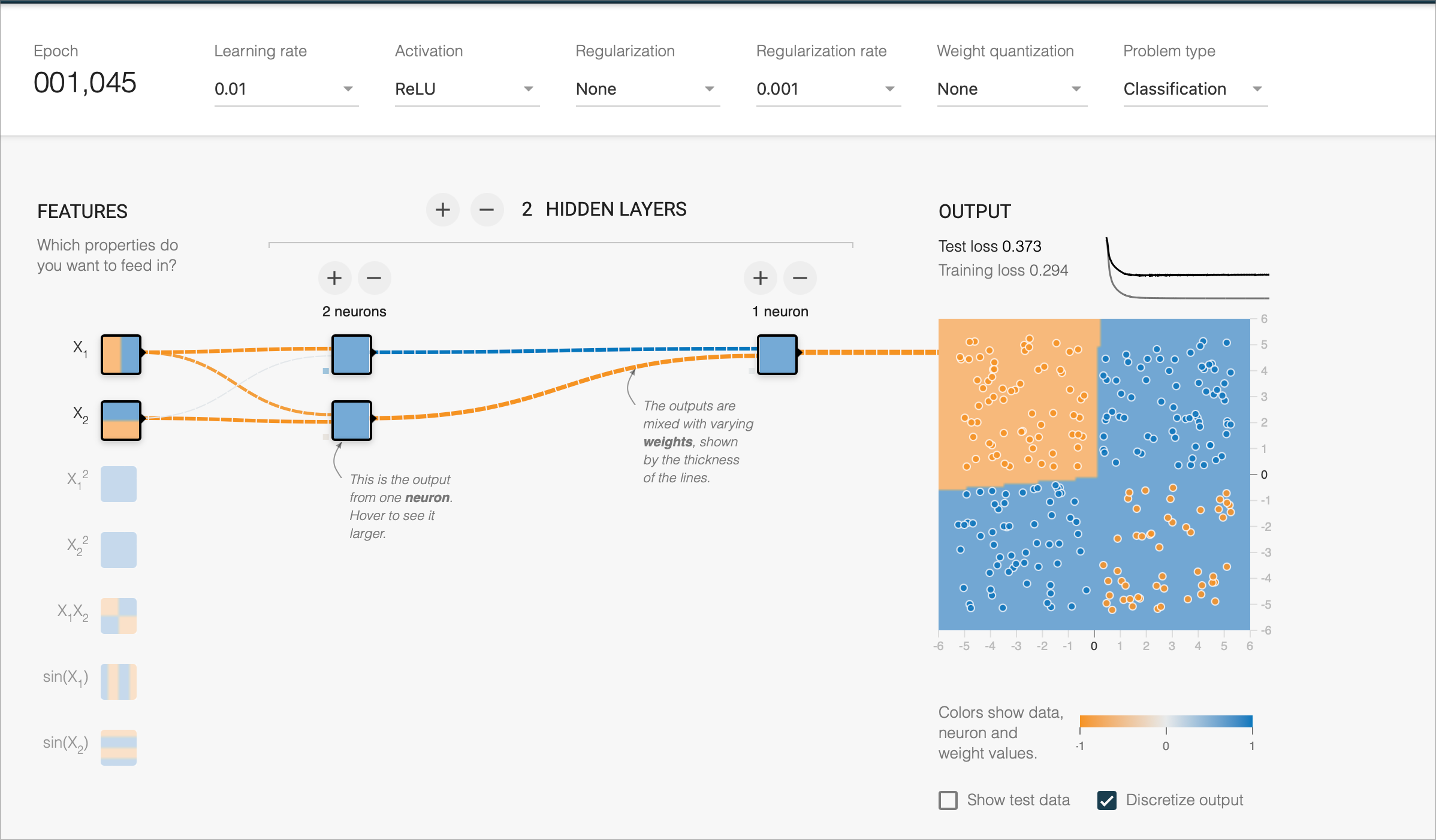
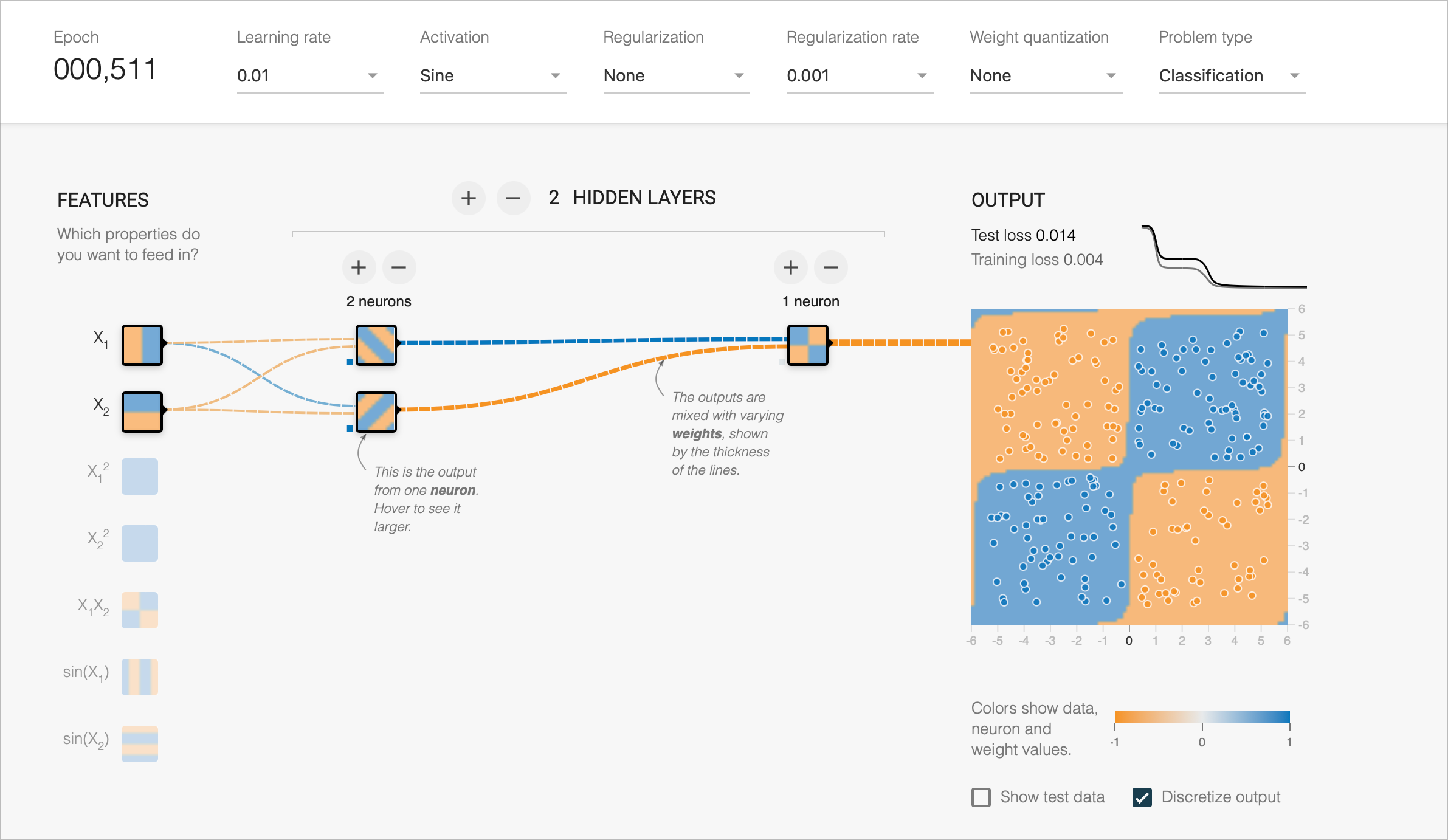
Introduction
In this post, I’m noting some observations from the SIREN paper.
This is based on some quick experiments with their awesome fork of TFPlayground here
OOD
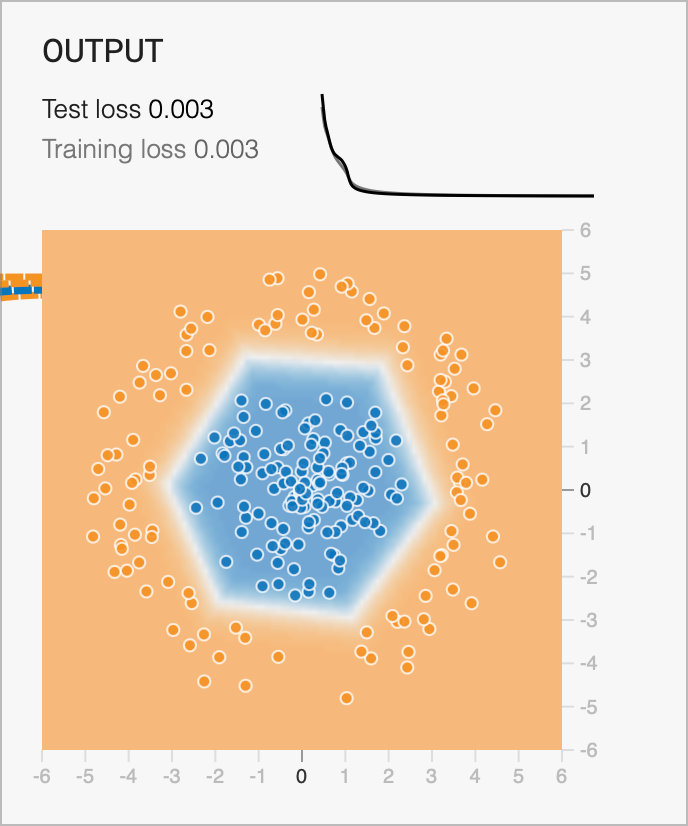
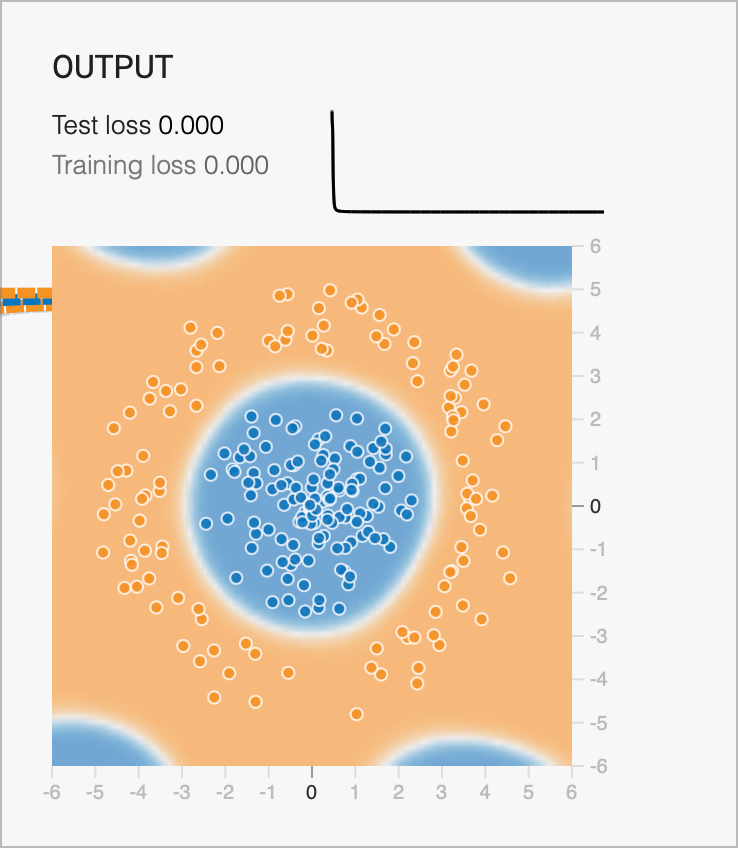
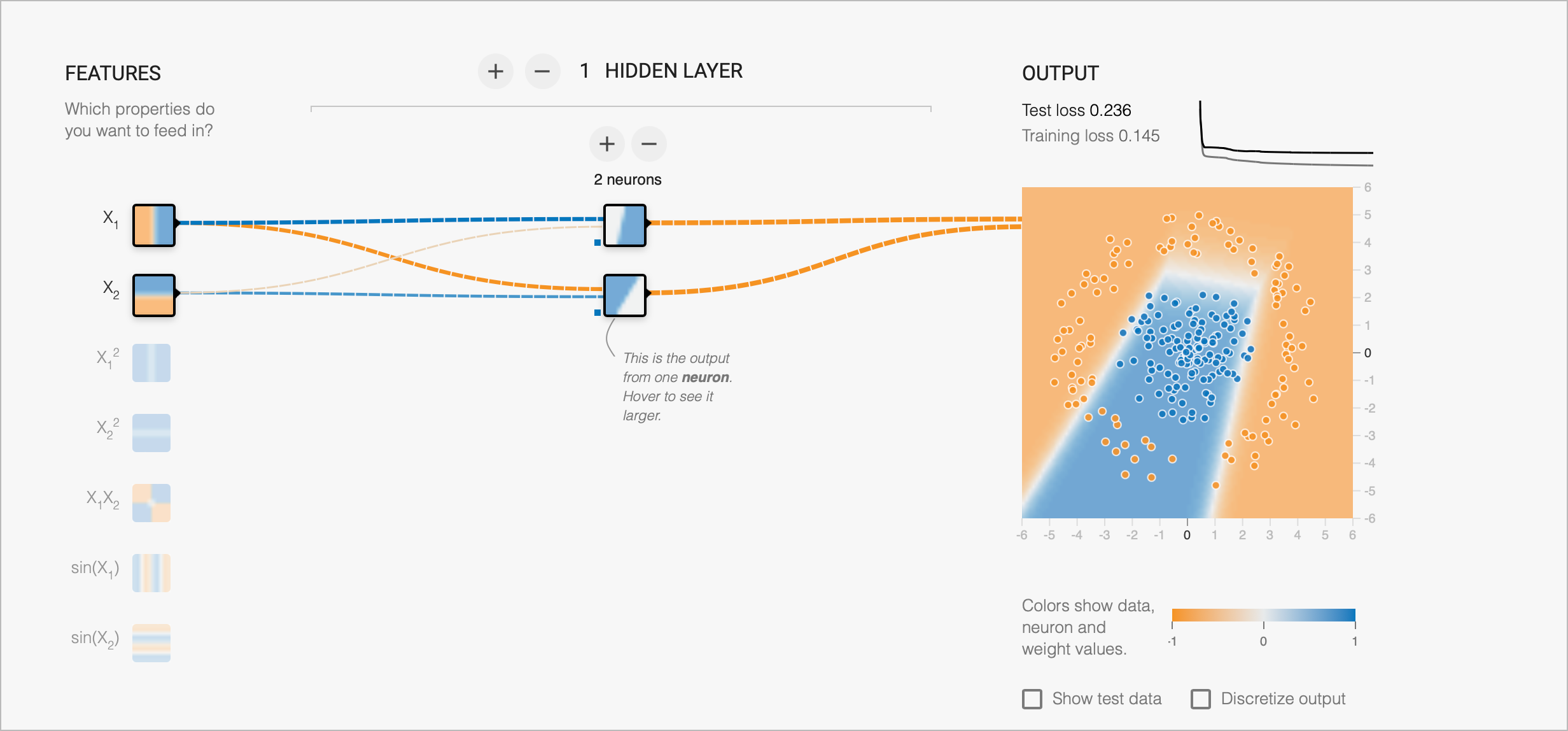
Ability to learn with simple networks
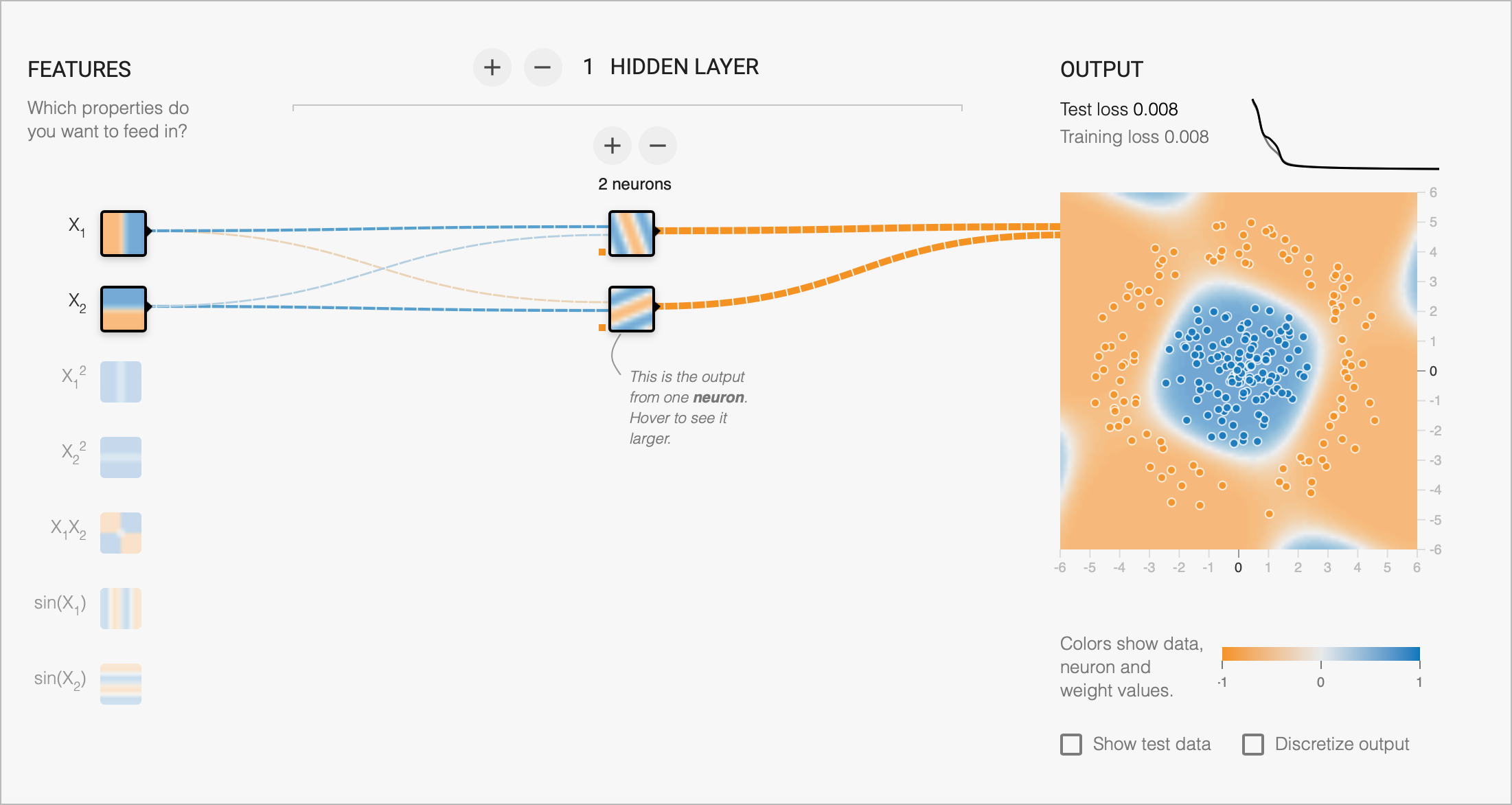
Ability to fit complex functions
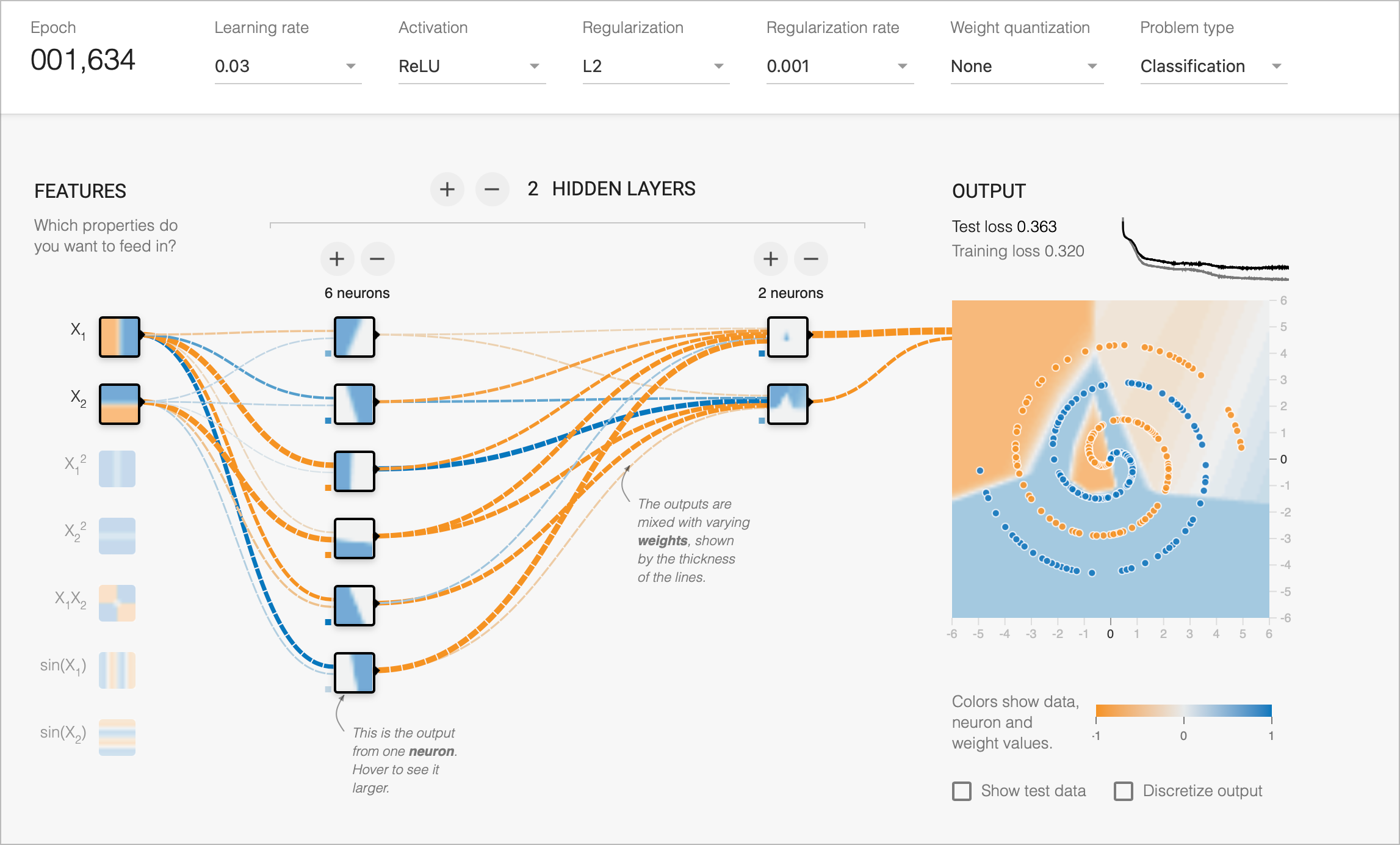
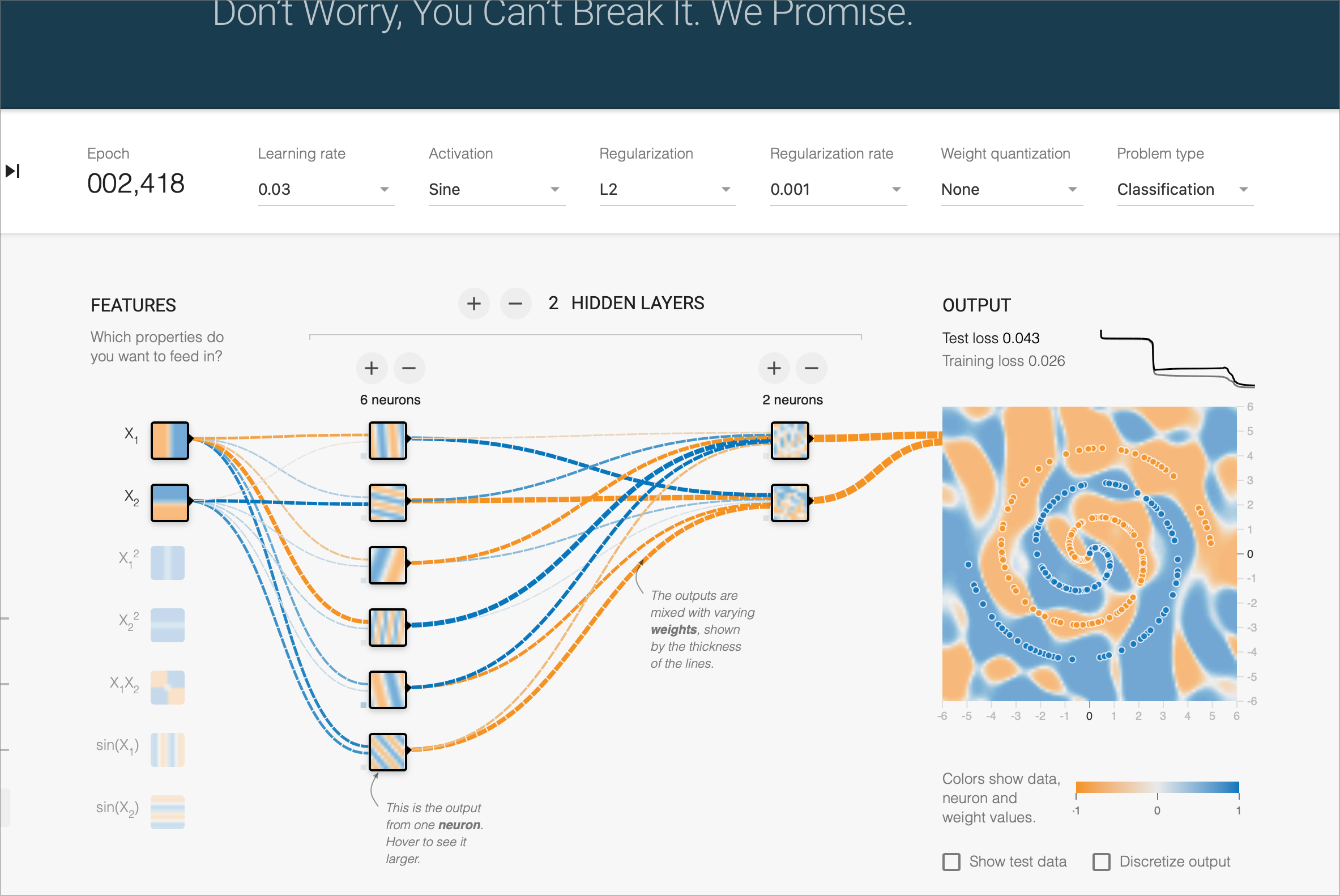
Fitting “speed”