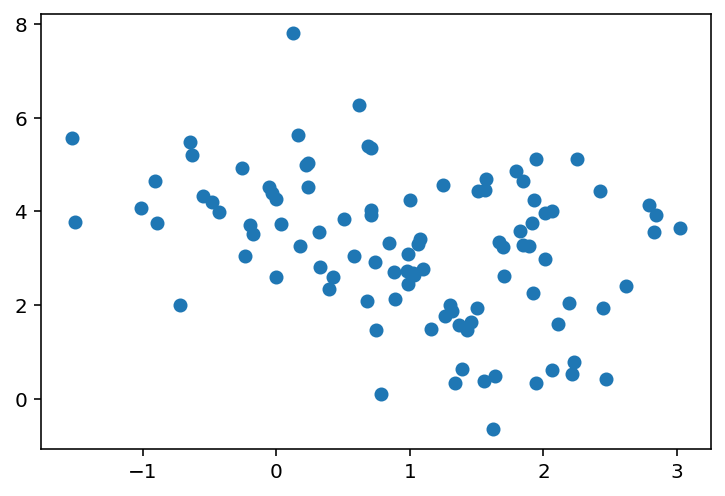
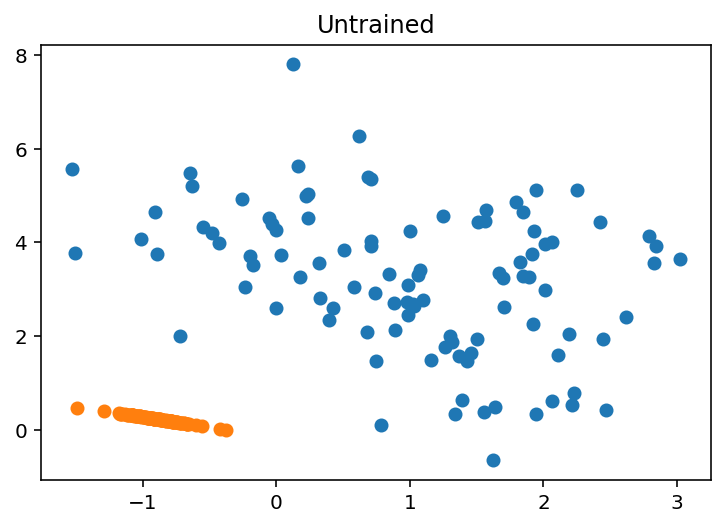
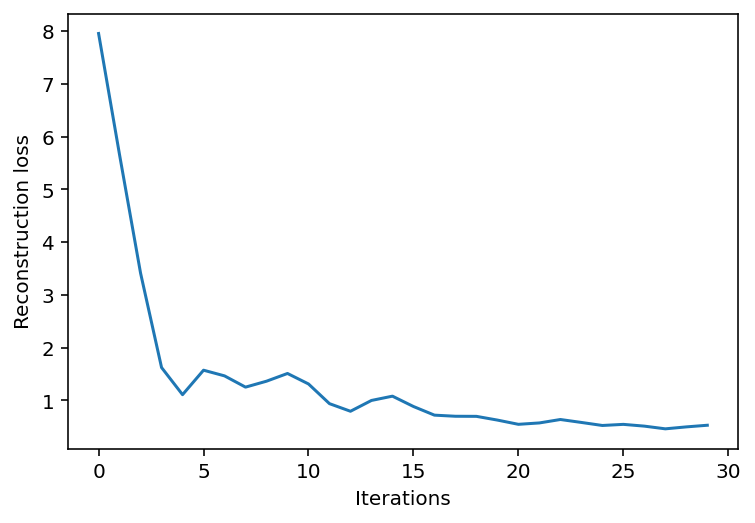
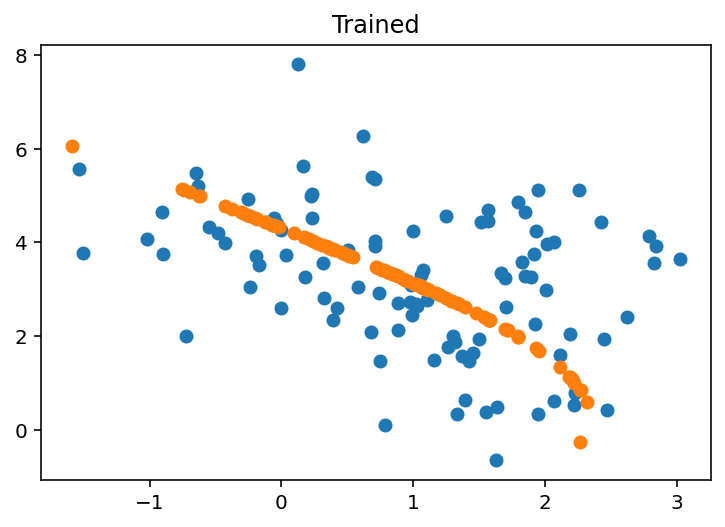
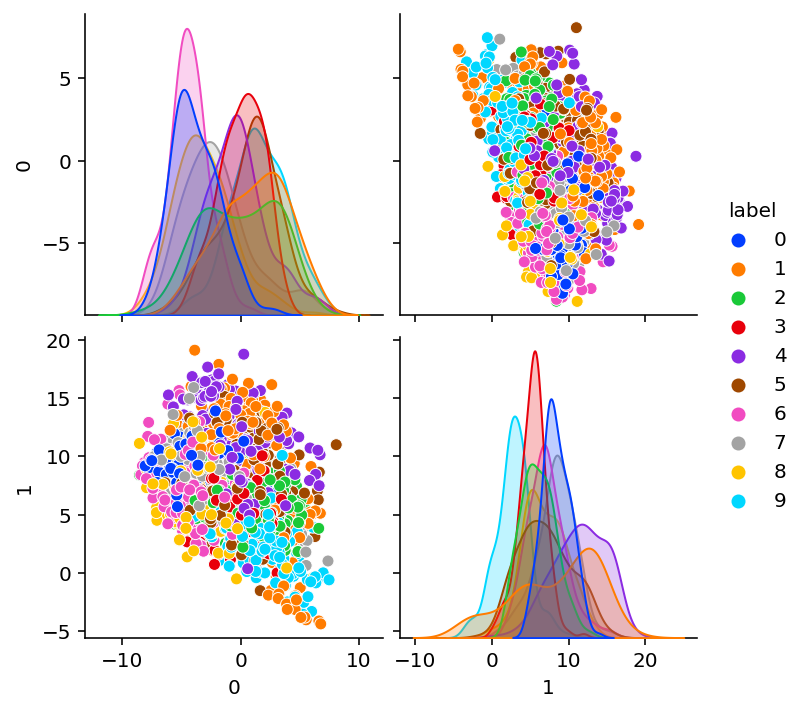
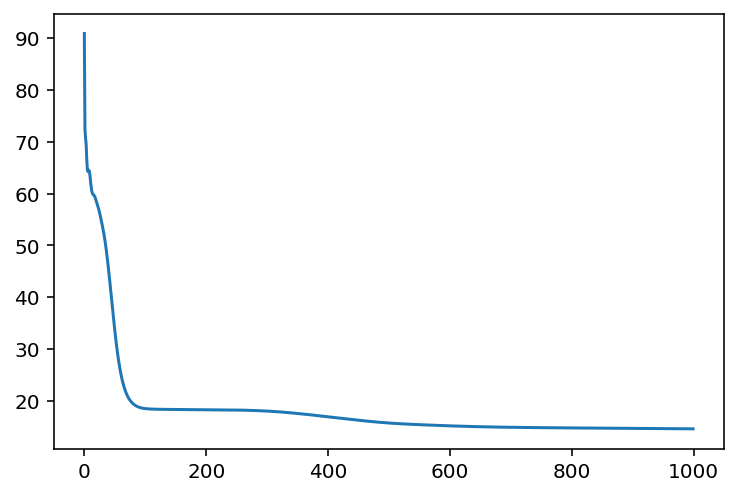
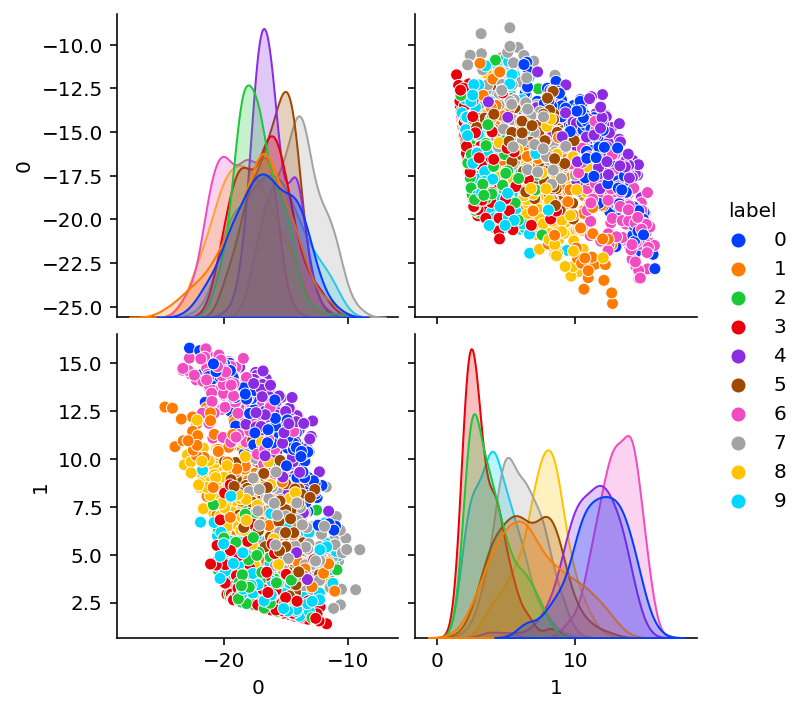
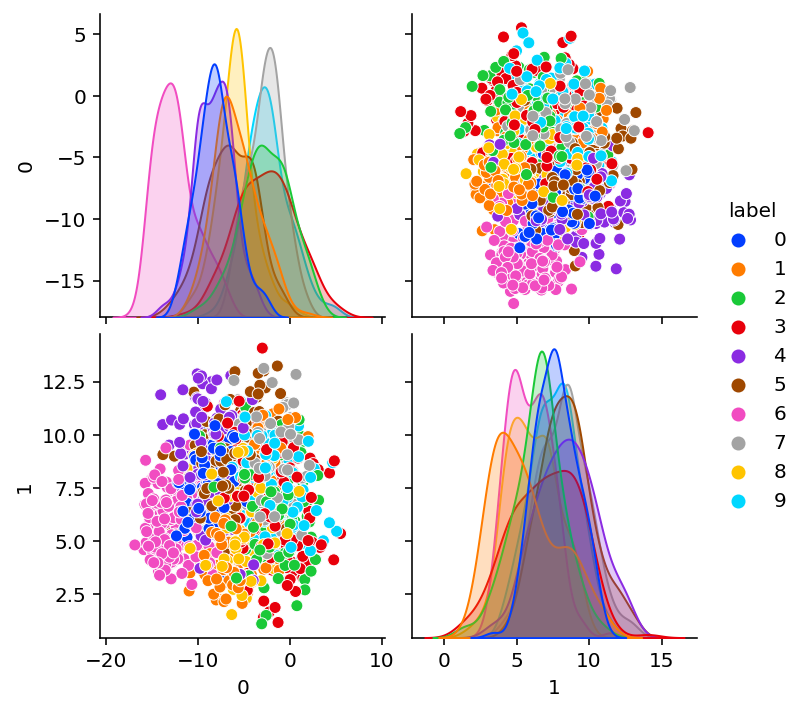
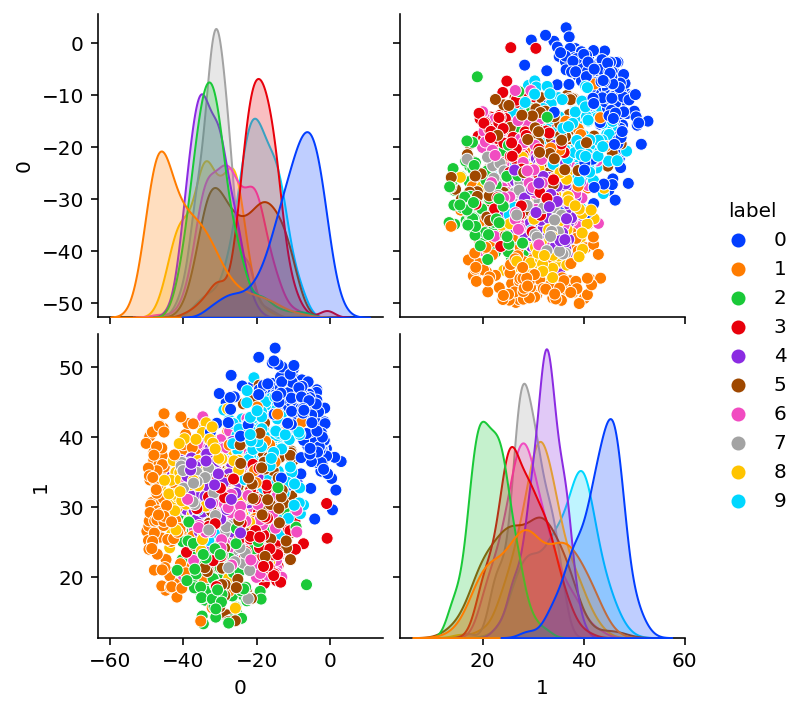
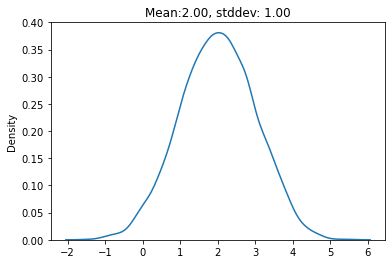
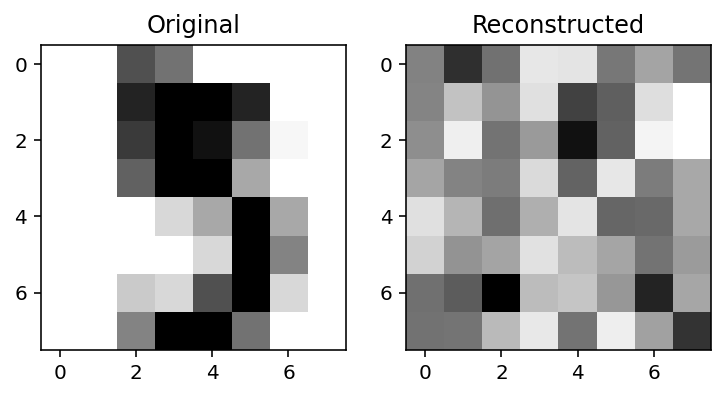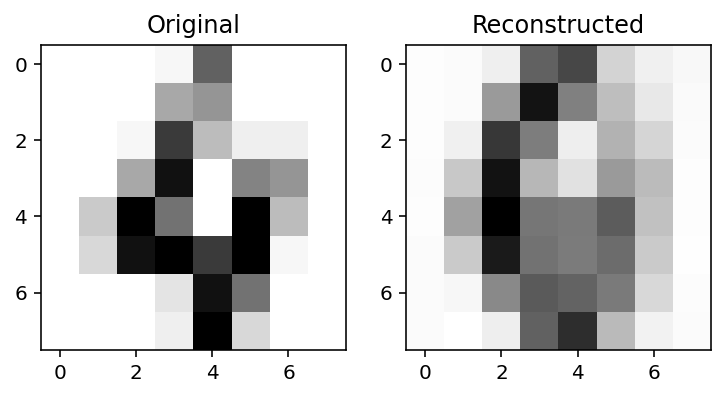DeviceArray([-2.4718695, -2.1964364, -2.6823573, -2.4936147, -1.7122931,
-1.8346143, -2.0767107, -1.8570523, -1.7632042, -2.067935 ,
-2.2317708, -2.14561 , -1.0023856, -2.1458383, -2.3645976,
-1.9418356, -2.7020268, -1.6407721, -1.8281609, -2.2202983,
-2.517499 , -2.5888596, -2.0095935, -2.4470625, -2.18571 ,
-1.9742887, -1.8921608, -2.245328 , -0.8897901, -2.5329056,
-2.2861118, -1.5862433, -2.2295656, -2.496296 , -2.404385 ,
-2.0180435, -1.8416756, -1.858724 , -2.0980945, -1.777173 ,
-2.0027544, -2.1870096, -2.44952 , -1.7563678, -1.5761943,
-2.3097022, -2.0295165, -2.9528203, -2.2042174, -1.9090188,
-1.8868417, -2.4206855, -2.143362 , -1.880422 , -2.5127397,
-2.1454868, -2.0043788, -2.570388 , -2.5082102, -2.3339696,
-1.8621875, -2.4201612, -2.561397 , -2.0498512, -1.6772006,
-1.6392376, -2.3855271, -1.8138398, -3.3776197, -2.3745804,
-2.6683671, -1.8609927, -1.4205931, -1.8123009, -2.236284 ,
-2.2161927, -2.5204146, -2.0504622, -2.1548996, -1.6896895,
-1.3192847, -2.2909331, -2.1295016, -2.0703764, -1.9394028,
-2.041992 , -1.8279521, -1.690125 , -2.7230937, -2.3157165,
-1.7527001, -2.2544892, -2.6310122, -2.0703619, -2.2476096,
-1.8941168, -1.5398859, -1.5742403, -2.375471 , -1.9361446], dtype=float32)