import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
import requests
import os
%config InlineBackend.figure_format = 'retina'The aim of this notebook is to implement a Vision Transformer (ViT) from scratch using PyTorch. We will go through the key steps involved in building a ViT model, including patch embedding, positional encoding, self-attention, and the final classification head.
download_url = "https://images.unsplash.com/photo-1503023345310-bd7c1de61c7d"
if not os.path.exists("sample_image.jpg"):
img = Image.open(requests.get(download_url, stream=True).raw)
img.save("sample_image.jpg")
img = Image.open("sample_image.jpg")img_np = np.array(img)
plt.figure(figsize=(4,4))
plt.imshow(img_np)
plt.title(f"Original image {img_np.shape})")
plt.axis('off')
# Resize to 224x224
img = img.resize((224, 224))
img_np = np.array(img)
plt.figure(figsize=(4,4))
plt.imshow(img_np)
plt.title(f"Resized image {img_np.shape})")
plt.axis('off')
plt.figure(figsize=(4,4))
plt.imshow(img_np)
plt.title(f"Resized image {img_np.shape})")
plt.axis('off')
# draw 16×16 grid lines
for i in range(0, 225, 16):
plt.axhline(i, color='white', lw=0.5)
plt.axvline(i, color='white', lw=0.5)
plt.axis('off')
plt.show()
# Number of patches
num_patches = (224 // 16) * (224 // 16)
print(f"Number of patches: {num_patches} (16x16 pixels each)")Number of patches: 196 (16x16 pixels each)Readying data for PyTorch model 1. permute the image from (H, W, C) to (C, H, W) 2. convert to torch tensor 3. add batch dimension using unsqueeze(0) 4. convert dtype to float
x = torch.tensor(img_np/255.).permute(2,0,1).unsqueeze(0).float()
print(x.shape)torch.Size([1, 3, 224, 224])Using Conv2d to extract patches
patch_size = 16
in_channels = 3
embed_dim = 64
conv = torch.nn.Conv2d(in_channels, embed_dim, kernel_size=patch_size, stride=patch_size)
patches = conv(x)
print(patches.shape) torch.Size([1, 64, 14, 14])print("After Conv2d:", patches.shape)
# flatten to tokens [B, N, D]
patches = patches.flatten(2).transpose(1,2)
print("After flatten (B, N, D):", patches.shape)After Conv2d: torch.Size([1, 64, 14, 14])
After flatten (B, N, D): torch.Size([1, 196, 64])Add CLS token
B, N, D = patches.shape # [1, 196, 64]
cls_token = nn.Parameter(torch.zeros(1, 1, D)) # learnable
print("CLS token shape:", cls_token.shape)
# expand cls_token to batch size
cls_token_expanded = cls_token.expand(B, -1, -1)
print("Expanded CLS token shape:", cls_token_expanded.shape)
# concatenate cls_token to patches
tokens = torch.cat([cls_token_expanded, patches], dim=1) # [1, 197, 64]
print("After adding [CLS] token:", tokens.shape)CLS token shape: torch.Size([1, 1, 64])
Expanded CLS token shape: torch.Size([1, 1, 64])
After adding [CLS] token: torch.Size([1, 197, 64])Add positional embeddings
pos_embed = nn.Parameter(torch.zeros(1, N + 1, D)) # learnable
print("Positional embedding shape:", pos_embed.shape)
# add positional embeddings
tokens = tokens + pos_embed
print("After adding positional embeddings:", tokens.shape)Positional embedding shape: torch.Size([1, 197, 64])
After adding positional embeddings: torch.Size([1, 197, 64])Flatten to get class logits
We mimic the end of ViT: take [CLS] only to linear head.
head = nn.Linear(D, 10) # CIFAR-10 example
cls_output = tokens[:, 0] # [B, D] # take [CLS] token only
print("CLS output shape:", cls_output.shape)
logits = head(cls_output) # [B, 10]
print("Final logits:", logits.shape)CLS output shape: torch.Size([1, 64])
Final logits: torch.Size([1, 10])| Stage | Operation | Shape |
|---|---|---|
| Input image | (B, 3, 224, 224) | |
| Patchify | Conv2d | (B, 64, 14, 14) |
| Flatten | tokens | (B, 196, 64) |
| Add [CLS] | concat | (B, 197, 64) |
| Add position embedding | + | (B, 197, 64) |
| Take CLS → head | Linear | (B, 10) |
| Stage | Operation | Shape |
|---|---|---|
| Input image | (B, 3, 224, 224) | |
| Patchify | Conv2d | (B, 64, 14, 14) |
| Flatten | tokens | (B, 196, 64) |
| Add [CLS] | concat | (B, 197, 64) |
| Add position embedding | + | (B, 197, 64) |
| Take CLS → head | Linear | (B, 10) |
Now, let us create a simple class for this no attention ViT model.
class NoAttentionViT(nn.Module):
"""
Minimal Vision Transformer without attention.
Demonstrates patch embedding, CLS token, and positional encoding only.
"""
def __init__(self, img_size=224, patch_size=16, in_ch=3, embed_dim=64, num_classes=10):
super().__init__()
# Patch embedding: Conv2d with kernel=stride=patch_size
self.patch_embed = nn.Conv2d(in_ch, embed_dim,
kernel_size=patch_size, stride=patch_size)
num_patches = (img_size // patch_size) ** 2
# Learnable CLS token + positional embeddings
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, embed_dim))
# Simple linear head
self.head = nn.Linear(embed_dim, num_classes)
# Initialize (optional)
nn.init.trunc_normal_(self.pos_embed, std=0.02)
nn.init.trunc_normal_(self.cls_token, std=0.02)
def forward(self, x):
B = x.shape[0]
# 1. Patchify
x = self.patch_embed(x) # [B, D, H/P, W/P]
x = x.flatten(2).transpose(1, 2) # [B, N, D]
# 2. Add CLS token
cls = self.cls_token.expand(B, -1, -1)
x = torch.cat([cls, x], dim=1) # [B, N+1, D]
# 3. Add positional embeddings
x = x + self.pos_embed
# 4. Take CLS token only → Linear head
out = self.head(x[:, 0]) # [B, num_classes]
return outmodel = NoAttentionViT(img_size=224, patch_size=16, embed_dim=64, num_classes=10)
dummy = torch.randn(2, 3, 224, 224)
out = model(dummy)
print("Output shape:", out.shape)Output shape: torch.Size([2, 10])Now, let us add attention mechanism to our ViT model. First, let us see how to implement one attention head.
┌────────────────────────────────────────────────────────────┐
│ Input tokens (x) │
│ [CLS] [P1] [P2] [P3] ... [P196] │
└────────────────────────────────────────────────────────────┘
│
▼
┌────────────────────────────────────────────────────────────┐
│ Linear projections (shared for all tokens) │
│ Q = x W_Q , K = x W_K , V = x W_V │
└────────────────────────────────────────────────────────────┘
│
▼
┌────────────────────────────────────────────────────────────┐
│ Compute attention scores: Q × Kᵀ / √D │
│ Each token's query compares with every key → (N×N) map │
└────────────────────────────────────────────────────────────┘
│
▼
┌────────────────────────────┐
│ Softmax over rows │
│ → attention weights │
└────────────────────────────┘
│
▼
┌────────────────────────────────────────────────────────────┐
│ Weighted sum of all V’s │
│ For each token i: yᵢ = Σ_j (attnᵢⱼ × Vⱼ) │
└────────────────────────────────────────────────────────────┘
│
▼
┌────────────────────────────────────────────────────────────┐
│ Output projection: y = (attn @ V) W_O │
└────────────────────────────────────────────────────────────┘
│
▼
┌────────────────────────────────────────────────────────────┐
│ Updated token representations (same shape: N×D) │
│ [CLS'] [P1'] [P2'] ... [P196'] │
└────────────────────────────────────────────────────────────┘
│
▼
CLS' → Linear Head → Class logitsLinear Projections (shared for all tokens)
B, N, D = tokens.shape # [1, 197, 64]
print("Tokens shape (B, N, D):", tokens.shape)
W_q = torch.randn(D, D)
W_k = torch.randn(D, D)
W_v = torch.randn(D, D)
Q = tokens @ W_q # [B, N, D]
K = tokens @ W_k
V = tokens @ W_v
print("Q:", Q.shape, "K:", K.shape, "V:", V.shape)Tokens shape (B, N, D): torch.Size([1, 197, 64])
Q: torch.Size([1, 197, 64]) K: torch.Size([1, 197, 64]) V: torch.Size([1, 197, 64])import math
K_transposed = K.transpose(-2, -1) # [B, N, D] -> [B, D, N]
scores = (Q @ K_transposed) / math.sqrt(D) # [B, N, D] @ [B, D, N] -> [B, N, N]
print("Attention scores:", scores.shape)Attention scores: torch.Size([1, 197, 197])plt.imshow(scores[0].detach().numpy(), cmap='viridis')
plt.colorbar()
plt.title("Attention Scores Heatmap")
plt.xlabel("Key positions")
plt.ylabel("Query positions")Text(0, 0.5, 'Query positions')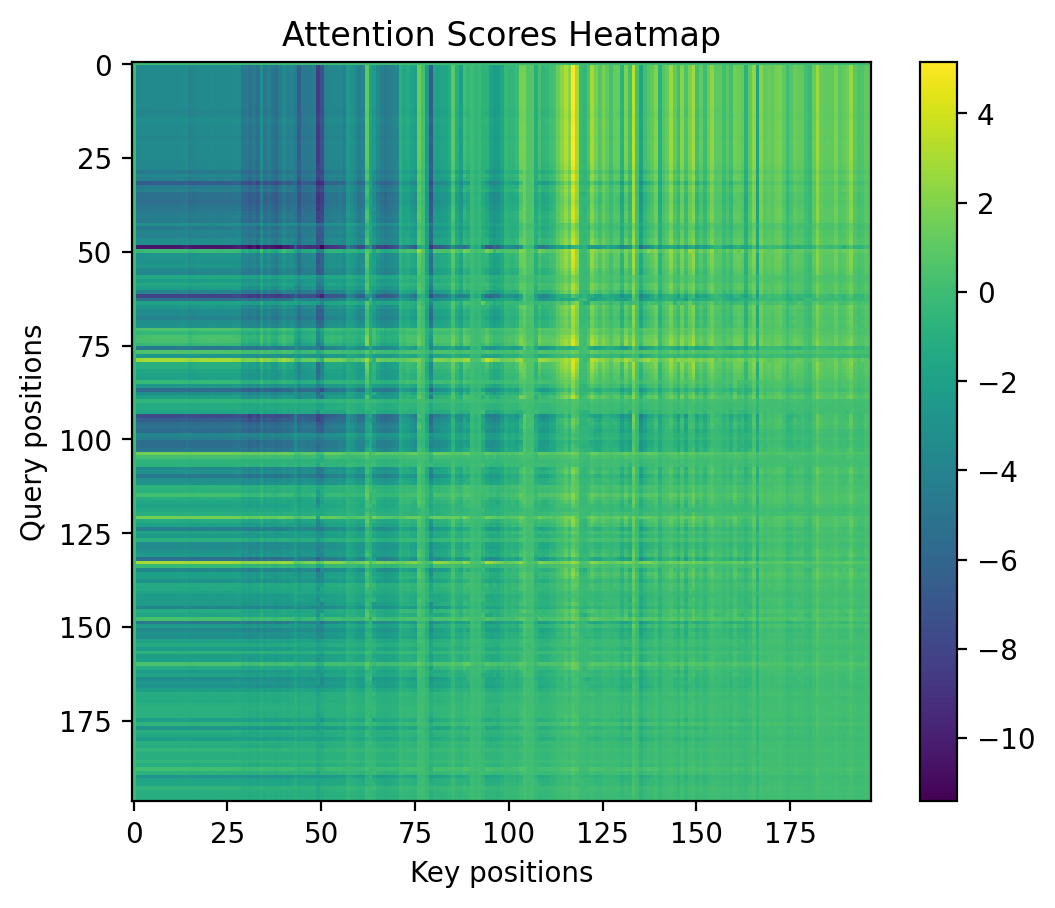
attn = torch.softmax(scores, dim=-1)
print("Attention weights:", attn.shape)Attention weights: torch.Size([1, 197, 197])plt.imshow(attn[0].detach().numpy(), cmap='viridis')
plt.colorbar()
plt.title("Attention Weights Heatmap")
plt.xlabel("Key positions")
plt.ylabel("Query positions")Text(0, 0.5, 'Query positions')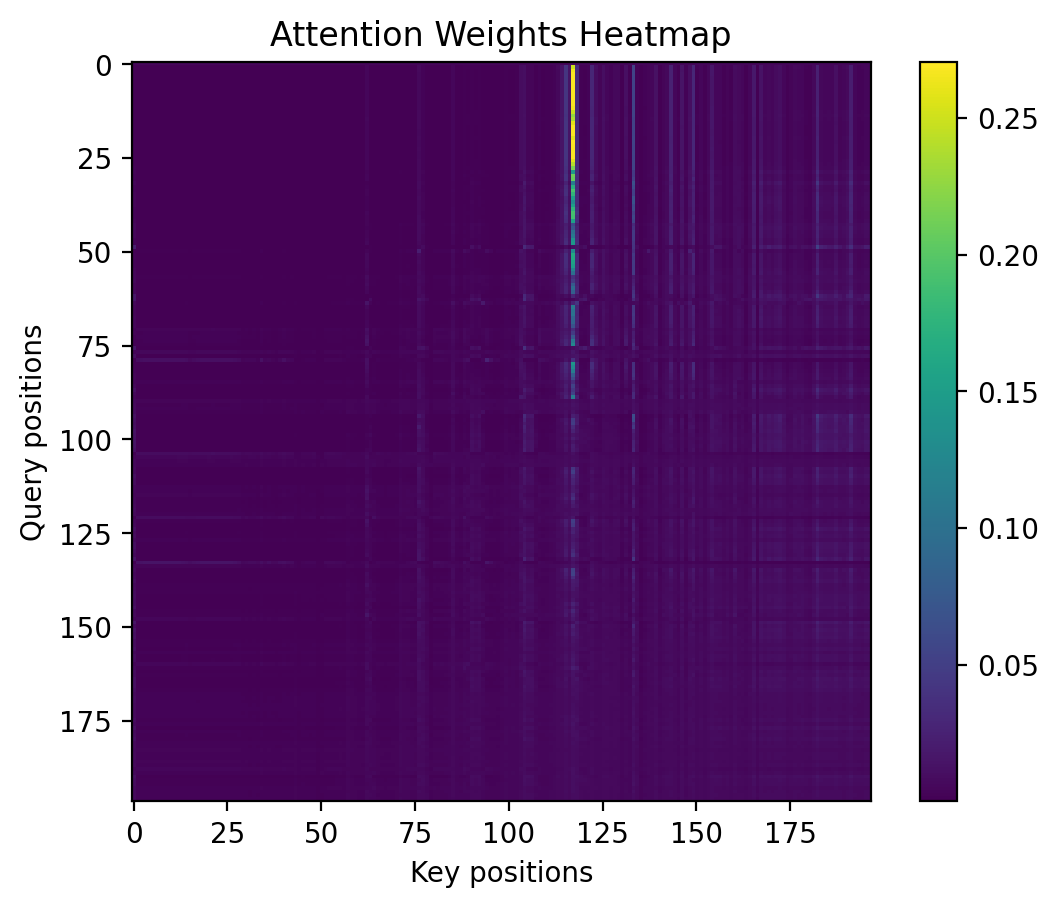
out = attn @ V # [B, N, D]
print("Attention output:", out.shape)Attention output: torch.Size([1, 197, 64])cls_token = out[:, 0] # [B, D]
head = torch.randn(D, 10) # 10 CIFAR classes
logits = cls_token @ head
print("Final logits:", logits.shape)Final logits: torch.Size([1, 10])class SingleHeadAttentionViT(nn.Module):
"""
Simplest Vision Transformer:
- Patchify image using Conv2d
- Add CLS + positional embeddings
- Single-head self-attention (manual)
- Classification head
"""
def __init__(self, img_size=224, patch_size=16, in_ch=3,
embed_dim=64, num_classes=10):
super().__init__()
self.embed_dim = embed_dim
# 1. Patch embedding
self.patch_embed = nn.Conv2d(in_ch, embed_dim,
kernel_size=patch_size, stride=patch_size)
num_patches = (img_size // patch_size) ** 2
# 2. CLS token + positional embeddings
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, embed_dim))
# 3. Single-head Attention parameters
self.W_q = nn.Linear(embed_dim, embed_dim)
self.W_k = nn.Linear(embed_dim, embed_dim)
self.W_v = nn.Linear(embed_dim, embed_dim)
self.W_o = nn.Linear(embed_dim, embed_dim)
# 4. Classification head
self.head = nn.Linear(embed_dim, num_classes)
def forward(self, x):
B = x.shape[0]
# Patchify
x = self.patch_embed(x) # [B, D, H/P, W/P]
x = x.flatten(2).transpose(1, 2) # [B, N, D]
# Add CLS + Positional embeddings
cls = self.cls_token.expand(B, -1, -1)
x = torch.cat([cls, x], dim=1) # [B, N+1, D]
x = x + self.pos_embed
# Manual Self-Attention
Q = self.W_q(x)
K = self.W_k(x)
V = self.W_v(x)
scores = (Q @ K.transpose(-2, -1)) / math.sqrt(self.embed_dim) # [B,N,N]
attn = torch.softmax(scores, dim=-1)
attn_out = attn @ V # [B,N,D]
x = self.W_o(attn_out)
# CLS token -> classification head
cls_out = x[:, 0] # [B, D]
out = self.head(cls_out) # [B, num_classes]
return outmodel = SingleHeadAttentionViT(embed_dim=64)
dummy = torch.randn(1, 3, 224, 224)
out = model(dummy)
print("Output shape:", out.shape)Output shape: torch.Size([1, 10])### Train on CIFAR-10
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
transform = transforms.Compose([
transforms.Resize((224, 224)), # ViT expects 224×224 input
transforms.ToTensor(), # Convert to tensor, scale to [0,1]
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]) # ImageNet normalization
])
# Load datasets
train_dataset = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
test_dataset = datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
# DataLoaders
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True, num_workers=2)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False, num_workers=2)
print(f"Train size: {len(train_dataset)} images")
print(f"Test size: {len(test_dataset)} images")
from torch.utils.data import Subset
import numpy as np
# pick 1/10th (≈5000 train, 1000 test)
train_subset_idx = np.random.choice(len(train_dataset), len(train_dataset)//10, replace=False)
test_subset_idx = np.random.choice(len(test_dataset), len(test_dataset)//10, replace=False)
train_dataset_small = Subset(train_dataset, train_subset_idx)
test_dataset_small = Subset(test_dataset, test_subset_idx)
train_loader = DataLoader(train_dataset_small, batch_size=32, shuffle=True)
test_loader = DataLoader(test_dataset_small, batch_size=32, shuffle=False)
print(f"Reduced Train size: {len(train_dataset_small)}")
print(f"Reduced Test size: {len(test_dataset_small)}")Train size: 50000 images
Test size: 10000 images
Reduced Train size: 5000
Reduced Test size: 1000torch.manual_seed(42)
if torch.cuda.is_available():
device = torch.device("cuda")
elif torch.backends.mps.is_available():
device = torch.device("mps")
else:
device = torch.device("cpu")
print(f"Using device: {device}")Using device: mpsdef train_and_evaluate(model, train_loader, test_loader,
criterion=None, optimizer=None,
device="cpu", num_epochs=20):
"""
Train and evaluate a PyTorch model.
Returns: train_losses, test_losses, test_accuracies
"""
if criterion is None:
criterion = nn.CrossEntropyLoss()
if optimizer is None:
optimizer = optim.Adam(model.parameters(), lr=1e-3)
model.to(device)
train_losses, test_losses, test_accs = [], [], []
for epoch in range(num_epochs):
# ---- Train ----
model.train()
total_train_loss = 0.0
for imgs, labels in train_loader:
imgs, labels = imgs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(imgs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
total_train_loss += loss.item() * imgs.size(0)
epoch_train_loss = total_train_loss / len(train_loader.dataset)
# ---- Evaluate ----
model.eval()
total_test_loss, correct, total = 0.0, 0, 0
with torch.no_grad():
for imgs, labels in test_loader:
imgs, labels = imgs.to(device), labels.to(device)
outputs = model(imgs)
loss = criterion(outputs, labels)
total_test_loss += loss.item() * imgs.size(0)
_, preds = torch.max(outputs, 1)
correct += (preds == labels).sum().item()
total += labels.size(0)
epoch_test_loss = total_test_loss / len(test_loader.dataset)
acc = 100 * correct / total
train_losses.append(epoch_train_loss)
test_losses.append(epoch_test_loss)
test_accs.append(acc)
print(f"Epoch {epoch+1}/{num_epochs} | "
f"Train Loss: {epoch_train_loss:.4f} | "
f"Test Loss: {epoch_test_loss:.4f} | "
f"Test Acc: {acc:.2f}%")
return train_losses, test_losses, test_accsimport torch.optim as optim
model = SingleHeadAttentionViT(embed_dim=64, num_classes=10).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3)
train_losses, test_losses, test_accs = train_and_evaluate(
model, train_loader, test_loader,
criterion, optimizer,
device=device, num_epochs=15
)Epoch 1/15 | Train Loss: 2.1277 | Test Loss: 2.1440 | Test Acc: 19.20%
Epoch 2/15 | Train Loss: 2.0466 | Test Loss: 2.0747 | Test Acc: 21.70%
Epoch 3/15 | Train Loss: 2.0129 | Test Loss: 2.0049 | Test Acc: 26.50%
Epoch 4/15 | Train Loss: 1.9726 | Test Loss: 1.9881 | Test Acc: 25.40%
Epoch 5/15 | Train Loss: 1.9484 | Test Loss: 1.9808 | Test Acc: 24.20%
Epoch 6/15 | Train Loss: 1.9410 | Test Loss: 2.0042 | Test Acc: 24.10%
Epoch 7/15 | Train Loss: 1.9189 | Test Loss: 2.0167 | Test Acc: 24.40%
Epoch 8/15 | Train Loss: 1.9202 | Test Loss: 1.9359 | Test Acc: 26.40%
Epoch 9/15 | Train Loss: 1.9120 | Test Loss: 1.9825 | Test Acc: 25.30%
Epoch 10/15 | Train Loss: 1.8939 | Test Loss: 1.9084 | Test Acc: 28.00%
Epoch 11/15 | Train Loss: 1.8896 | Test Loss: 1.9427 | Test Acc: 25.70%
Epoch 12/15 | Train Loss: 1.8922 | Test Loss: 1.8941 | Test Acc: 29.00%
Epoch 13/15 | Train Loss: 1.8894 | Test Loss: 1.9080 | Test Acc: 28.60%
Epoch 14/15 | Train Loss: 1.8853 | Test Loss: 1.9308 | Test Acc: 25.90%
Epoch 15/15 | Train Loss: 1.8814 | Test Loss: 1.8894 | Test Acc: 26.50%Let us now use PyTorch’s built-in MultiheadAttention module to simplify the attention implementation.
class ViT_AttentionAPI(nn.Module):
def __init__(self, img_size=224, patch_size=16, in_ch=3,
embed_dim=64, num_classes=10, num_heads=1):
super().__init__()
self.embed_dim = embed_dim
self.num_heads = num_heads
# Patch embedding
self.patch_embed = nn.Conv2d(in_ch, embed_dim,
kernel_size=patch_size, stride=patch_size)
num_patches = (img_size // patch_size) ** 2
# CLS + positional embedding
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, embed_dim))
# PyTorch built-in attention layer
self.attn = nn.MultiheadAttention(embed_dim, num_heads, batch_first=True)
# Classification head
self.head = nn.Linear(embed_dim, num_classes)
def forward(self, x):
B = x.shape[0]
# 1. Patchify
x = self.patch_embed(x) # [B, D, H/P, W/P]
x = x.flatten(2).transpose(1, 2) # [B, N, D]
# 2. Add CLS + Positional embeddings
cls = self.cls_token.expand(B, -1, -1)
x = torch.cat([cls, x], dim=1) # [B, N+1, D]
x = x + self.pos_embed
# 3. Multihead Attention (same for 1 head)
attn_out, _ = self.attn(x, x, x) # Q=K=V=x
# 4. CLS token → classifier
cls_out = attn_out[:, 0] # [B, D]
out = self.head(cls_out)
return outmodel = ViT_AttentionAPI(embed_dim=64, num_classes=10).to(device)
dummy = torch.randn(1, 3, 224, 224).to(device)
out = model(dummy)
print("Output shape:", out.shape)Output shape: torch.Size([1, 10])# Now, let us increase the number of heads to 4 and see if it still works
model = ViT_AttentionAPI(embed_dim=64, num_classes=10, num_heads=4).to(device)
dummy = torch.randn(1, 3, 224, 224).to(device)
out = model(dummy)
print("Output shape:", out.shape)Output shape: torch.Size([1, 10])# Now, let us train this model as before!
model = ViT_AttentionAPI(embed_dim=64, num_classes=10, num_heads=4).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3)
train_losses, test_losses, test_accs = train_and_evaluate(
model, train_loader, test_loader,
criterion, optimizer,
device=device, num_epochs=15
)Epoch 1/15 | Train Loss: 2.1238 | Test Loss: 2.1317 | Test Acc: 19.30%
Epoch 2/15 | Train Loss: 2.0400 | Test Loss: 2.0722 | Test Acc: 22.80%
Epoch 3/15 | Train Loss: 1.9755 | Test Loss: 1.9880 | Test Acc: 24.70%
Epoch 4/15 | Train Loss: 1.9293 | Test Loss: 2.0122 | Test Acc: 26.70%
Epoch 5/15 | Train Loss: 1.8682 | Test Loss: 1.8599 | Test Acc: 31.30%
Epoch 6/15 | Train Loss: 1.8314 | Test Loss: 1.8979 | Test Acc: 27.90%
Epoch 7/15 | Train Loss: 1.7982 | Test Loss: 1.8937 | Test Acc: 30.80%
Epoch 8/15 | Train Loss: 1.7989 | Test Loss: 1.8981 | Test Acc: 28.10%
Epoch 9/15 | Train Loss: 1.7851 | Test Loss: 1.8716 | Test Acc: 31.20%
Epoch 10/15 | Train Loss: 1.7877 | Test Loss: 1.8588 | Test Acc: 32.60%
Epoch 11/15 | Train Loss: 1.7702 | Test Loss: 1.8204 | Test Acc: 34.10%
Epoch 12/15 | Train Loss: 1.7569 | Test Loss: 1.8901 | Test Acc: 29.10%
Epoch 13/15 | Train Loss: 1.7505 | Test Loss: 1.7946 | Test Acc: 33.60%
Epoch 14/15 | Train Loss: 1.7452 | Test Loss: 1.8063 | Test Acc: 34.60%
Epoch 15/15 | Train Loss: 1.7361 | Test Loss: 1.8532 | Test Acc: 33.90%class ViT_AttentionAPI_Residual_LayerNorm(nn.Module):
def __init__(self, img_size=224, patch_size=16, in_ch=3,
embed_dim=64, num_classes=10, num_heads=1):
super().__init__()
self.embed_dim = embed_dim
self.num_heads = num_heads
# 1. Patch embedding
self.patch_embed = nn.Conv2d(in_ch, embed_dim,
kernel_size=patch_size, stride=patch_size)
num_patches = (img_size // patch_size) ** 2
# 2. CLS token + positional embeddings
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, embed_dim))
# 3. Attention + LayerNorm
self.norm1 = nn.LayerNorm(embed_dim)
self.attn = nn.MultiheadAttention(embed_dim, num_heads, batch_first=True)
# 4. (Optional) Feedforward block
self.norm2 = nn.LayerNorm(embed_dim)
self.mlp = nn.Sequential(
nn.Linear(embed_dim, 4 * embed_dim),
nn.GELU(),
nn.Linear(4 * embed_dim, embed_dim),
)
# 5. Classification head
self.head = nn.Linear(embed_dim, num_classes)
def forward(self, x):
B = x.shape[0]
# --- Patchify ---
x = self.patch_embed(x) # [B, D, H/P, W/P]
x = x.flatten(2).transpose(1, 2) # [B, N, D]
# --- Add CLS + Positional embeddings ---
cls = self.cls_token.expand(B, -1, -1)
x = torch.cat([cls, x], dim=1) # [B, N+1, D]
x = x + self.pos_embed
# --- Attention + residual ---
x_norm = self.norm1(x)
attn_out, _ = self.attn(x_norm, x_norm, x_norm)
x = x + attn_out # residual 1
# --- Feedforward + residual ---
x_norm = self.norm2(x)
mlp_out = self.mlp(x_norm)
x = x + mlp_out # residual 2
# --- CLS token → classifier ---
cls_out = x[:, 0] # [B, D]
out = self.head(cls_out)
return out# Now, let us train this model as before!
model = ViT_AttentionAPI_Residual_LayerNorm(embed_dim=64, num_classes=10, num_heads=4).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3)
train_losses, test_losses, test_accs = train_and_evaluate(
model, train_loader, test_loader,
criterion, optimizer,
device=device, num_epochs=15
)Epoch 1/15 | Train Loss: 2.0488 | Test Loss: 1.9837 | Test Acc: 25.80%
Epoch 2/15 | Train Loss: 1.8873 | Test Loss: 1.9649 | Test Acc: 25.30%
Epoch 3/15 | Train Loss: 1.8203 | Test Loss: 1.8502 | Test Acc: 28.60%
Epoch 4/15 | Train Loss: 1.7629 | Test Loss: 1.8278 | Test Acc: 31.50%
Epoch 5/15 | Train Loss: 1.7340 | Test Loss: 1.7920 | Test Acc: 33.70%
Epoch 6/15 | Train Loss: 1.7003 | Test Loss: 1.7997 | Test Acc: 34.20%
Epoch 7/15 | Train Loss: 1.6571 | Test Loss: 1.7883 | Test Acc: 33.80%
Epoch 8/15 | Train Loss: 1.6382 | Test Loss: 1.7662 | Test Acc: 35.20%
Epoch 9/15 | Train Loss: 1.6096 | Test Loss: 1.8230 | Test Acc: 32.40%
Epoch 10/15 | Train Loss: 1.5884 | Test Loss: 1.7934 | Test Acc: 36.00%
Epoch 11/15 | Train Loss: 1.5665 | Test Loss: 1.7034 | Test Acc: 36.90%
Epoch 12/15 | Train Loss: 1.5603 | Test Loss: 1.7044 | Test Acc: 37.30%
Epoch 13/15 | Train Loss: 1.5324 | Test Loss: 1.6750 | Test Acc: 38.00%
Epoch 14/15 | Train Loss: 1.5022 | Test Loss: 1.7445 | Test Acc: 35.20%
Epoch 15/15 | Train Loss: 1.4896 | Test Loss: 1.6979 | Test Acc: 39.10%Next
- LayerNorm before attention and MLP (pre-norm)
- Residual connections around attention and MLP
- Self-supervised pretraining (e.g., DINO, MAE) before finetuning on classification
- Masked Autoencoder (MAE): Randomly mask a high percentage of image patches and train the model to reconstruct the missing patches from the visible ones. This forces the model to learn meaningful representations of the image content.