The problem: Every position is treated identically. The model can’t dynamically focus on relevant tokens.
Enter Attention
Attention lets each position look at and weight other positions based on relevance:
"The cat sat on the mat"
↓
When predicting after "mat", attention might:
- Focus heavily on "cat" (the subject)
- Focus on "sat" (the verb)
- Ignore "the" (low information)
# Load dataifnot os.path.exists('shakespeare.txt'): url ="https://raw.githubusercontent.com/karpathy/char-rnn/master/data/tinyshakespeare/input.txt" response = requests.get(url)withopen('shakespeare.txt', 'w') as f: f.write(response.text)withopen('shakespeare.txt', 'r') as f: text = f.read()chars =sorted(set(text))stoi = {ch: i for i, ch inenumerate(chars)}itos = {i: ch for ch, i in stoi.items()}vocab_size =len(stoi)print(f"Vocabulary size: {vocab_size}")
Vocabulary size: 65
Step 1: Understanding Attention Mathematically
Attention computes a weighted combination of values, where weights are based on query-key similarity.
Where: - Q (Query): What am I looking for? - K (Key): What do I contain? - V (Value): What information do I provide?
def simple_attention(query, key, value):""" Basic attention mechanism. Args: query: [batch, seq_len, d_k] key: [batch, seq_len, d_k] value: [batch, seq_len, d_v] Returns: output: [batch, seq_len, d_v] attention_weights: [batch, seq_len, seq_len] """ d_k = query.shape[-1]# Step 1: Compute attention scores (how much each position attends to each other)# [batch, seq_len, d_k] @ [batch, d_k, seq_len] = [batch, seq_len, seq_len] scores = torch.matmul(query, key.transpose(-2, -1))# Step 2: Scale by sqrt(d_k) to prevent softmax saturation scores = scores / math.sqrt(d_k)# Step 3: Softmax to get attention weights (sum to 1) attention_weights = F.softmax(scores, dim=-1)# Step 4: Weighted sum of values output = torch.matmul(attention_weights, value)return output, attention_weights
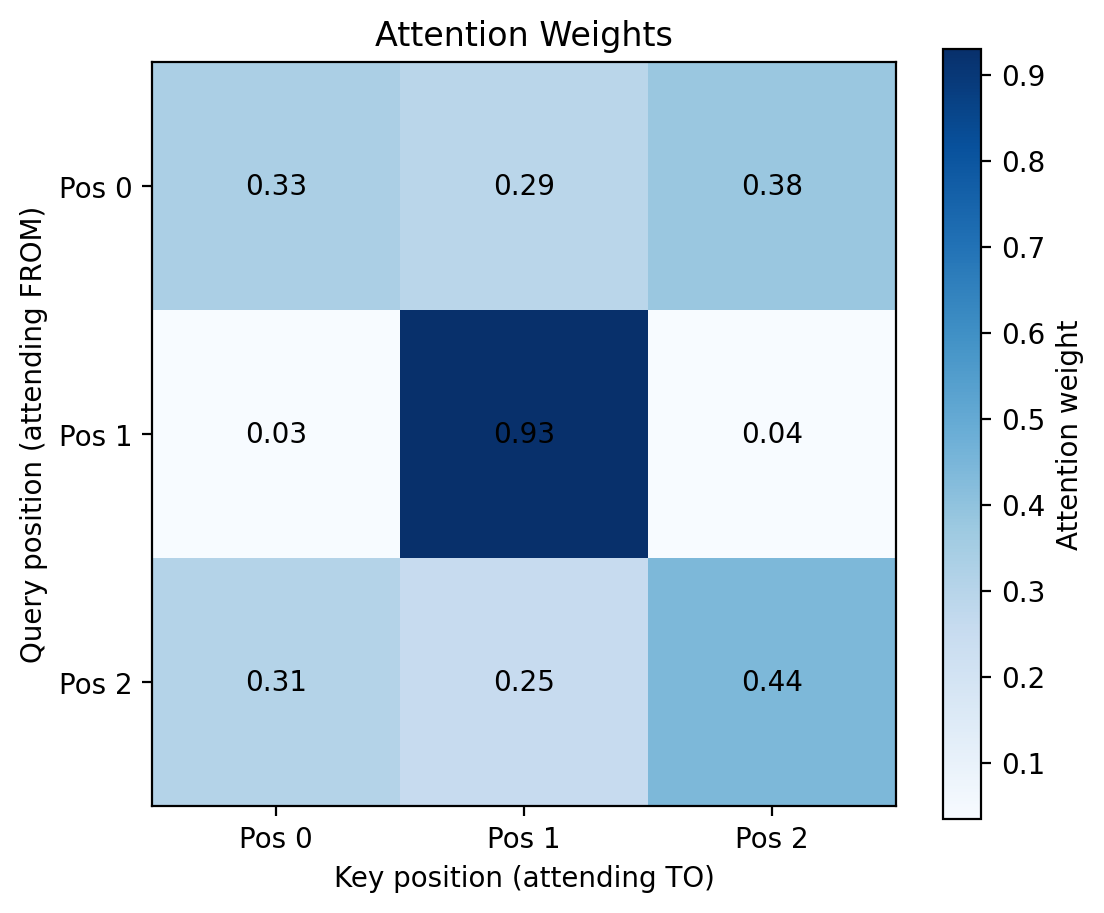
# Example: 3 tokens, embedding dim 4seq_len =3d_model =4# Random embeddings (pretend these represent "The cat sat")embeddings = torch.randn(1, seq_len, d_model)# In self-attention, Q, K, V all come from the same inputQ = embeddingsK = embeddingsV = embeddingsoutput, weights = simple_attention(Q, K, V)print(f"Input shape: {embeddings.shape}")print(f"Output shape: {output.shape}")print(f"\nAttention weights (who attends to whom):")print(weights.squeeze().numpy().round(3))
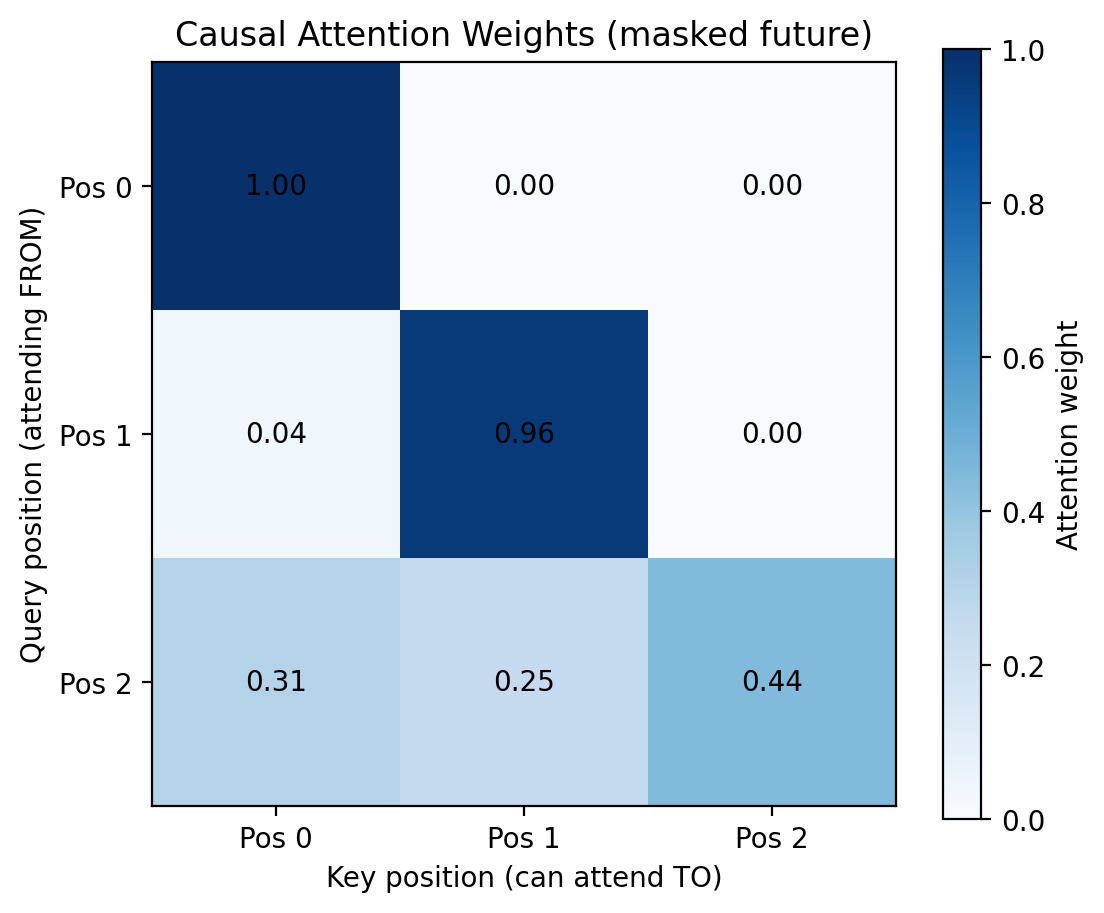
# Visualize causal maskplt.figure(figsize=(6, 5))plt.imshow(weights_causal.squeeze().numpy(), cmap='Blues')plt.colorbar(label='Attention weight')plt.xlabel('Key position (can attend TO)')plt.ylabel('Query position (attending FROM)')plt.title('Causal Attention Weights (masked future)')plt.xticks(range(3), ['Pos 0', 'Pos 1', 'Pos 2'])plt.yticks(range(3), ['Pos 0', 'Pos 1', 'Pos 2'])for i inrange(3):for j inrange(3): plt.text(j, i, f'{weights_causal[0, i, j]:.2f}', ha='center', va='center')plt.show()
Notice: - Position 0 can only attend to itself (weight = 1.0) - Position 1 attends to positions 0 and 1 - Position 2 attends to all positions 0, 1, 2 - No position attends to the future!
Step 3: Self-Attention Layer
In practice, we learn separate projections for Q, K, V:
class SelfAttention(nn.Module):""" Self-attention layer with learned projections. """def__init__(self, d_model, d_k=None):super().__init__()if d_k isNone: d_k = d_model# Learned projectionsself.W_q = nn.Linear(d_model, d_k, bias=False)self.W_k = nn.Linear(d_model, d_k, bias=False)self.W_v = nn.Linear(d_model, d_k, bias=False)self.d_k = d_kdef forward(self, x, mask=True):""" Args: x: [batch, seq_len, d_model] mask: Whether to apply causal mask Returns: output: [batch, seq_len, d_k] """# Project to Q, K, V Q =self.W_q(x) K =self.W_k(x) V =self.W_v(x)# Compute attention scores scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.d_k)# Apply causal mask if neededif mask: seq_len = x.shape[1] causal_mask = torch.triu(torch.ones(seq_len, seq_len, device=x.device), diagonal=1).bool() scores = scores.masked_fill(causal_mask, float('-inf'))# Softmax and weighted sum attention_weights = F.softmax(scores, dim=-1) output = torch.matmul(attention_weights, V)return output
Step 4: Multi-Head Attention
Instead of one attention, we compute multiple “heads” in parallel. Each head can learn different patterns:
# Prepare data - USE SUBSET for faster training!def build_dataset(text, block_size, stoi): data = [stoi[ch] for ch in text] X, Y = [], []for i inrange(len(data) - block_size): X.append(data[i:i + block_size]) Y.append(data[i +1:i + block_size +1])return torch.tensor(X), torch.tensor(Y)# Use only first 100K characters for faster demo (full dataset is 1.1M chars)text_subset = text[:100000]X, Y = build_dataset(text_subset, block_size, stoi)print(f"Dataset: {len(X):,} examples (using subset of Shakespeare for speed)")print(f"Full dataset would be: 1,115,266 examples")
Dataset: 99,936 examples (using subset of Shakespeare for speed)
Full dataset would be: 1,115,266 examples
def train(model, X, Y, epochs=500, batch_size=64, lr=3e-4, checkpoint_path='../models/checkpoint_part4.pt', resume=True):""" Resumable training with checkpoint saving. Args: resume: If True, attempts to resume from checkpoint checkpoint_path: Path to save/load checkpoints """ model.train() optimizer = torch.optim.AdamW(model.parameters(), lr=lr) X, Y = X.to(device), Y.to(device) losses = [] start_epoch =0# Try to resume from checkpointif resume and os.path.exists(checkpoint_path):print(f"Resuming from checkpoint: {checkpoint_path}") checkpoint = torch.load(checkpoint_path, weights_only=False) model.load_state_dict(checkpoint['model_state_dict']) optimizer.load_state_dict(checkpoint['optimizer_state_dict']) start_epoch = checkpoint['epoch'] +1 losses = checkpoint['losses']print(f"Resumed from epoch {start_epoch}, previous loss: {losses[-1]:.4f}")for epoch inrange(start_epoch, epochs): perm = torch.randperm(X.shape[0]) total_loss, n_batches =0, 0for i inrange(0, len(X), batch_size): idx = perm[i:i+batch_size] x_batch, y_batch = X[idx], Y[idx] logits = model(x_batch) loss = F.cross_entropy(logits.view(-1, vocab_size), y_batch.view(-1)) optimizer.zero_grad() loss.backward() optimizer.step() total_loss += loss.item() n_batches +=1 losses.append(total_loss / n_batches)# Print progressif epoch %10==0:print(f"Epoch {epoch}: Loss = {losses[-1]:.4f}")# Save checkpoint every 10 epochsif (epoch +1) %10==0: os.makedirs(os.path.dirname(checkpoint_path), exist_ok=True) torch.save({'epoch': epoch,'model_state_dict': model.state_dict(),'optimizer_state_dict': optimizer.state_dict(),'losses': losses, }, checkpoint_path)print(f"Training complete! Final loss: {losses[-1]:.4f}")return losses# Educational note: Fast training for demo - 50 epochs on small model/dataset# For production: use larger model (d_model=512+), full data, 1000+ epochs# Training is resumable - interrupt and re-run this cell to continue!print("Training transformer (small & fast for educational demo)...")print("You can interrupt and resume training by re-running this cell!")losses = train(model, X, Y, epochs=25, batch_size=128, lr=3e-4)
Training transformer (small & fast for educational demo)...
You can interrupt and resume training by re-running this cell!
Resuming from checkpoint: ../models/checkpoint_part4.pt
Resumed from epoch 20, previous loss: 0.7502
Epoch 20: Loss = 0.7321
Training complete! Final loss: 0.6747
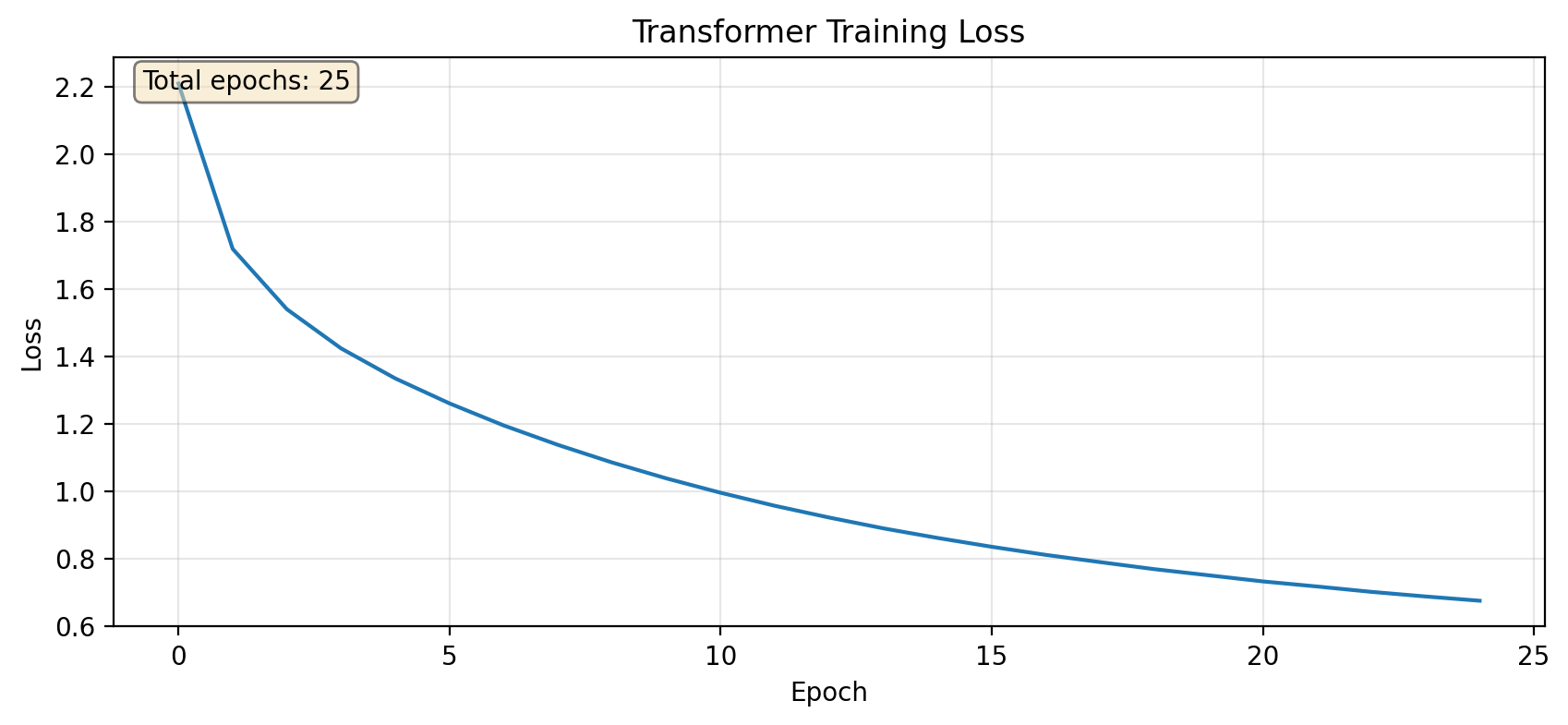
plt.figure(figsize=(10, 4))plt.plot(losses)plt.xlabel('Epoch')plt.ylabel('Loss')plt.title('Transformer Training Loss')plt.grid(True, alpha=0.3)# Show number of epochs trainedplt.text(0.02, 0.98, f'Total epochs: {len(losses)}', transform=plt.gca().transAxes, verticalalignment='top', bbox=dict(boxstyle='round', facecolor='wheat', alpha=0.5))plt.show()print(f"Training summary: {len(losses)} epochs completed, final loss: {losses[-1]:.4f}")
Training summary: 25 epochs completed, final loss: 0.6747
Step 9: Generate Text
@torch.no_grad()def generate(model, seed_text, max_len=500, temperature=0.8): model.eval() tokens = [stoi[ch] for ch in seed_text] generated =list(seed_text)for _ inrange(max_len):# Take last block_size tokens context = tokens[-block_size:] iflen(tokens) >= block_size else tokens x = torch.tensor([context]).to(device) logits = model(x)# Get prediction for last position logits = logits[0, -1, :] / temperature probs = F.softmax(logits, dim=-1) next_idx = torch.multinomial(probs, 1).item() tokens.append(next_idx) generated.append(itos[next_idx])return''.join(generated)print("="*60)print("GENERATED TEXT (Transformer)")print("="*60)print(generate(model, "ROMEO:\n", max_len=500))
============================================================
GENERATED TEXT (Transformer)
============================================================
ROMEO:
That's worthily choice, that I receive the consul, and last gate;
The one common move. I will, and do send, by therefore, they say,
The city is Marcius is proud; which they remain
Of the dispositions of the people, the people is mile;
But thee, the Volsces the matter weell, then, by the faith. do outt of doors bench
In acclamations hypards be their spirit,
Or never be so noble as a single
But by the att of safer judgment and bereaves to be
silent, though covers and solater, the fair words: you h
Save Model for Later Use
Export the transformer model for use in Part 5 (instruction tuning) and beyond.
import os# Create models directoryos.makedirs('../models', exist_ok=True)# Save model checkpoint with architecture infocheckpoint = {'model_state_dict': model.state_dict(),'model_config': {'vocab_size': vocab_size,'d_model': d_model,'n_heads': n_heads,'n_layers': n_layers,'block_size': block_size, },'stoi': stoi,'itos': itos,'final_loss': losses[-1] if losses elseNone,}torch.save(checkpoint, '../models/transformer_shakespeare.pt')print(f"Model saved to ../models/transformer_shakespeare.pt")# Verifyloaded = torch.load('../models/transformer_shakespeare.pt', weights_only=False)print(f"Model config: {loaded['model_config']}")print(f"Model parameters: {num_params:,}")
Model saved to ../models/transformer_shakespeare.pt
Model config: {'vocab_size': 65, 'd_model': 128, 'n_heads': 4, 'n_layers': 3, 'block_size': 64}
Model parameters: 610,241
Clean Up GPU Memory
import gc# Delete model and data tensorsdel modeldel X, Y# Clear CUDA cacheif torch.cuda.is_available(): torch.cuda.empty_cache() torch.cuda.synchronize()gc.collect()print("GPU memory cleared!")if torch.cuda.is_available():print(f"GPU memory allocated: {torch.cuda.memory_allocated() /1024**2:.1f} MB")print(f"GPU memory cached: {torch.cuda.memory_reserved() /1024**2:.1f} MB")
This is the architecture behind GPT-2, GPT-3, GPT-4, Claude, and all modern LLMs!
What’s Next
In Part 5, we’ll take our pretrained model and instruction-tune it to follow instructions. We’ll teach it to answer questions rather than just complete text.
Exercises
Attention visualization: Plot attention patterns for a generated sequence
Head analysis: What does each attention head learn?
Scale up: Increase layers/heads. How does quality change?
Learned positions: Replace sinusoidal with learned positional embeddings
RoPE/ALiBi: Implement modern positional encoding methods