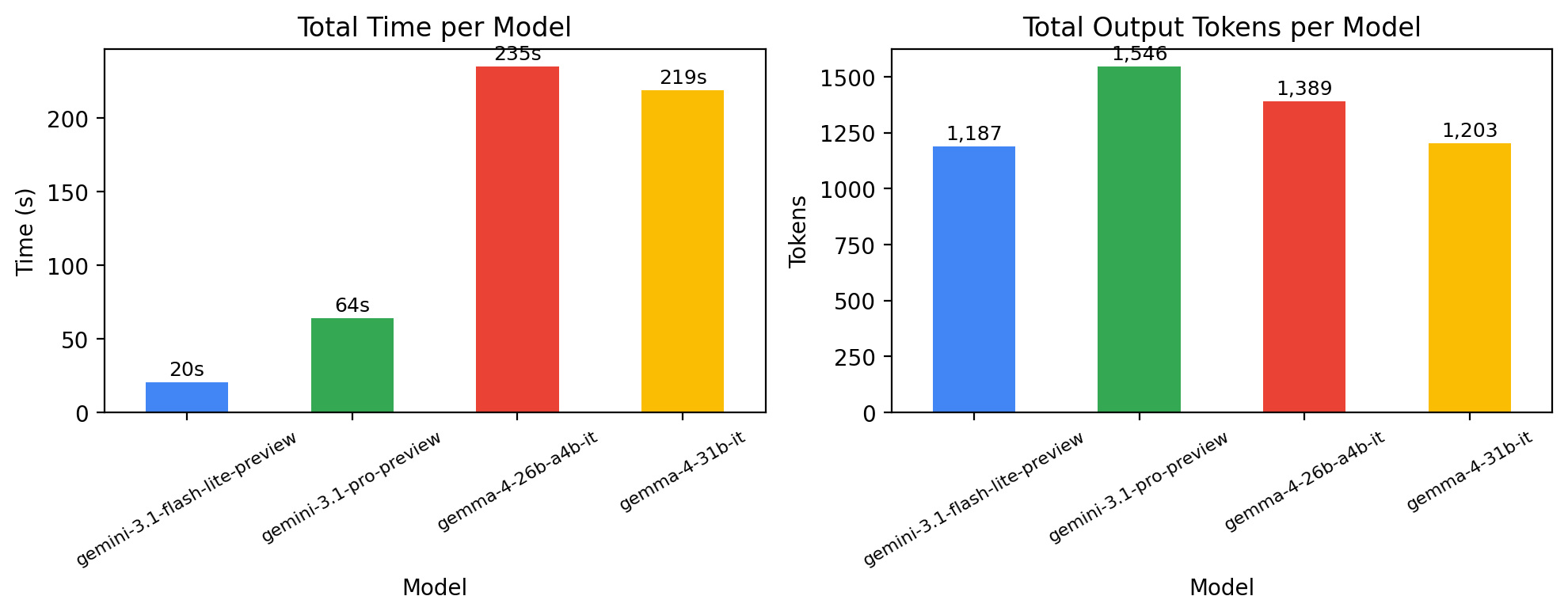
[
{"box_2d": [715, 418, 848, 457], "label": "person"},
{"box_2d": [705, 857, 811, 901], "label": "person"},
{"box_2d": [715, 551, 876, 606], "label": "person"},
{"box_2d": [712, 831, 816, 871], "label": "person"},
{"box_2d": [746, 931, 911, 998], "label": "person"},
{"box_2d": [752, 714, 996, 794], "label": "person"},
{"box_2d": [757, 833, 1000, 975], "label": "person"},
{"box_2d": [763, 376, 1000, 445], "label": "person"},
{"box_2d": [765, 593, 1000, 706], "label": "person"},
{"box_2d": [775, 351, 1000, 416], "label": "person"},
{"box_2d": [775, 204, 1000, 316], "label": "person"},
{"box_2d": [776, 45, 1000, 164], "label": "person"},
{"box_2d": [776, 472, 1000, 572], "label": "person"},
{"box_2d": [687, 342, 793, 381], "label": "person"},
{"box_2d": [687, 683, 762, 724], "label": "person"},
{"box_2d": [688, 319, 790, 356], "label": "person"},
{"box_2d": [691, 522, 794, 562], "label": "person"},
{"box_2d": [692, 437, 806, 474], "label": "person"},
{"box_2d": [694, 276, 828, 318], "label": "person"},
{"box_2d": [694, 392, 791, 427], "label": "person"},
{"box_2d": [695, 497, 783, 533], "label": "person"},
{"box_2d": [701, 0, 886, 67], "label": "person"},
{"box_2d": [701, 71, 839, 121], "label": "person"},
{"box_2d": [706, 931, 856, 997], "label": "person"},
{"box_2d": [711, 452, 812, 494], "label": "person"},
{"box_2d": [712, 115, 875, 167], "label": "person"},
{"box_2d": [712, 171, 913, 236], "label": "person"}
]