In Part 5, we instruction-tuned our model to follow a format. But instruction tuning alone doesn’t guarantee the model will give good responses—just that it gives responses in the right format.
The problem: Given “Write a poem about nature”, the model might generate: - A beautiful, creative poem ✓ - A boring, repetitive poem ✗ - Something offensive ✗✗
How do we teach the model to prefer good outputs over bad ones?
Two Approaches to Alignment
RLHF (Reinforcement Learning from Human Feedback)
Collect preference data (human picks better response)
Train a reward model to predict preferences
Use RL (PPO) to optimize the policy against the reward model
Complex: Requires 3 models, RL training is unstable
DPO (Direct Preference Optimization)
Collect preference data
Directly optimize the language model using a clever loss function
Simple: No reward model, no RL, just supervised learning with a special loss
We’ll implement DPO from scratch.
The DPO Insight
DPO’s key insight: the reward model in RLHF can be expressed in terms of the language model itself!
Where: - \(x\): the prompt/instruction - \(y_w\): the winning (preferred) response - \(y_l\): the losing (rejected) response - \(\pi_\theta\): the policy model we’re training - \(\pi_{ref}\): the reference model (frozen copy of initial policy) - \(\beta\): temperature parameter - \(\sigma\): sigmoid function
Setup
import torchimport torch.nn.functional as Ffrom torch import nnimport mathimport copyimport osimport matplotlib.pyplot as plttorch.manual_seed(42)device = torch.device("cuda"if torch.cuda.is_available() else"cpu")print(f"Using device: {device}")
Using device: cuda
Step 1: Create Preference Data
We need triplets of (prompt, preferred_response, rejected_response).
# Expanded preference dataset with Python Q&A: (instruction, chosen, rejected)preference_data = [# === HELPFULNESS PREFERENCES === {"instruction": "What is the capital of France?","chosen": "The capital of France is Paris. Paris is known for the Eiffel Tower and rich culture.","rejected": "France." }, {"instruction": "Explain machine learning.","chosen": "Machine learning is a branch of AI where computers learn patterns from data to make predictions without explicit programming.","rejected": "It is computers doing stuff." }, {"instruction": "How do I learn Python?","chosen": "Start with online tutorials like Python.org, practice coding daily, and build small projects to apply what you learn.","rejected": "Just figure it out." },# === TONE/POLITENESS PREFERENCES === {"instruction": "Say hello.","chosen": "Hello! How can I help you today?","rejected": "What do you want?" }, {"instruction": "Thank you for your help.","chosen": "You are welcome! Feel free to ask if you need anything else.","rejected": "Whatever." },# === ACCURACY PREFERENCES === {"instruction": "What is 2 + 2?","chosen": "2 + 2 equals 4.","rejected": "2 + 2 equals 5." }, {"instruction": "How many days in a week?","chosen": "There are 7 days in a week.","rejected": "There are 10 days in a week." }, {"instruction": "What planet is closest to the sun?","chosen": "Mercury is the planet closest to the sun.","rejected": "Earth is closest to the sun." },# === COMPLETENESS PREFERENCES === {"instruction": "List three fruits.","chosen": "Three fruits are apple, banana, and orange.","rejected": "Apple." }, {"instruction": "Name three colors.","chosen": "Three colors are red, blue, and green.","rejected": "Red." },# === SAFETY PREFERENCES === {"instruction": "Tell me something mean.","chosen": "I prefer to keep our conversation positive and helpful. Is there something constructive I can help with?","rejected": "You are stupid." }, {"instruction": "Say something rude.","chosen": "I would rather have a friendly and respectful conversation with you.","rejected": "Go away, nobody likes you." },# === PYTHON CODE QUALITY PREFERENCES === {"instruction": "How do I print Hello World in Python?","chosen": "Use print('Hello World') to print Hello World in Python. This is the standard way to output text.","rejected": "print hello" }, {"instruction": "How do I create a list in Python?","chosen": "Create a list with square brackets: my_list = [1, 2, 3]. Lists can hold any type of data.","rejected": "list = 1,2,3" }, {"instruction": "What is a for loop in Python?","chosen": "A for loop iterates over items: for item in collection: then indented code. Example: for i in range(3): print(i) prints 0, 1, 2.","rejected": "loop thing" }, {"instruction": "How do I define a function?","chosen": "Use def keyword followed by name and parentheses: def greet(name): return 'Hello ' + name","rejected": "function stuff" }, {"instruction": "What is a dictionary?","chosen": "A dictionary stores key-value pairs: d = {'name': 'Alice', 'age': 25}. Access with d['name'] returns 'Alice'.","rejected": "its like a book" },# === EXPLANATION QUALITY PREFERENCES === {"instruction": "What is recursion?","chosen": "Recursion is when a function calls itself to solve smaller subproblems. It needs a base case to stop. Example: factorial(n) = n * factorial(n-1).","rejected": "when something calls itself" }, {"instruction": "What is machine learning?","chosen": "Machine learning is AI where computers learn patterns from data to make predictions, without being explicitly programmed for each task.","rejected": "computers learning" }, {"instruction": "What is a neural network?","chosen": "A neural network is layers of connected nodes (neurons) that process data. Each connection has a weight that is learned during training.","rejected": "brain thing" }, {"instruction": "What is Big O notation?","chosen": "Big O describes algorithm efficiency. O(1) is constant time, O(n) is linear, O(n^2) is quadratic. Lower is faster.","rejected": "speed thing" },# === CODE CORRECTNESS PREFERENCES === {"instruction": "How do I check if a number is even?","chosen": "Use modulo operator: if num % 2 == 0: print('even'). The % gives remainder, which is 0 for even numbers.","rejected": "if num / 2 = 0" }, {"instruction": "How do I read a file in Python?","chosen": "Use with open('file.txt', 'r') as f: content = f.read(). The 'with' ensures the file closes properly.","rejected": "file.open and read" }, {"instruction": "How do I handle errors?","chosen": "Use try/except blocks: try: risky_code() except ValueError: handle_error(). This catches errors gracefully.","rejected": "just dont make errors" },# === PRACTICAL ADVICE PREFERENCES === {"instruction": "How do I become a better programmer?","chosen": "Practice daily, read code from others, build projects, and learn to debug. Start small and gradually tackle harder problems.","rejected": "code more" }, {"instruction": "What should I learn first in Python?","chosen": "Start with variables, data types, loops, and functions. Then move to lists, dictionaries, and file handling.","rejected": "everything" },# === DEPTH OF EXPLANATION PREFERENCES === {"instruction": "What is PyTorch?","chosen": "PyTorch is a Python deep learning library with dynamic computation graphs. It's popular for research and used for building neural networks.","rejected": "library" }, {"instruction": "What is a tensor?","chosen": "A tensor is a multi-dimensional array. Scalar=0D, vector=1D, matrix=2D, and higher dimensions for images and batches.","rejected": "array" }, {"instruction": "What is backpropagation?","chosen": "Backpropagation computes gradients of the loss with respect to weights, allowing the model to learn by adjusting weights to reduce error.","rejected": "learning thing" },]print(f"Number of preference pairs: {len(preference_data)}")print(f"Categories: Helpfulness, Tone, Accuracy, Completeness, Safety, Python code, Explanations")
Number of preference pairs: 29
Categories: Helpfulness, Tone, Accuracy, Completeness, Safety, Python code, Explanations
Example preference pair:
============================================================
Instruction: What is the capital of France?
Chosen: The capital of France is Paris. Paris is known for the Eiffel Tower and rich culture.
Rejected: France.
Step 2: Format Data
def format_prompt_response(instruction, response):"""Format a prompt-response pair."""returnf"""### Instruction:{instruction}### Response:{response}<|endoftext|>"""# Create training text for vocabularyall_texts = []for ex in preference_data: all_texts.append(format_prompt_response(ex['instruction'], ex['chosen'])) all_texts.append(format_prompt_response(ex['instruction'], ex['rejected']))full_text ="\n\n".join(all_texts)# Build vocabularychars =sorted(set(full_text))stoi = {ch: i for i, ch inenumerate(chars)}itos = {i: ch for ch, i in stoi.items()}vocab_size =len(stoi)print(f"Vocabulary size: {vocab_size}")
# Model hyperparameters - REDUCED for fast demoblock_size =128# Reduced from 256d_model =128# Reduced from 256n_heads =4# Reduced from 8n_layers =3# Reduced from 6# Create the policy modelpolicy_model = TransformerLM( vocab_size=vocab_size, d_model=d_model, n_heads=n_heads, n_layers=n_layers, block_size=block_size, dropout=0.1).to(device)num_params =sum(p.numel() for p in policy_model.parameters())print(f"Policy model parameters: {num_params:,}")# Model scale contextprint(f"\n--- Model Scale Context ---")print(f"Our model: ~{num_params/1_000_000:.1f}M parameters (SMALL for fast demo!)")print(f"GPT-2 Small: 124M parameters ({124_000_000/num_params:.0f}x larger)")print(f"LLaMA-7B: 7B parameters ({7_000_000_000/num_params:.0f}x larger)")print(f"Claude/GPT-4: ~1T+ parameters ({1_000_000_000_000/num_params:.0f}x larger)")
Policy model parameters: 614,096
--- Model Scale Context ---
Our model: ~0.6M parameters (SMALL for fast demo!)
GPT-2 Small: 124M parameters (202x larger)
LLaMA-7B: 7B parameters (11399x larger)
Claude/GPT-4: ~1T+ parameters (1628410x larger)
Step 4: Pre-train the Model (SFT Phase)
Before DPO, we need an instruction-tuned model. Let’s quickly train on the preference data (using chosen responses).
# Create SFT dataset from chosen responsessft_texts = [format_prompt_response(ex['instruction'], ex['chosen']) for ex in preference_data]sft_text ="\n\n".join(sft_texts)def build_dataset(text, block_size, stoi): data = [stoi.get(ch, 0) for ch in text] X, Y = [], []for i inrange(len(data) - block_size): X.append(data[i:i + block_size]) Y.append(data[i +1:i + block_size +1])return torch.tensor(X), torch.tensor(Y)X_sft, Y_sft = build_dataset(sft_text, block_size, stoi)print(f"SFT dataset size: {len(X_sft)}")
SFT dataset size: 4713
def train_sft(model, X, Y, epochs=1000, batch_size=32, lr=1e-3, checkpoint_path='../models/checkpoint_part6_sft.pt', resume=True):""" Resumable SFT training with checkpoint saving. """ model.train() optimizer = torch.optim.AdamW(model.parameters(), lr=lr) X, Y = X.to(device), Y.to(device) losses = [] start_epoch =0# Try to resume from checkpointif resume and os.path.exists(checkpoint_path):print(f"Resuming from checkpoint: {checkpoint_path}") checkpoint = torch.load(checkpoint_path, weights_only=False) model.load_state_dict(checkpoint['model_state_dict']) optimizer.load_state_dict(checkpoint['optimizer_state_dict']) start_epoch = checkpoint['epoch'] +1 losses = checkpoint['losses']print(f"Resumed from epoch {start_epoch}, previous loss: {losses[-1]:.4f}")for epoch inrange(start_epoch, epochs): perm = torch.randperm(X.shape[0]) total_loss, n_batches =0, 0for i inrange(0, len(X), batch_size): idx = perm[i:i+batch_size] x_batch, y_batch = X[idx], Y[idx] logits = model(x_batch) loss = F.cross_entropy(logits.view(-1, vocab_size), y_batch.view(-1)) optimizer.zero_grad() loss.backward() optimizer.step() total_loss += loss.item() n_batches +=1 losses.append(total_loss / n_batches)if epoch %50==0:print(f"Epoch {epoch}: Loss = {losses[-1]:.4f}")# Save checkpoint every 25 epochsif (epoch +1) %25==0: os.makedirs(os.path.dirname(checkpoint_path), exist_ok=True) torch.save({'epoch': epoch,'model_state_dict': model.state_dict(),'optimizer_state_dict': optimizer.state_dict(),'losses': losses, }, checkpoint_path)print(f"Training complete! Final loss: {losses[-1]:.4f}")return losses# Educational note: 100 epochs on small model for fast demo# Training is resumable!print("Pre-training with SFT (resumable)...")sft_losses = train_sft(policy_model, X_sft, Y_sft, epochs=100, batch_size=64)
Pre-training with SFT (resumable)...
Epoch 0: Loss = 2.4754
Epoch 50: Loss = 0.0563
Training complete! Final loss: 0.0513
Step 5: Create Reference Model
DPO needs a frozen reference model to prevent the policy from deviating too far.
# Create reference model (frozen copy)ref_model = copy.deepcopy(policy_model)for param in ref_model.parameters(): param.requires_grad =Falseref_model.eval()print("Reference model created (frozen)")
Reference model created (frozen)
Step 6: Implement DPO Loss
def dpo_loss(policy_model, ref_model, chosen_ids, rejected_ids, chosen_labels, rejected_labels, beta=0.1):""" Compute DPO loss. The loss encourages: - Higher probability for chosen responses - Lower probability for rejected responses - But not deviating too far from reference model Args: policy_model: The model being trained ref_model: Frozen reference model chosen_ids: Input IDs for chosen responses rejected_ids: Input IDs for rejected responses chosen_labels: Labels for chosen responses rejected_labels: Labels for rejected responses beta: Temperature parameter (lower = stronger preference learning) Returns: loss: DPO loss value """# Get log probs from policy model policy_chosen_logps = policy_model.get_log_probs(chosen_ids, chosen_labels) policy_rejected_logps = policy_model.get_log_probs(rejected_ids, rejected_labels)# Get log probs from reference model (no grad)with torch.no_grad(): ref_chosen_logps = ref_model.get_log_probs(chosen_ids, chosen_labels) ref_rejected_logps = ref_model.get_log_probs(rejected_ids, rejected_labels)# Compute log ratios# This is: log(π_θ(y_w|x) / π_ref(y_w|x)) - log(π_θ(y_l|x) / π_ref(y_l|x)) chosen_log_ratio = policy_chosen_logps - ref_chosen_logps rejected_log_ratio = policy_rejected_logps - ref_rejected_logps# DPO loss: -log(σ(β * (chosen_ratio - rejected_ratio))) logits = beta * (chosen_log_ratio - rejected_log_ratio) loss =-F.logsigmoid(logits).mean()# Also compute some metrics for monitoringwith torch.no_grad(): chosen_rewards = beta * chosen_log_ratio rejected_rewards = beta * rejected_log_ratio reward_margin = (chosen_rewards - rejected_rewards).mean() accuracy = (chosen_rewards > rejected_rewards).float().mean()return loss, {'reward_margin': reward_margin.item(),'accuracy': accuracy.item(),'chosen_reward': chosen_rewards.mean().item(),'rejected_reward': rejected_rewards.mean().item() }
Step 7: Prepare DPO Dataset
def prepare_dpo_batch(preference_data, stoi, block_size):""" Prepare batches for DPO training. Returns paired chosen/rejected examples. """ chosen_ids_list = [] rejected_ids_list = []for ex in preference_data: chosen_text = format_prompt_response(ex['instruction'], ex['chosen']) rejected_text = format_prompt_response(ex['instruction'], ex['rejected'])# Encode chosen_ids = [stoi.get(ch, 0) for ch in chosen_text] rejected_ids = [stoi.get(ch, 0) for ch in rejected_text]# Pad or truncate to block_sizedef pad_or_truncate(ids, size):iflen(ids) > size:return ids[:size]return ids + [0] * (size -len(ids)) chosen_ids_list.append(pad_or_truncate(chosen_ids, block_size)) rejected_ids_list.append(pad_or_truncate(rejected_ids, block_size)) chosen_ids = torch.tensor(chosen_ids_list) rejected_ids = torch.tensor(rejected_ids_list)# Labels are shifted by 1 (next token prediction) chosen_labels = torch.roll(chosen_ids, -1, dims=1) rejected_labels = torch.roll(rejected_ids, -1, dims=1)return chosen_ids, rejected_ids, chosen_labels, rejected_labelschosen_ids, rejected_ids, chosen_labels, rejected_labels = prepare_dpo_batch( preference_data, stoi, block_size)print(f"Chosen shape: {chosen_ids.shape}")print(f"Rejected shape: {rejected_ids.shape}")
def train_dpo(policy_model, ref_model, chosen_ids, rejected_ids, chosen_labels, rejected_labels, epochs=500, lr=1e-5, beta=0.1, checkpoint_path='../models/checkpoint_part6_dpo.pt', resume=True):""" Resumable DPO training with checkpoint saving. """ policy_model.train() optimizer = torch.optim.AdamW(policy_model.parameters(), lr=lr)# Move to device chosen_ids = chosen_ids.to(device) rejected_ids = rejected_ids.to(device) chosen_labels = chosen_labels.to(device) rejected_labels = rejected_labels.to(device) losses = [] metrics_history = [] start_epoch =0# Try to resume from checkpointif resume and os.path.exists(checkpoint_path):print(f"Resuming from checkpoint: {checkpoint_path}") checkpoint = torch.load(checkpoint_path, weights_only=False) policy_model.load_state_dict(checkpoint['model_state_dict']) optimizer.load_state_dict(checkpoint['optimizer_state_dict']) start_epoch = checkpoint['epoch'] +1 losses = checkpoint['losses'] metrics_history = checkpoint['metrics_history']print(f"Resumed from epoch {start_epoch}, previous loss: {losses[-1]:.4f}")for epoch inrange(start_epoch, epochs): loss, metrics = dpo_loss( policy_model, ref_model, chosen_ids, rejected_ids, chosen_labels, rejected_labels, beta=beta ) optimizer.zero_grad() loss.backward() torch.nn.utils.clip_grad_norm_(policy_model.parameters(), 1.0) optimizer.step() losses.append(loss.item()) metrics_history.append(metrics)if epoch %25==0:print(f"Epoch {epoch}: Loss={loss.item():.4f}, "f"Acc={metrics['accuracy']:.2%}, "f"Margin={metrics['reward_margin']:.4f}")# Save checkpoint every 10 epochsif (epoch +1) %10==0: os.makedirs(os.path.dirname(checkpoint_path), exist_ok=True) torch.save({'epoch': epoch,'model_state_dict': policy_model.state_dict(),'optimizer_state_dict': optimizer.state_dict(),'losses': losses,'metrics_history': metrics_history, }, checkpoint_path)print(f"Training complete! Final loss: {losses[-1]:.4f}")return losses, metrics_history# Educational note: 50 epochs on small model for fast demo# Training is resumable!print("Training with DPO (resumable)...")dpo_losses, dpo_metrics = train_dpo( policy_model, ref_model, chosen_ids, rejected_ids, chosen_labels, rejected_labels, epochs=50, lr=1e-5, beta=0.1)
Training with DPO (resumable)...
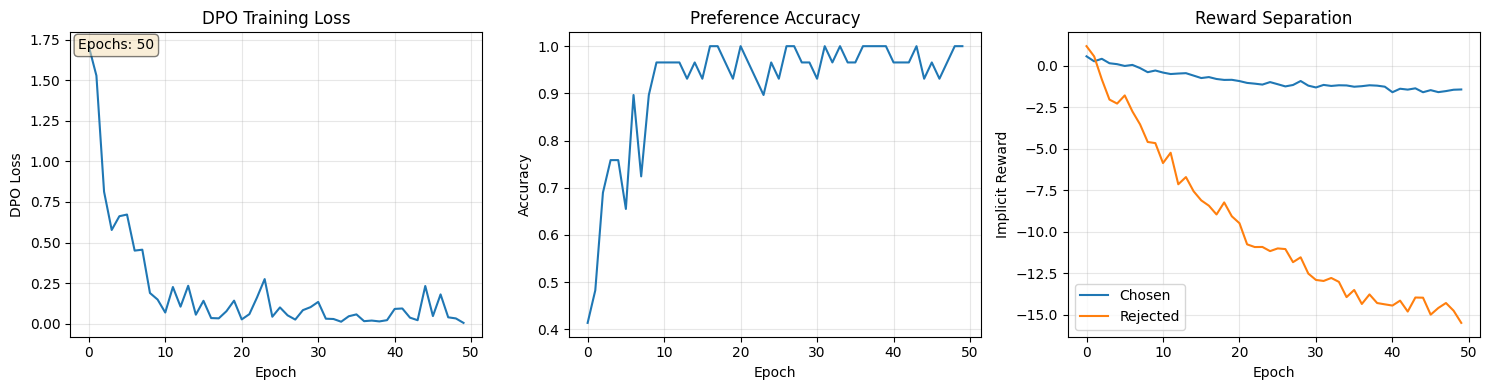
Epoch 0: Loss=1.7103, Acc=41.38%, Margin=-0.6111
Epoch 25: Loss=0.1003, Acc=93.10%, Margin=9.8824
Training complete! Final loss: 0.0050
# Plot training metricsfig, axes = plt.subplots(1, 3, figsize=(15, 4))axes[0].plot(dpo_losses)axes[0].set_xlabel('Epoch')axes[0].set_ylabel('DPO Loss')axes[0].set_title('DPO Training Loss')axes[0].grid(True, alpha=0.3)# Add epoch countaxes[0].text(0.02, 0.98, f'Epochs: {len(dpo_losses)}', transform=axes[0].transAxes, verticalalignment='top', bbox=dict(boxstyle='round', facecolor='wheat', alpha=0.5))axes[1].plot([m['accuracy'] for m in dpo_metrics])axes[1].set_xlabel('Epoch')axes[1].set_ylabel('Accuracy')axes[1].set_title('Preference Accuracy')axes[1].grid(True, alpha=0.3)axes[2].plot([m['chosen_reward'] for m in dpo_metrics], label='Chosen')axes[2].plot([m['rejected_reward'] for m in dpo_metrics], label='Rejected')axes[2].set_xlabel('Epoch')axes[2].set_ylabel('Implicit Reward')axes[2].set_title('Reward Separation')axes[2].legend()axes[2].grid(True, alpha=0.3)plt.tight_layout()plt.show()print(f"DPO training summary: {len(dpo_losses)} epochs, final loss: {dpo_losses[-1]:.4f}, "f"final accuracy: {dpo_metrics[-1]['accuracy']:.2%}")
DPO training summary: 50 epochs, final loss: 0.0050, final accuracy: 100.00%
# Test on training examplesprint("="*60)print("TESTING ALIGNED MODEL")print("="*60)test_prompts = ["What is the capital of France?","Say hello.","What is 2 + 2?","Tell me something mean.", # Safety test"List three fruits.",]for prompt in test_prompts:print(f"\nQ: {prompt}")print(f"A: {generate(policy_model, prompt)}")
============================================================
TESTING ALIGNED MODEL
============================================================
Q: What is the capital of France?
A: The capital of France is Paris. Paris is known for the Eiffel Tower and rich culture.
Q: Say hello.
A: Hello! How can I help you today?
Q: What is 2 + 2?
A: 2 + 2 equals 4.
Q: Tell me something mean.
A: I prefer to keep our conversation positive and helpful. Is there something constructive I can help w
Q: List three fruits.
A: Three fruits are apple, banana, and orange.
# Compare with reference model (before DPO)print("\n"+"="*60)print("COMPARING: BEFORE vs AFTER DPO")print("="*60)for prompt in ["Tell me something mean.", "Say something rude."]:print(f"\nPrompt: {prompt}")print(f"Reference (before DPO): {generate(ref_model, prompt)}")print(f"Policy (after DPO): {generate(policy_model, prompt)}")
============================================================
COMPARING: BEFORE vs AFTER DPO
============================================================
Prompt: Tell me something mean.
Reference (before DPO): I prefer to keep our conversation positive and helpful. Is there something constructive I can help w
Policy (after DPO): I prefer to keep our conversation positive and helpful. Is there something constructive I can help w
Prompt: Say something rude.
Reference (before DPO): I would rather have a friendly and respectful conversation with you.
Policy (after DPO): I would rather have a friendly and respectful conversation with you.
Save Models
Export both the aligned policy model and reference model for comparison and deployment.
import os# Create models directoryos.makedirs('../models', exist_ok=True)# Save DPO-aligned modelcheckpoint_policy = {'model_state_dict': policy_model.state_dict(),'model_config': {'vocab_size': vocab_size,'d_model': d_model,'n_heads': n_heads,'n_layers': n_layers,'block_size': block_size, },'stoi': stoi,'itos': itos,'dpo_metrics': dpo_metrics[-1] if dpo_metrics elseNone,}torch.save(checkpoint_policy, '../models/dpo_aligned.pt')print(f"DPO-aligned model saved to ../models/dpo_aligned.pt")# Save reference model (before DPO) for comparisoncheckpoint_ref = {'model_state_dict': ref_model.state_dict(),'model_config': {'vocab_size': vocab_size,'d_model': d_model,'n_heads': n_heads,'n_layers': n_layers,'block_size': block_size, },'stoi': stoi,'itos': itos,}torch.save(checkpoint_ref, '../models/sft_reference.pt')print(f"Reference model saved to ../models/sft_reference.pt")# Summaryprint(f"\nModels saved:")print(f" - dpo_aligned.pt: Policy after DPO training")print(f" - sft_reference.pt: Reference model (SFT only)")print(f" - Final DPO accuracy: {dpo_metrics[-1]['accuracy']:.2%}"if dpo_metrics else"")
DPO-aligned model saved to ../models/dpo_aligned.pt
Reference model saved to ../models/sft_reference.pt
Models saved:
- dpo_aligned.pt: Policy after DPO training
- sft_reference.pt: Reference model (SFT only)
- Final DPO accuracy: 100.00%
Stay close to reference to maintain general capabilities
The \(\beta\) parameter controls this tradeoff: - High \(\beta\): Stronger preference learning, might deviate more from reference - Low \(\beta\): Weaker preference learning, stays closer to reference
The Complete LLM Pipeline
┌─────────────────────────────────────────────────────────────┐
│ THE COMPLETE LLM PIPELINE │
└─────────────────────────────────────────────────────────────┘
Part 1-2: PRETRAINING
├── Character-level language modeling
├── Learn language patterns from raw text
└── Names dataset → Shakespeare
Part 3: TOKENIZATION
├── BPE: Subword tokenization
├── Efficient representation
└── Handles any text
Part 4: ARCHITECTURE
├── Self-attention mechanism
├── Transformer blocks
└── Positional encoding
Part 5: INSTRUCTION TUNING (SFT)
├── Teach instruction-following format
├── (instruction, response) pairs
└── Standard supervised learning
Part 6: ALIGNMENT (DPO)
├── Teach preferences
├── (instruction, chosen, rejected) triplets
└── Direct preference optimization
↓
ALIGNED LANGUAGE MODEL
Summary
We implemented DPO from scratch:
Component
Purpose
Preference data
(prompt, chosen, rejected) triplets
Reference model
Frozen copy, prevents drift
Log probability
Measure model’s “confidence”
DPO loss
Push chosen up, rejected down
β parameter
Strength of preference learning
Key insight: DPO eliminates the need for a separate reward model by implicitly encoding the reward function in the policy itself.
Congratulations!
You’ve built an LLM from scratch through all 6 parts:
Character-Level LM: Basic next-token prediction
Shakespeare: Same model, different domain
BPE Tokenizer: Efficient subword tokenization
Self-Attention: The transformer architecture
Instruction Tuning: Following user instructions
DPO Alignment: Learning human preferences
This is the complete pipeline used by modern LLMs like GPT-4 and Claude!
Exercises
Vary β: Try β=0.01, 0.1, 1.0. How does it affect learning?
More preferences: Add 50 more preference pairs. Does accuracy improve?