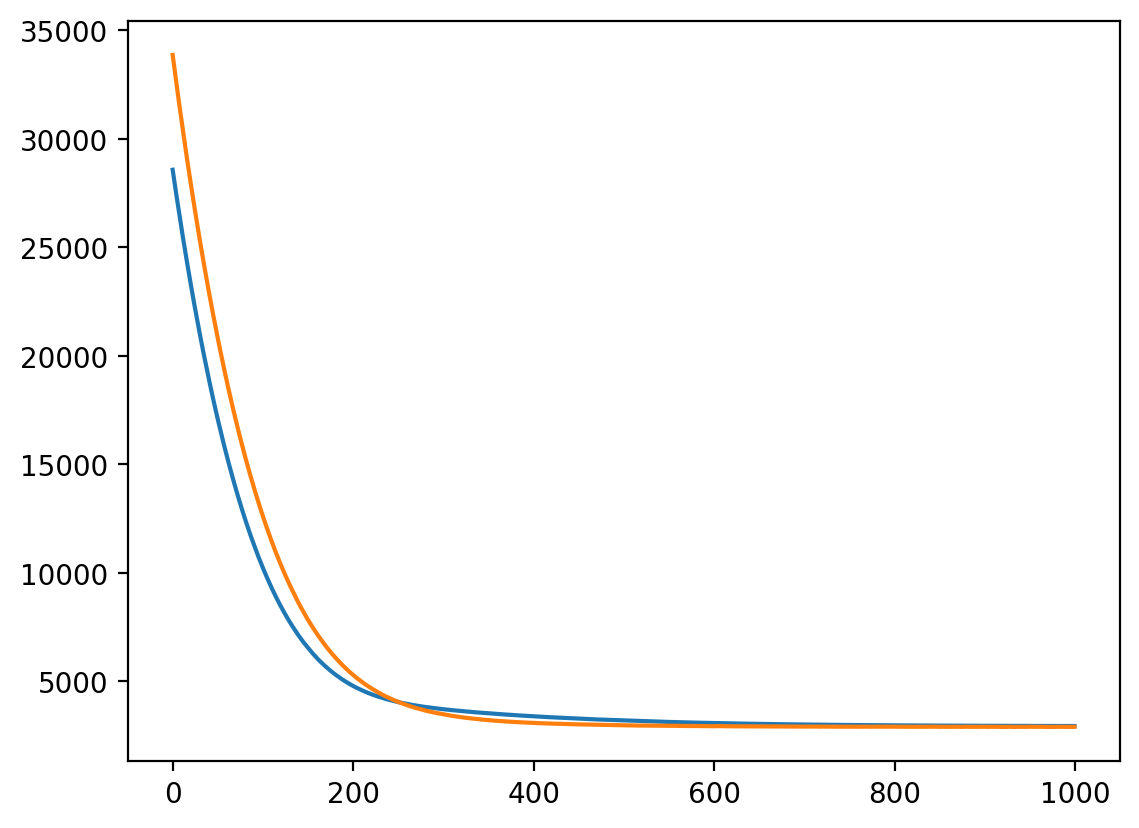
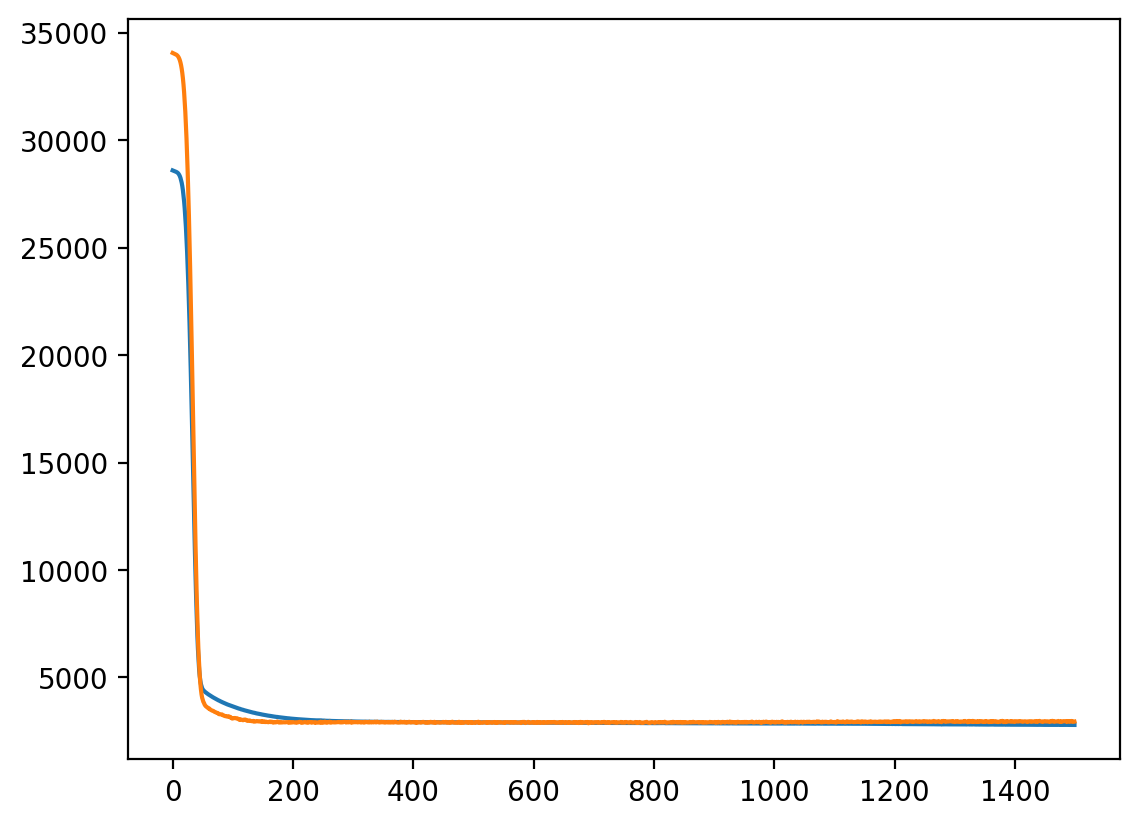
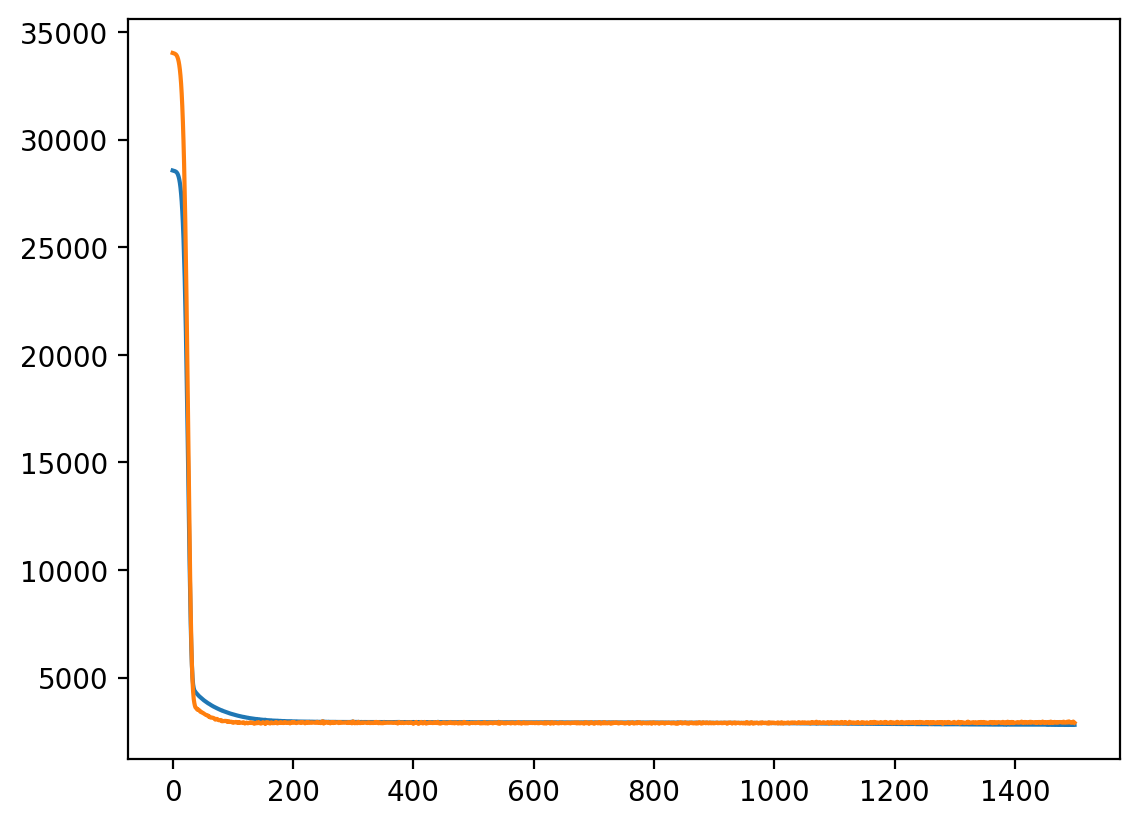
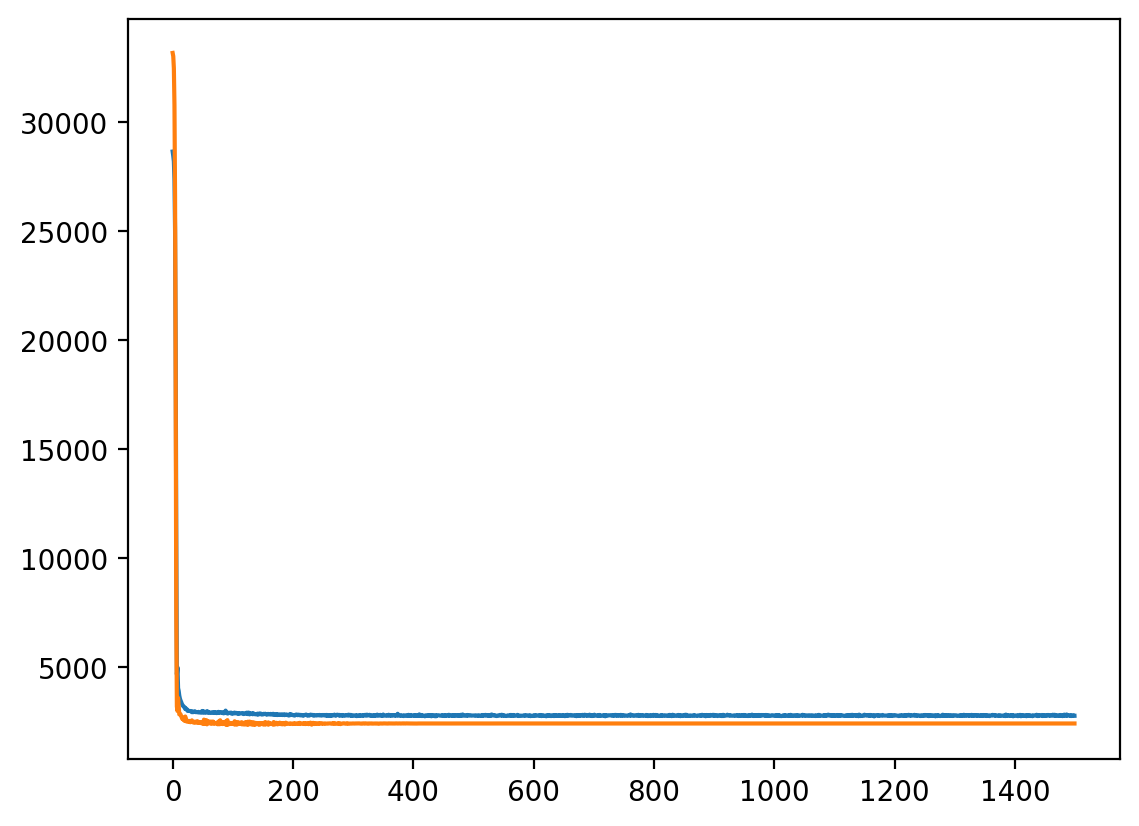
Epoch 100/1500, Train Loss: 3663.8245, Validation Loss: 3086.0981
Epoch 200/1500, Train Loss: 3077.9123, Validation Loss: 2912.6680
Epoch 300/1500, Train Loss: 2952.4684, Validation Loss: 2906.0980
Epoch 400/1500, Train Loss: 2920.8557, Validation Loss: 2916.5231
Epoch 500/1500, Train Loss: 2908.5543, Validation Loss: 2903.3417
Epoch 600/1500, Train Loss: 2898.7857, Validation Loss: 2920.6625
Epoch 700/1500, Train Loss: 2888.3550, Validation Loss: 2886.4415
Epoch 800/1500, Train Loss: 2874.1253, Validation Loss: 2905.2355
Epoch 900/1500, Train Loss: 2866.0193, Validation Loss: 2915.6193
Epoch 1000/1500, Train Loss: 2858.1495, Validation Loss: 2914.3357
Epoch 1100/1500, Train Loss: 2849.0639, Validation Loss: 2919.2359
Epoch 1200/1500, Train Loss: 2835.6841, Validation Loss: 2927.5912
Epoch 1300/1500, Train Loss: 2814.3485, Validation Loss: 2942.1452
Epoch 1400/1500, Train Loss: 2802.6443, Validation Loss: 2928.9871
Epoch 1500/1500, Train Loss: 2789.4206, Validation Loss: 2943.3993