A comprehensive introduction to Pandas library for data manipulation and analysis, covering data structures, indexing, merging, grouping, and advanced operations
Author
Nipun Batra, Shreyans Jain, Guntas Singh Saran
Published
January 13, 2025
Keywords
pandas, data manipulation, dataframes, series, data analysis, python, groupby, pivot tables
## 1. Introduction
Pandas is a powerful Python library for data manipulation, offering labeled data structures that make tasks like cleaning, transformation, merging, and analysis more convenient.
import numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport seaborn as snsprint("Using Pandas version:", pd.__version__)print("Using NumPy version:", np.__version__)print("Using Seaborn version:", sns.__version__)%matplotlib inline%config InlineBackend.figure_format ='retina'
Using Pandas version: 2.2.3
Using NumPy version: 2.1.2
Using Seaborn version: 0.13.2
2. Numpy vs. Pandas for Student Scores
2.1 Creating and Saving Student Data to Excel/CSV
We’ll first generate some random student data: - Name (string) - Maths (integer) - Science (integer)
Then we’ll save to both .xlsx and .csv for demonstration.
NumPy’s loadtxt can be used to read numeric data easily, but handling mixed types (e.g. strings + numbers) can be trickier. We’ll demonstrate a simple approach:
Read the entire CSV (skipping the header) using np.loadtxt.
We’ll parse the Name column as a string and the three score columns as integers.
Compute the mean of Maths and Science.
Find which student got the maximum in Science.
Find which student got the maximum of |Maths - Science|.
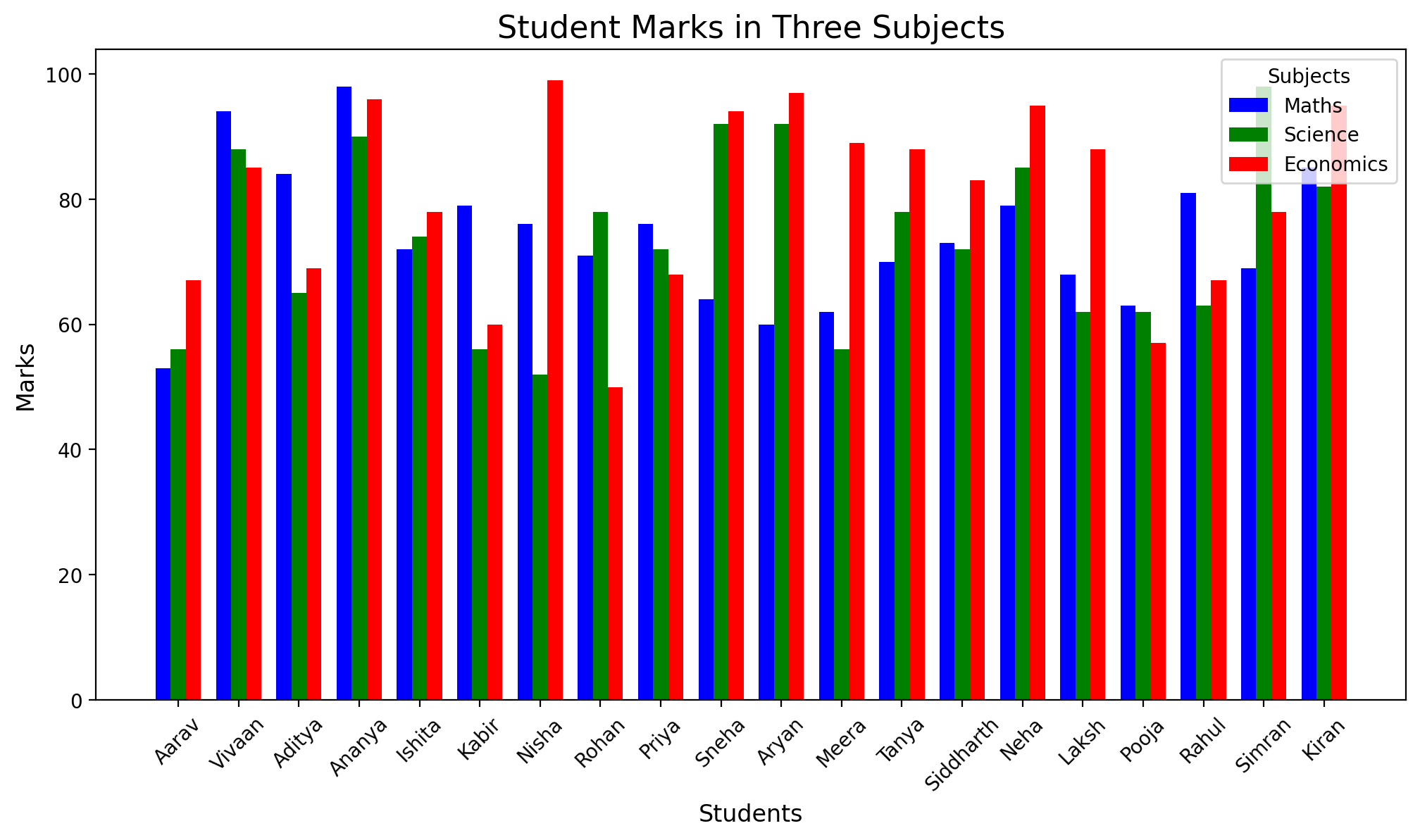
Mean Maths score: 73.850
Mean Science score: 73.650
Mean Economics score: 80.150
Mean Maths score (integer): 73.85
# Finding student with maximum sciencemax_sci_idx = np.argmax(science_np)print(max_sci_idx)
18
# since we need the name of the student, we use the index (from argmax) to find the namemax_sci_student = names[max_sci_idx]max_sci_val = science_np[max_sci_idx]print(f"\nStudent with maximum science score: {max_sci_student} ({max_sci_val})")
Student with maximum science score: Simran (98)
# Likewise for finding student with maximum |Maths - Science| scorediff = np.abs(maths_np - science_np)max_diff_idx = np.argmax(diff)max_diff_student = names[max_diff_idx]print(f"\nStudent with max |Maths - Science|: {max_diff_student} (|{maths_np[max_diff_idx]} - {science_np[max_diff_idx]}| = {diff[max_diff_idx]})")
Student with max |Maths - Science|: Aryan (|60 - 92| = 32)
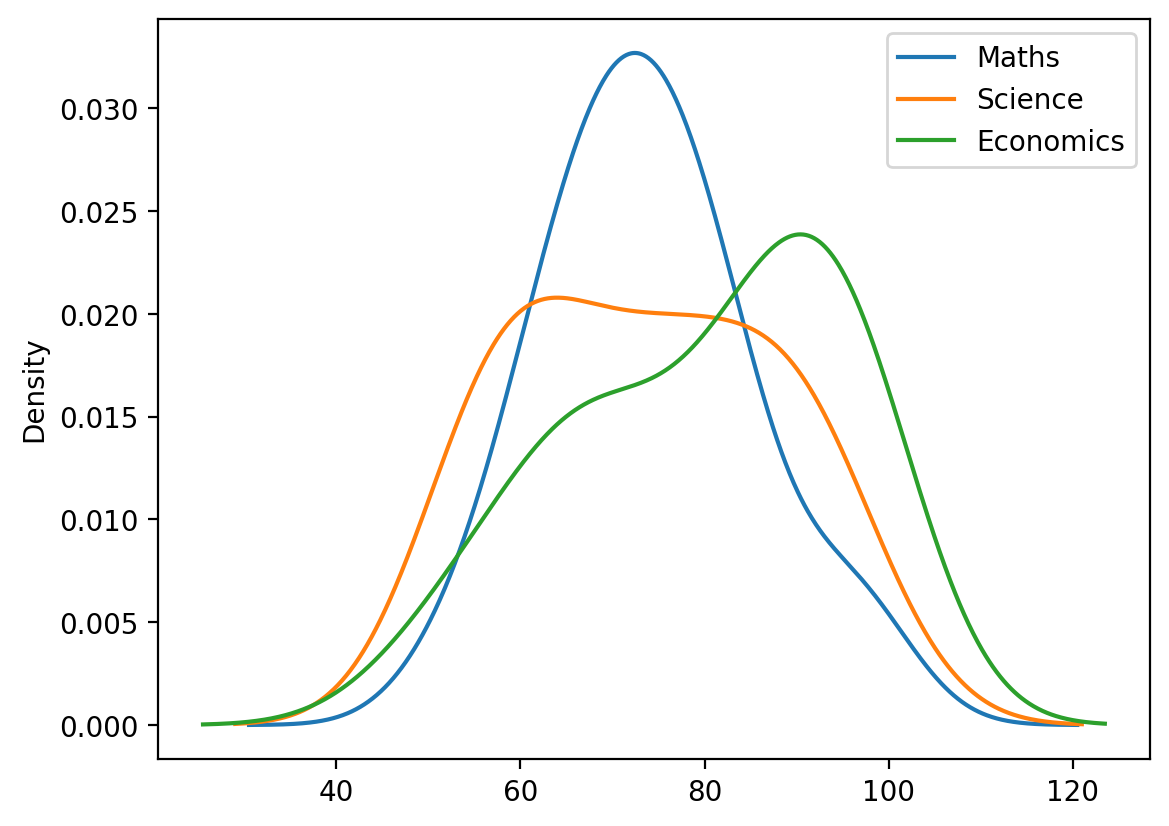
2.3 Plotting Student Scores with NumPy/Seaborn
# Define bar width and positionsbar_width =0.25x = np.arange(len(names))# Create the figure and axisfig, ax = plt.subplots(figsize=(12, 6))# Plot the barsax.bar(x - bar_width, maths_np, width=bar_width, label="Maths", color='blue')ax.bar(x, science_np, width=bar_width, label="Science", color='green')ax.bar(x + bar_width, eco_np, width=bar_width, label="Economics", color='red')# Customize the plotax.set_title("Student Marks in Three Subjects", fontsize=16)ax.set_xlabel("Students", fontsize=12)ax.set_ylabel("Marks", fontsize=12)ax.set_xticks(x)ax.set_xticklabels(names, rotation=45)ax.legend(title="Subjects")
### 2.4 Reading CSV in Pandas & Repeating Analysis With Pandas, we can directly do:
df = pd.read_csv("student_scores.csv")
and the DataFrame will automatically separate columns into name, maths, and science. Then we can easily compute means, maxima, etc.
Signature: df_students_pandas.head(n:'int'=5)->'Self'Docstring:
Return the first `n` rows.
This function returns the first `n` rows for the object based
on position. It is useful for quickly testing if your object
has the right type of data in it.
For negative values of `n`, this function returns all rows except
the last `|n|` rows, equivalent to ``df[:n]``.
If n is larger than the number of rows, this function returns all rows.
Parameters
----------
n : int, default 5
Number of rows to select.
Returns
-------
same type as caller
The first `n` rows of the caller object.
See Also
--------
DataFrame.tail: Returns the last `n` rows.
Examples
--------
>>> df = pd.DataFrame({'animal': ['alligator', 'bee', 'falcon', 'lion',
... 'monkey', 'parrot', 'shark', 'whale', 'zebra']})
>>> df
animal
0 alligator
1 bee
2 falcon
3 lion
4 monkey
5 parrot
6 shark
7 whale
8 zebra
Viewing the first 5 lines
>>> df.head()
animal
0 alligator
1 bee
2 falcon
3 lion
4 monkey
Viewing the first `n` lines (three in this case)
>>> df.head(3)
animal
0 alligator
1 bee
2 falcon
For negative values of `n`
>>> df.head(-3)
animal
0 alligator
1 bee
2 falcon
3 lion
4 monkey
5 parrot
File: ~/mambaforge/lib/python3.12/site-packages/pandas/core/generic.py
Type: method
df_students_pandas.head(n=10)
Name
Maths
Science
Economics
0
Aarav
53
56
67
1
Vivaan
94
88
85
2
Aditya
84
65
69
3
Ananya
98
90
96
4
Ishita
72
74
78
5
Kabir
79
56
60
6
Nisha
76
52
99
7
Rohan
71
78
50
8
Priya
76
72
68
9
Sneha
64
92
94
df_students_pandas.tail()
Name
Maths
Science
Economics
15
Laksh
68
62
88
16
Pooja
63
62
57
17
Rahul
81
63
67
18
Simran
69
98
78
19
Kiran
85
82
95
# Displaying the indices and columnsprint(f"Indices: {df_students_pandas.index}")print(f"Columns: {df_students_pandas.columns}")
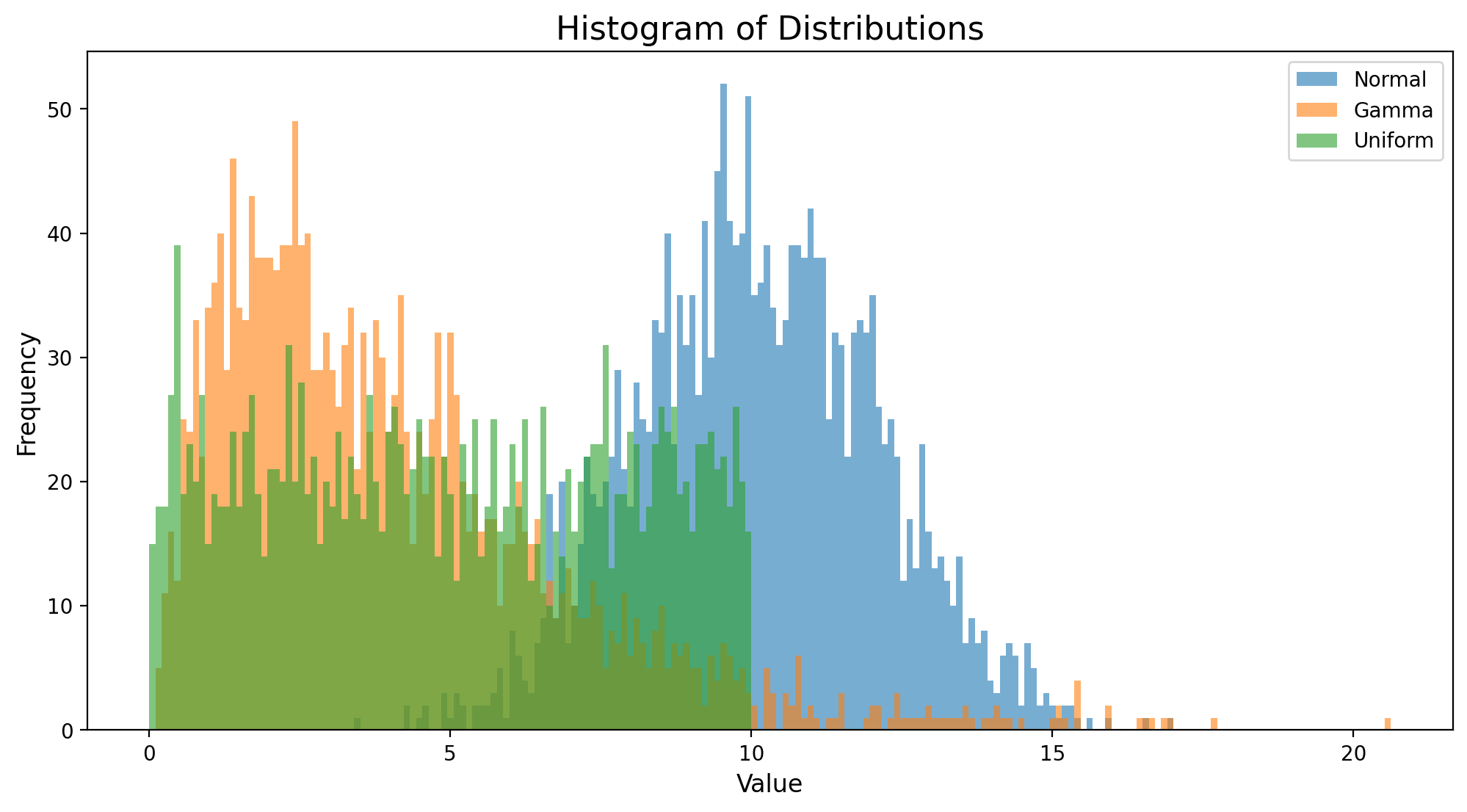
normal = pd.Series(np.random.normal(loc =10, scale =2, size =2000)) # loc is mean, scale is standard deviationgamma = pd.Series(np.random.gamma(shape =2, scale =2, size =2000)) # shape is k, scale is thetauniform = pd.Series(np.random.uniform(low =0, high =10, size =2000)) # low is a, high is bdf = pd.DataFrame({'Normal': normal, 'Gamma': gamma, 'Uniform': uniform})df.head()
Normal
Gamma
Uniform
0
8.566490
4.439362
2.169578
1
10.946834
5.073406
0.512258
2
7.099340
1.638423
2.346859
3
11.799476
0.733187
2.480262
4
9.174528
4.601980
5.228461
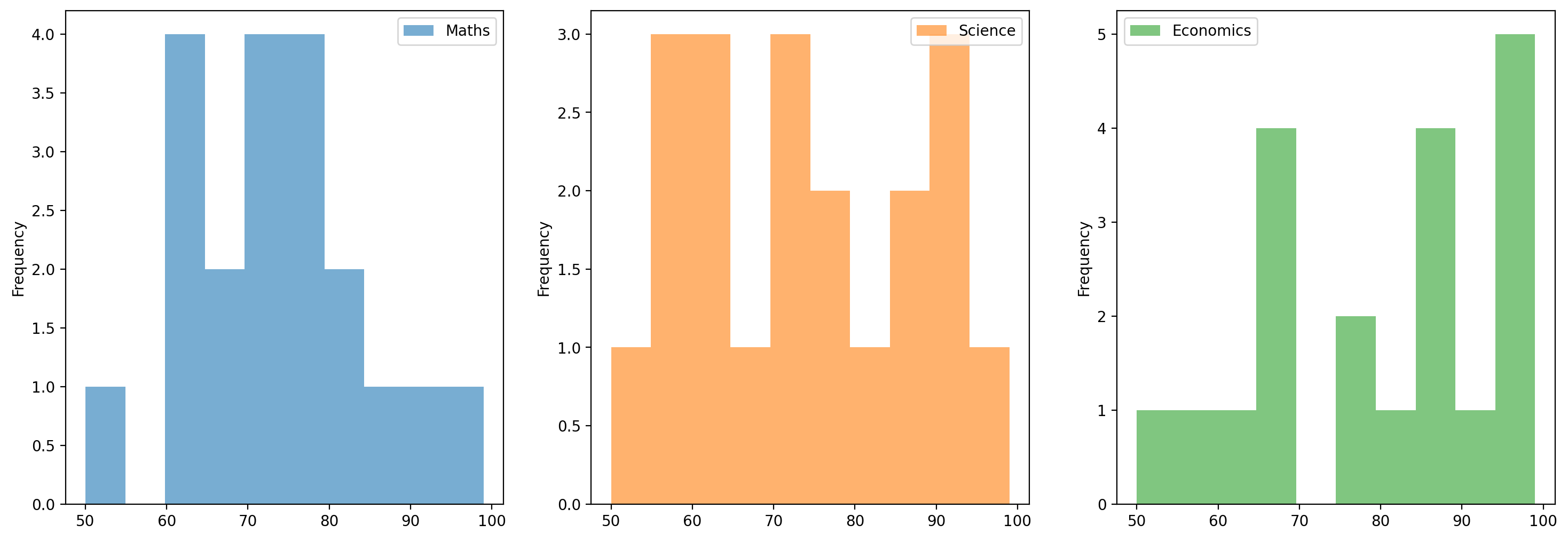
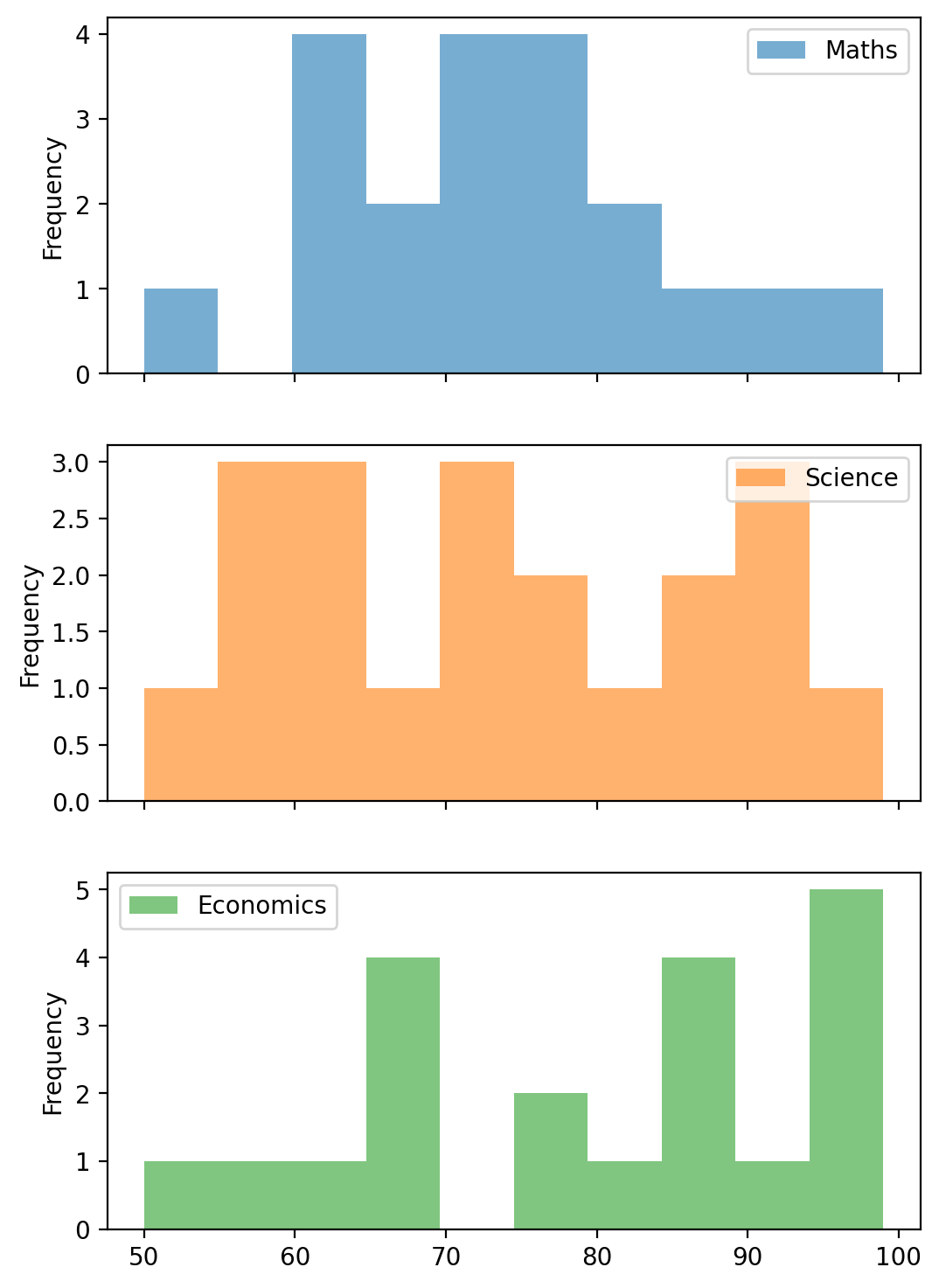
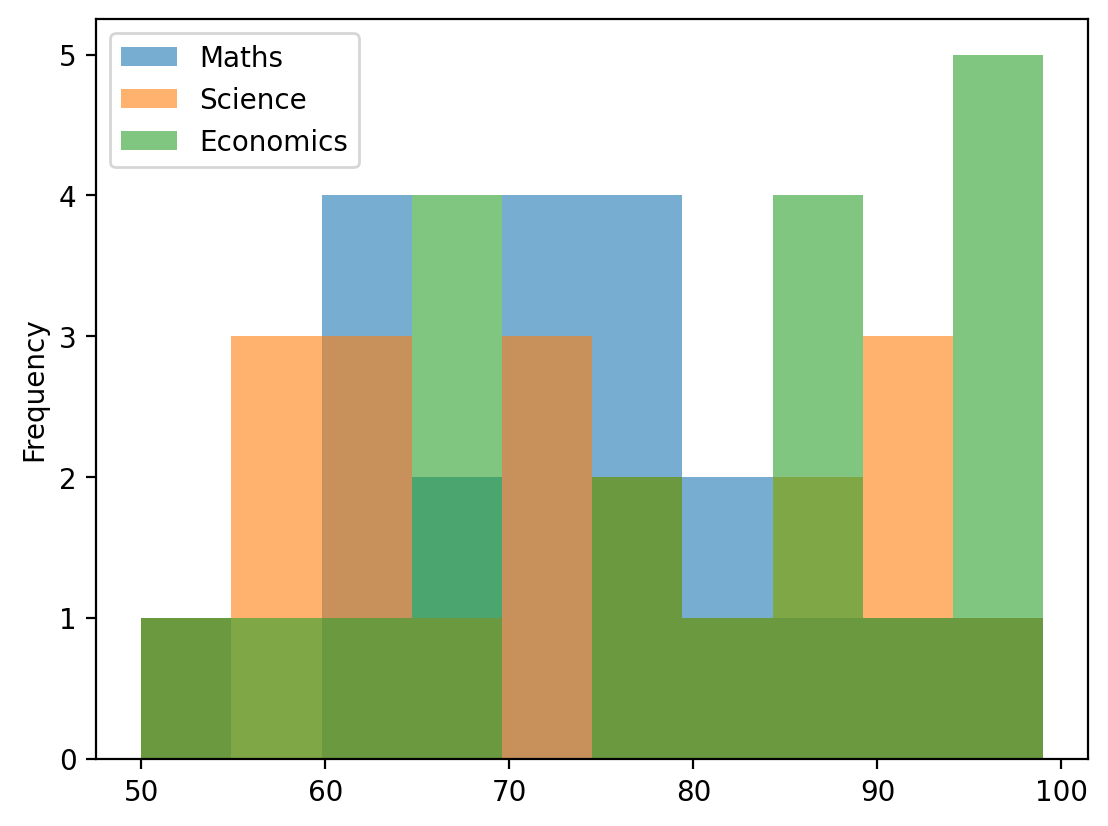
df.plot(kind='hist', bins=200, alpha=0.6, figsize=(12, 6))plt.title("Histogram of Distributions", fontsize=16)plt.xlabel("Value", fontsize=12)plt.ylabel("Frequency", fontsize=12)plt.show()
A Series is a one-dimensional labeled array. It can be created from a Python list or NumPy array, optionally providing a custom index. The index labels let you reference elements by name instead of by integer position.
DataFrame selection can occur by column name, row label/index name (.loc), or row position/numpy-array like indexing (.iloc). Boolean masks also apply.
Select column 'Y':
a 0.280775
b 0.931498
c 0.699822
d 0.014937
e 0.753386
Name: Y, dtype: float64
type(df2['Y'])
pandas.core.series.Series
print("\nSelect row 'c' using loc:")display(df2.loc['c'])
Select row 'c' using loc:
X 0.654491
Y 0.699822
Z 4.000000
Name: c, dtype: float64
print("\nSelect row at position 2 using iloc:")display(df2.iloc[2])
Select row at position 2 using iloc:
X 0.654491
Y 0.699822
Z 4.000000
Name: c, dtype: float64
print("\nBoolean mask: rows where Z > 5")mask = df2['Z'] >5display(df2[mask])
Boolean mask: rows where Z > 5
X
Y
Z
a
0.996172
0.280775
7
d
0.172585
0.014937
9
e
0.858278
0.753386
8
# loc to address by row, col "names" AND iloc to address by row, col "indices"print(df2.loc['c', 'Y'], df2.iloc[2, 1])
0.6998221861720456 0.6998221861720456
# Select multiple rowsprint("\nSelect rows 'a' and 'c':")display(df2.loc[['a', 'c']])
Select rows 'a' and 'c':
X
Y
Z
a
0.996172
0.280775
7
c
0.654491
0.699822
4
# Select multiple columnsprint("\nSelect columns 'X' and 'Z':")display(df2[['X', 'Z']])
Select columns 'X' and 'Z':
X
Z
a
0.610954
6
b
0.059152
3
c
0.483286
9
d
0.325020
8
e
0.059134
3
# Use loc notation to select multiple columnprint("\nSelect columns 'X' and 'Z' using loc:")#display(df2.loc[:, ['X', 'Z']])# Select rows 'b' and 'd' and columns 'X' and 'Z'rows_to_select = ['b', 'd']cols_to_select = ['X', 'Z']df2.loc[rows_to_select, cols_to_select]df2.loc['b':'d', 'Y':'Z']
Select columns 'X' and 'Z' using loc:
Y
Z
b
0.931498
4
c
0.699822
4
d
0.014937
9
# Select rows and columnsprint("\nSelect rows 'b' and 'd', columns 'Y' and 'Z':")display(df2.loc[['b', 'd'], ['Y', 'Z']])
Select rows 'b' and 'd', columns 'Y' and 'Z':
Y
Z
b
0.895559
3
d
0.573120
8
5. Merging & Joining Data
Pandas provides efficient ways to combine datasets:
pd.concat([df1, df2]): Stack DataFrames (row or column-wise). Preferred for simple stacking horizontally or vertically.
df1.append(df2): Similar to concat row-wise but less efficient since it involves creation of a new index.
pd.merge(df1, df2, on='key'): Database-style merges. Also left_on, right_on, left_index, right_index.
We can specify how to merge: ‘inner’, ‘outer’, ‘left’, ‘right’.
Concatenation of two dataframes with same columns - just stacks them vertically along with their indices
Let’s use seaborn’s ‘tips’ dataset to demonstrate merges.
tips = sns.load_dataset('tips') # Load the 'tips' dataset from seabornprint("'tips' dataset shape:", tips.shape) # Print the shape (rows, columns) of the datasetdisplay(tips.head()) # Show the first 5 rows of the dataset
'tips' dataset shape: (244, 7)
total_bill
tip
sex
smoker
day
time
size
0
16.99
1.01
Female
No
Sun
Dinner
2
1
10.34
1.66
Male
No
Sun
Dinner
3
2
21.01
3.50
Male
No
Sun
Dinner
3
3
23.68
3.31
Male
No
Sun
Dinner
2
4
24.59
3.61
Female
No
Sun
Dinner
4
is_vip = np.random.choice([True, False], size=len(tips)) # Randomly assign VIP status (True/False) to each rowcustomer_ids = np.arange(1, len(tips) +1) # Create unique customer IDs starting from 1np.random.shuffle(customer_ids) # Shuffle the customer IDs randomlyvip_info = pd.DataFrame({'customer_id': customer_ids, # Assign customer IDs'vip': is_vip # Assign the corresponding VIP status})print("VIP info:")display(vip_info) # Display the VIP information table
VIP info:
customer_id
vip
0
119
True
1
148
True
2
2
True
3
84
True
4
76
False
...
...
...
239
218
True
240
146
True
241
176
True
242
164
False
243
19
True
244 rows × 2 columns
tips_ext = tips.copy() # Create a copy of the original 'tips' datasetnew_customer_ids = np.arange(1, len(tips) +1) # Generate new unique customer IDsnp.random.shuffle(new_customer_ids) # Shuffle the customer IDs randomlytips_ext['customer_id'] = new_customer_ids # Add the shuffled customer IDs as a new columnprint("Extended tips:")display(tips_ext) # Show the extended dataset
Extended tips:
total_bill
tip
sex
smoker
day
time
size
customer_id
0
16.99
1.01
Female
No
Sun
Dinner
2
32
1
10.34
1.66
Male
No
Sun
Dinner
3
22
2
21.01
3.50
Male
No
Sun
Dinner
3
136
3
23.68
3.31
Male
No
Sun
Dinner
2
137
4
24.59
3.61
Female
No
Sun
Dinner
4
156
...
...
...
...
...
...
...
...
...
239
29.03
5.92
Male
No
Sat
Dinner
3
228
240
27.18
2.00
Female
Yes
Sat
Dinner
2
84
241
22.67
2.00
Male
Yes
Sat
Dinner
2
219
242
17.82
1.75
Male
No
Sat
Dinner
2
241
243
18.78
3.00
Female
No
Thur
Dinner
2
209
244 rows × 8 columns
merged = pd.merge(tips_ext, vip_info, on='customer_id', how='left') # Merge the datasets using 'customer_id'print("Merged Data:")display(merged) # Display the merged dataset
Merged Data:
total_bill
tip
sex
smoker
day
time
size
customer_id
vip
0
16.99
1.01
Female
No
Sun
Dinner
2
32
True
1
10.34
1.66
Male
No
Sun
Dinner
3
22
False
2
21.01
3.50
Male
No
Sun
Dinner
3
136
True
3
23.68
3.31
Male
No
Sun
Dinner
2
137
True
4
24.59
3.61
Female
No
Sun
Dinner
4
156
False
...
...
...
...
...
...
...
...
...
...
239
29.03
5.92
Male
No
Sat
Dinner
3
228
False
240
27.18
2.00
Female
Yes
Sat
Dinner
2
84
True
241
22.67
2.00
Male
Yes
Sat
Dinner
2
219
False
242
17.82
1.75
Male
No
Sat
Dinner
2
241
True
243
18.78
3.00
Female
No
Thur
Dinner
2
209
True
244 rows × 9 columns
6. GroupBy & Aggregation
The GroupBy abstraction splits data into groups, applies operations, then combines results. Common for summarizing numeric columns by categories.
Example with tips data
We’ll group by day of the week and compute average tip, total tip, etc.
tips.loc[:, 'day']
0 Sun
1 Sun
2 Sun
3 Sun
4 Sun
...
239 Sat
240 Sat
241 Sat
242 Sat
243 Thur
Name: day, Length: 244, dtype: category
Categories (4, object): ['Thur', 'Fri', 'Sat', 'Sun']
tips['day'].value_counts()
day
Sat 87
Sun 76
Thur 62
Fri 19
Name: count, dtype: int64
# Unique values in the 'day' columnunique_days = tips['day'].unique()print("Unique days:", unique_days)
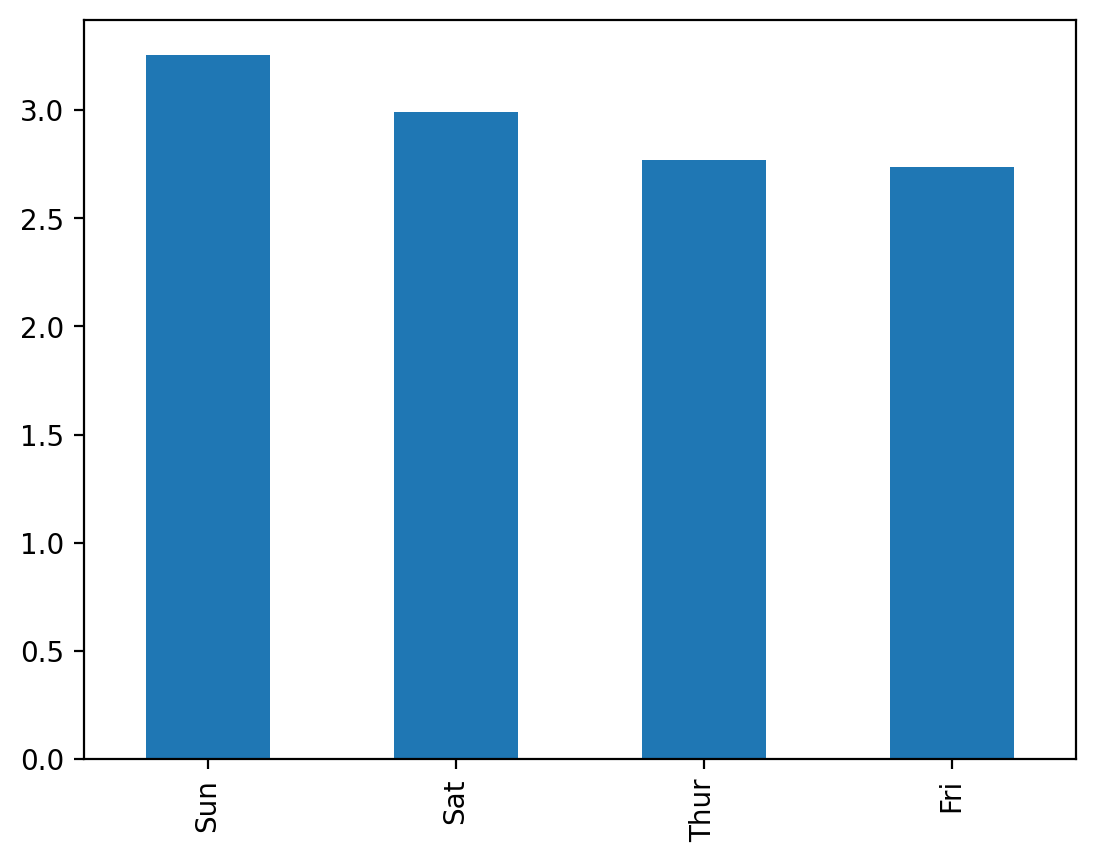
day
Thur 2.771452
Fri 2.734737
Sat 2.993103
Sun 3.255132
Name: tip, dtype: float64
# Group tips by 'day' column, aggregate 'tip' in different waysgrouped = tips.groupby('day', observed=True)['tip']print("Mean tip by day:")display(grouped.mean())print("\nMultiple Aggregations (count, sum, mean):")display(grouped.agg(['count','sum','mean','std']))
Mean tip by day:
day
Thur 2.771452
Fri 2.734737
Sat 2.993103
Sun 3.255132
Name: tip, dtype: float64
Multiple Aggregations (count, sum, mean):
count
sum
mean
std
day
Thur
62
171.83
2.771452
1.240223
Fri
19
51.96
2.734737
1.019577
Sat
87
260.40
2.993103
1.631014
Sun
76
247.39
3.255132
1.234880
Multiple Grouping Keys: We can group by multiple columns, e.g. day and time (Lunch/Dinner).
We can also specify margins (margins=True) to get row/column totals.
# Pivot example using 'tips'pivot_tips = tips.pivot_table( values='tip', index='day', columns='time', aggfunc='mean', margins=True, observed=True)pivot_tips
time
Lunch
Dinner
All
day
Thur
2.767705
3.000000
2.771452
Fri
2.382857
2.940000
2.734737
Sat
NaN
2.993103
2.993103
Sun
NaN
3.255132
3.255132
All
2.728088
3.102670
2.998279
# handling nan values by filling them with 0tips_fillna = pivot_tips.fillna(0, inplace=False)# handling nan values by dropping themtips_dropna = pivot_tips.dropna()display(tips_fillna)display(tips_dropna)
time
Lunch
Dinner
All
day
Thur
2.767705
3.000000
2.771452
Fri
2.382857
2.940000
2.734737
Sat
0.000000
2.993103
2.993103
Sun
0.000000
3.255132
3.255132
All
2.728088
3.102670
2.998279
time
Lunch
Dinner
All
day
Thur
2.767705
3.00000
2.771452
Fri
2.382857
2.94000
2.734737
All
2.728088
3.10267
2.998279
8. String Operations
Pandas offers vectorized string methods under str. They handle missing data gracefully and allow powerful regex usage.
Key methods: - case changes: .str.lower(), .str.upper(), .str.title(), etc. - trimming: .str.strip(), .str.rstrip(), etc. - Regex: .str.contains(), .str.extract(), .str.replace(). - split: .str.split(), .str.get(), etc.